






作者:白钰 阿里云高级算法专家/消费者终端智能部算法负责人
这次向大家分享的工作是笔者所负责团队在国际人工智能多媒体顶会 ACM MM 2022 (CCF-A)发表的文章 “Multi-Level Spatiotemporal Network for Video Summarization”,该文提出了一种用于视频摘要的多层时空网络,在视频摘要领域实现了全球领先的研究探索。基于我们团队在工业级推荐系统方面的研究积累,我们成功地在阿里云产业大规模视频摘要场景实践中解决了一个视频摘要领域的重要问题,推动了该领域的发展。

从宏观上讲,视频摘要任务与搜索引擎和推荐系统具有共同的核心目标,即有效地对候选内容进行评分和排序,甚至为了实现性能与效果的平衡,架构上也同样可将其分解为召回、粗排和精排几个阶段。然而,视频摘要任务也有其特定的性质,特别是候选内容的时序依赖性以及基于评分的摘要生成算法。本文探讨了视频摘要任务的挑战,重点介绍了 MLSN 模型的技术细节和在阿里云的实践经验,以帮助读者更好地理解 MLSN 的设计思想。
一、背景介绍
随着 4/5G 等通信技术的发展和泛在视频采集设备的普及,每时每刻都有大量的视频内容被生产出来,从而为各行各业中出现的大量视频内容检索需求提供了可能性。其中一个最典型的场景即是帮助消费者有效地查找自己感兴趣的视频片段,这类应用的井喷式发展也对自动化视频摘要系统提出了更高的要求。然而,现有的主流的视频摘要数据集以短镜头视频为主,这导致针对长镜头视频内容设计的摘要算法研究极少。
为此,本文提出了一种能够自适应不同镜头长度的多层时空网络(Multi-Level Spatiotemporal Network,MLSN),以解决既有方案无法有效地处理以产业中包含大量冗余信息长镜头数据为主要难点的视频摘要问题。该网络由 Multi-Level Feature Representations(MLFR)和 Local Relative Loss(LRL)组成,MLFR 模块可以灵活地捕捉和容纳不同镜头时长下视频的各时空粒度语义信息,而 LRL 则利用每个片段帧间的局部相对偏序关系,捕获具有高辨别力的特征。MLSN 具有镜头时长自适应的系统架构,极大地提升了长时空跨度帧的可比性,并提出了更优秀的精细粒度选择算法(Diverse Key Fragments Selection,DKFS),这些优秀特性使得该算法被广泛应用于阿里云的主要业务并取得了显著的效果。
总的来说,Multi-Level Spatiotemporal Network(多层时空网络,MLSN)具有以下几个出色特点:
-
具有镜头时长自适应的网络结构。本研究中提出的网络能够有效对不同长度镜头的视频摘要任务进行处理,该模型由多层时空特征表征模块和多层特征融合模块组成。它可以灵活地捕捉和容纳不同镜头时长下视频的各时空粒度语义信息,从而实现自适应不同镜头长度的摘要任务。
-
极大地提升长时空跨度帧的可比性。本研究提出了局部相对偏序损失函数(LRL),这一损失函数利用偏序关系的传递性和相邻帧间的语义信息更具时空连续性进而更具可比性的特点,引入局部相对偏序关系作为监督信号,改进了与现有公开方法只比较没有局部时空关系的帧的做法,大大提高了长时间跨度帧的可比性从而提高排序效果。
-
更优秀的精细粒度选择算法。本研究提出了名为基于多样性的关键片段选择算法(DKFS)的摘要生成算法,该算法在每个镜头中,会选择不同的关键片段作为视频摘要的候选片段,而不是像基于动态规划的算法一样将具有大量冗余信息的整个镜头作为候选片段,在抑制冗余信息时取得了优异的表现,解决了长镜头视频摘要任务的难点。
二、既有方法的局限性
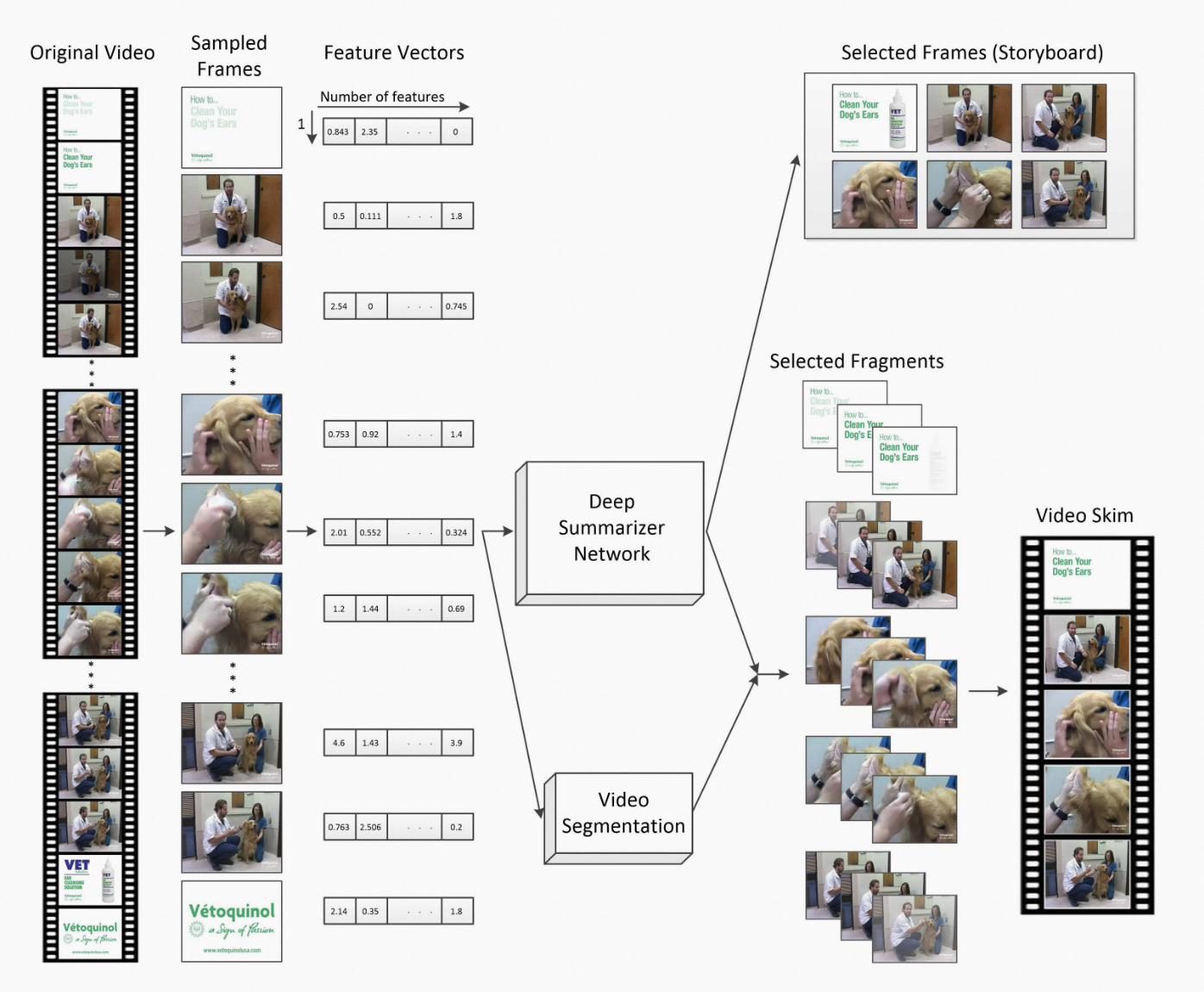
如上图 Apostolidis 等人在 [Proceedings of the IEEE 109.11 (2021): 1838-1863] 综述文章所示,视频摘要任务主要由打分模块和片段优选模块组成:现有主流方案基于深度模型对视频关键帧进行打分,然后利用动态规划算法基于融合分数进行片段优选。我们在实践中发现现有的公开研究满足不了所有视频摘要任务的需求,例如产业长镜头视频。因此,本文将分析现有视频摘要算法在产业长镜头视频下的局限性以及开展本文工作的必要性。
2.1 特征表征结构单调
当前视频摘要研究主要以 TVSum 和 SumMe 这两个主流数据集来评估算法的先进性,然而这些数据集中视频镜头的平均时长只有 5-6 秒,这会导致设计的视频摘要算法的性能受到限制,从而影响其适用范围。受到时空容量的限制的间接影响,大多数研究工作倾向于仅考虑单个帧、镜头或片段的特征表示,而忽略了它们之间的时空关联。
2.2 标注方法存在局限
目前视频摘要任务的标注方法存在各种问题,标注者的主观性会导致他们之间的评分标准(量纲)存在不一致性,甚至即使是同一个标注者在同一个视频的不同时段也会存在差异。这将使得标注获得的绝对得分的监督效果受到影响。考虑到人类信息处理能力的局限性,这种误差会随着视频镜头时长的增加,同时也会随着镜头信息稀疏性的增加而变得更加明显。
2.3 视频优选粒度过粗
目前主流片段选择算法为动态规划算法,其使用整个镜头作为候选片段。如果将这种算法直接应用于存在大量冗余信息的长视频镜头视频摘要场景,将会导致摘要结果中出现大量冗余信息,完全不能满足产业的真实需求。
三、MLSN 模型
我们提出了一个 MLSN 模型,它可以有效地解决面向长镜头视频数据摘要问题,通过多层时空特征表征和局部相对偏序关系损失函数来保留更多的信息。此外,我们还提出了 DKFS 算法,它可以更好地解决动态规划算法无法解决的、具有高冗余信息的长镜头视频优选问题。
3.1 整体设计
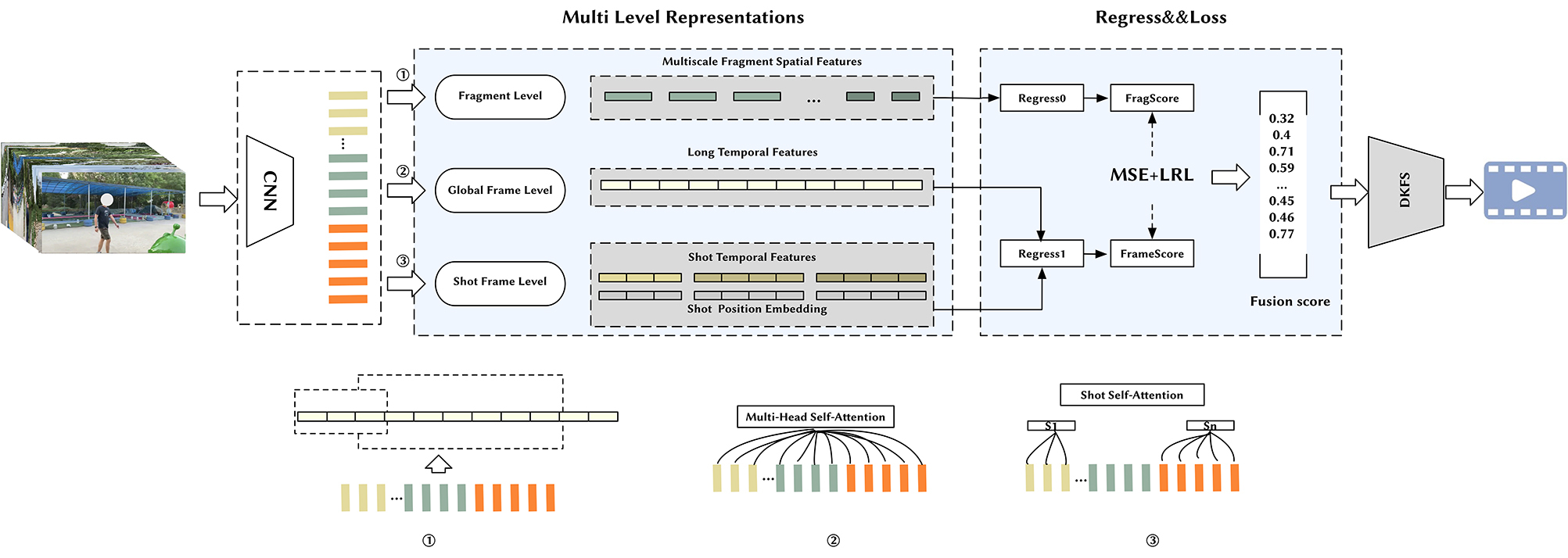
在本文中,我们提出了一种有效的多层时空视频摘要网络(MLSN),该模型利用已经预训练的深度卷积神经网络(CNN)来提取视频帧的特征,并利用帧、片段及镜头级别的特征表征,构建出 FragScore 和 FrameScore,同时将视频的全局帧级特征和镜头级特征作为输入,提供给相应的非线性回归层,以预测每帧的得分。类似地,我们还将片段级特征提供给其非线性回归网络,以更准确地预测每个片段的分数。此外,我们提出了一种局部相对偏序关系损失(LRL)函数来监督帧之间的局部相对偏序关系,以及 DKFS 算法,作为视频摘要片段优选策略,以处理长镜头视频。为此,我们提出的方法不仅能够有效地提升视频摘要的精度,而且能够较好地在不同任务上进行自适应调节,成为视频摘要领域中具有较大潜力的一种可行解决方案。
下面,我们将详细阐述每个部分的工作。
3.2 多层时空特征表征(MLRF)
研究过程中我们洞察到人类在总结和剪辑一段视频时,通常会观看整个视频,然后回忆视频中的每个画面、片段和镜头,并根据各个帧、片段和镜头的吸引力以及其在时空跨度下的内在联系来进行挑选。受此启发,我们提出了一个深度网络来模拟这样一个人工过程,面向镜头、片段和帧三个维度,设计一个多层特征表征模块,并通过融合模块将其转换为视频摘要的重要性分数。该深度学习网络结构可以帮助模型发现不同粒度下内容的跨时空联系,有效增强生成的摘要视频的语义。其多层时空特征表征构建也建立在帧级、片段级和镜头级三个不同层次上,以实现更高效的跨时空联系发现。
3.2.1 帧级特征
为了提取帧序列的空间特征,我们使用在 ImageNet 上预训练的 GoogLeNet 的 Pool5 层的输出。需要指出的是,我们在这里仅仅使用 GoogLeNet 是为了与先前的方法公平比较。为了建模具有长时间跨度的全局帧之间的时间关系,我们将 GoogLeNet 产生的输出传送到一个 multi-head self-attention 编码层中,作为全局帧向量。
3.2.2 片段级特征
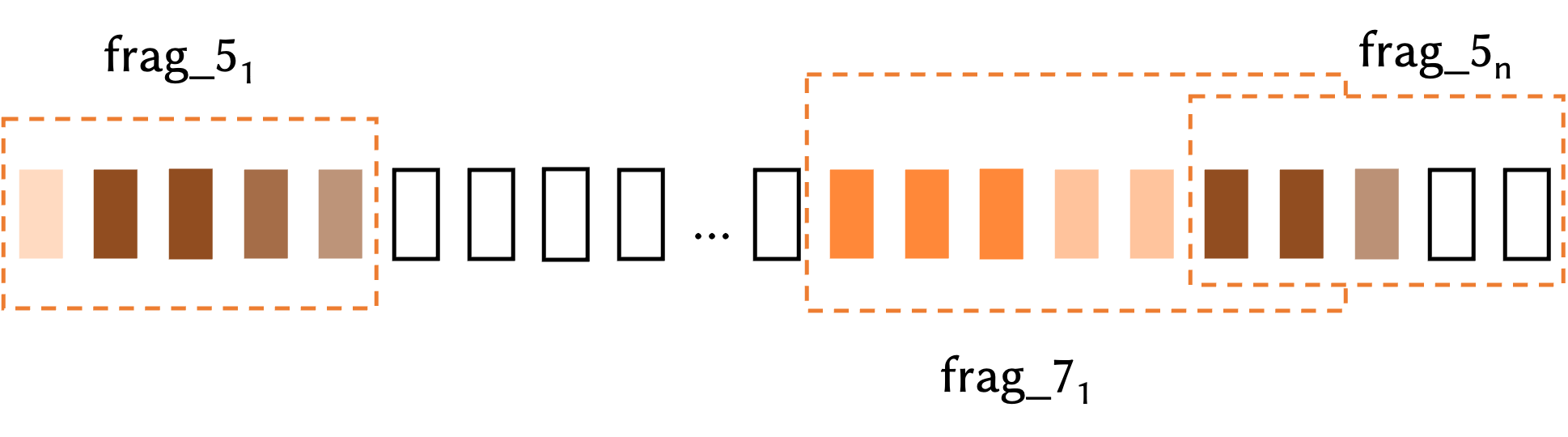
片段信息的表征通过帧的集合生成,本文采用具有特定窗口大小和跨度的滑动窗口在所有帧上滑动,以此生成片段信息,如上图所示,𝑓𝑟𝑎𝑔_5𝑖 表示窗口大小为5的第i个片段,而 𝑓𝑟𝑎𝑔_7𝑖 表示窗口大小为 7 的第 i 个片段,其中 stride 和 window size 是该模块的超参数。生成片段级特征表示的过程中,应当设置合适的窗口大小作为超参数。
具体来说,片段级特征表征采用 average pooling 池化帧级特征生成,以此确保整合片段的整体特征,同时也保证片段级特征的维度与帧级特征保持一致。考虑一个视频包含 u 个片段的情况,该模块的输出是一系列 1024 维向量,其总集合大小为 u。采用片段级特征,该方法可以学习不同时空粒度的特征,进而构建视频片段之间的语义联系。
3.3.3 镜头级特征
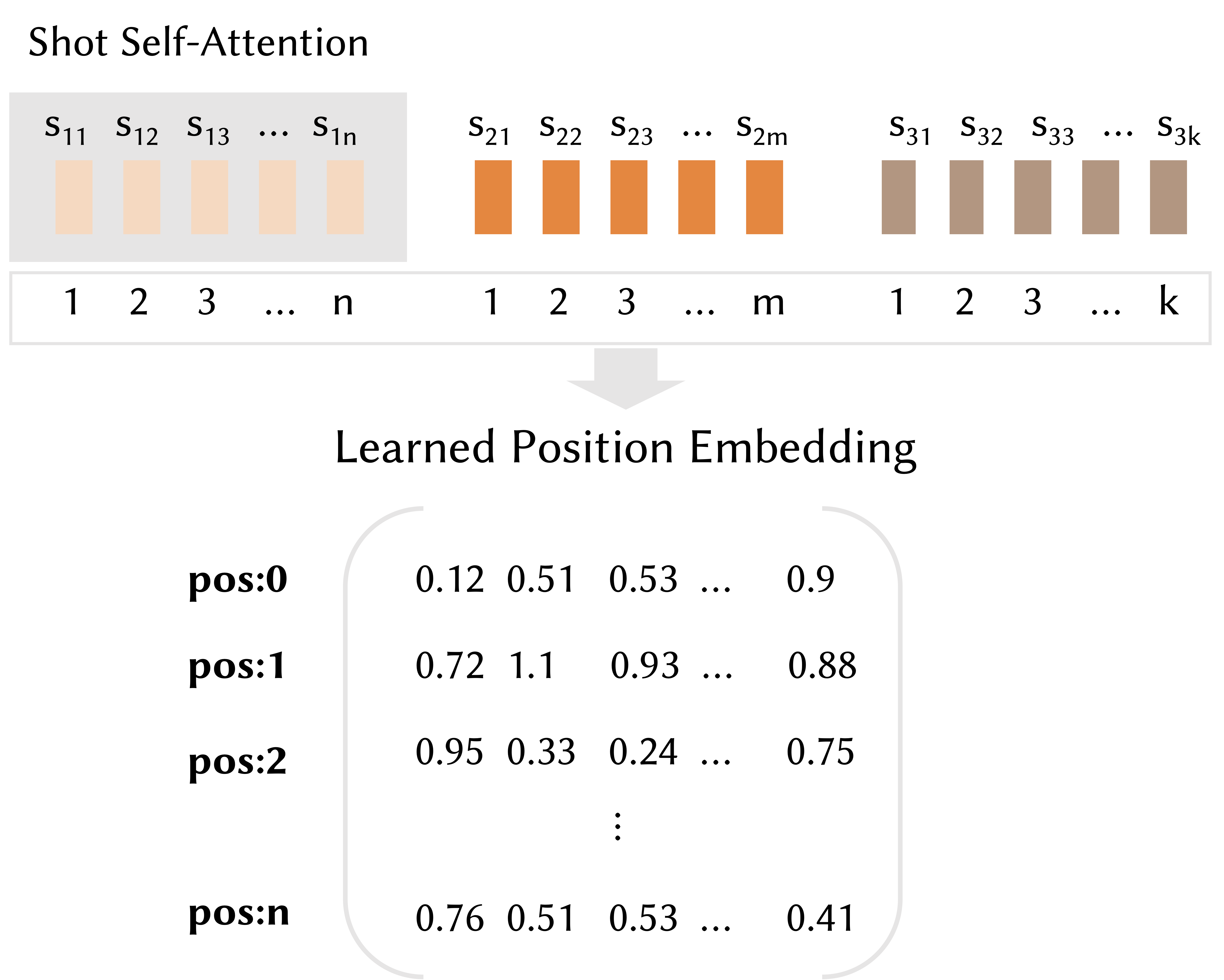
视频序列帧之间的相关性会随着时间距离的增加而衰减,从而导致基于全局注意力的权重也随之受到影响,本文提出了一种具有镜头内帧相对位置的自注意力机制,采用 shot self-attention with mask 和镜头级 learned position embedding 特征表征(如上图所示)。该设计可以使模型能够有效地识别到镜头内帧之间的时空关系,以及准确地捕捉跨度较长镜头之间的语义联系。
3.2 局部相对偏序关系损失函数(LRL)

在前文中我们曾提到,标注工作的主观性会导致标注者之间评分标准(量纲)存在不一致的现象,而且随着视频镜头时长的增长和其信息稀疏性的增加,这种误差将会变得更明显,从而对标注者所标注的帧重要性得分的监督效果产生极大影响。为此,本文提出了一种局部相对偏序关系损失 (LRL) 的新损失函数,它可以利用偏序关系的传递性和相邻帧间的语义信息更具时空连续性进而更具可比性的特点,引入局部偏序关系信号,来有效地监督模型学习长时间宽度帧之间的偏序关系。
具体来说,本文基于 ground truth 在各窗口内的 gap,提出了一种窗口权重分配机制,可以使得模型根据具体情况对片段进行不同程度的关注,从而产生对帧之间相对差异进行建模的能力。该机制使得我们的方法能够更有效地捕捉和学习出关键信息与冗余信息之间的差异。
形式上,我们保留了全局损失函数 MSE,以保护跨时空的偏序关系信号。
并利用 ListNet 保留局部偏序信息的特点,构建了基于局部偏序关系的损失函数 LRL。
如下可以看到,本文选择采用均方损失和局部相对损失构成的综合损失作为优化目标,以获得更高的灵活性和鲁棒性。
3.3 基于多样性的关键片段选择算法(DKFS)

本文探讨了面向产业应用的视频摘要优选算法。目前主流的视频摘要方法均采用基于动态规划的优选算法,但在产业应用中存在特殊情况,例如视频镜头较长的情况下,视频摘要优选任务的目标变成了关键片段的选择任务,而不是关键镜头的选择任务,同时产业应用对视频摘要内容多样性要求更高,从而导致传统的动态规划算法难以有效地解决此类问题。为此,本文提出了 DKFS 视频摘要生成算法,实现了关键片段优选任务,并在产业应用中得到了有效的实践验证。
具体来说,本文使用每个帧的平均得分作为镜头的得分,并根据得分排序。当未达到目标摘要时长时,我们通过滑动窗口取出得分最高的片段来保证最终摘要的多样性。接着,根据每个镜头中剩余帧的平均得分重新计算和排序每个镜头,并从 top1 镜头中通过滑动窗口选择片段加入摘要,依此循环,直至达到目标摘要时长,以确保视频摘要结果的吸引力。
四、模型效果评估

为了评估本文提出的 MLSN 模型性能,我们使用两个公共基准数据集(TVSum和SumMe)以及产业自研数据集,并将其与其他主流 SOTA 模型(包括dppLSTM、SASUM、ActionRanking、H-RNN、M-AVS、DR-DSN、CSNet、H-MAN、VASNet、SMLD、SMN、DASP、MAVS 及 DSNet等)进行比较。为了保证对比的公平性,本实验使用动态规划算法生成视频摘要。
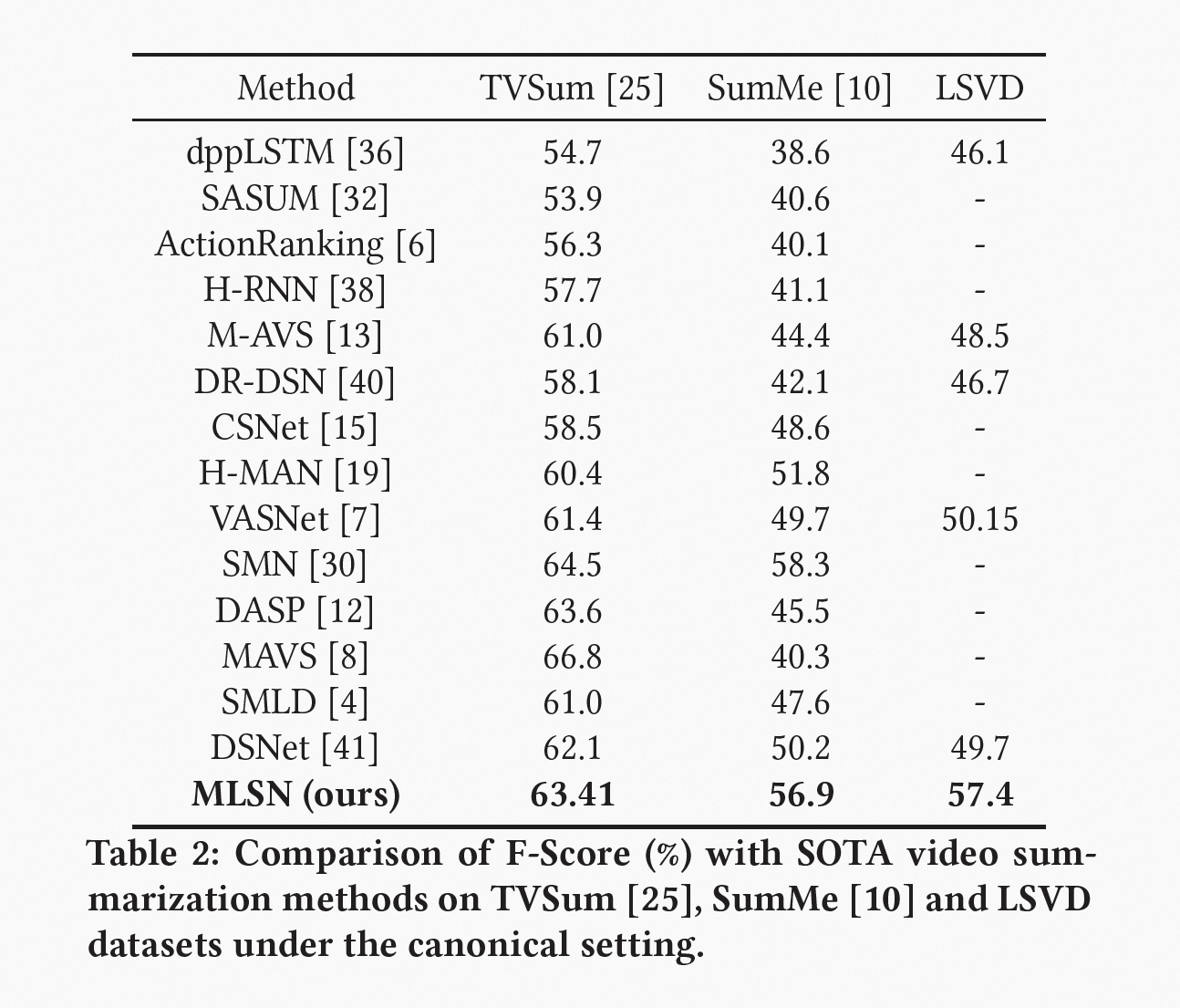
通过表 2 的结果可知,本文提出的 MLSN 模型在 TVSum 和 SumMe 数据集上都有出色的表现:在TVSum上,它与 DASP 和 MAVS 处于同一水平,而在 SumMe 上,明显优于它们。同时,与应用了注意力机制的 M-AVS、VASNet、DSNet 相比,MLSN 在 TVSum 和 SumMe 均取得了更出色的结果。
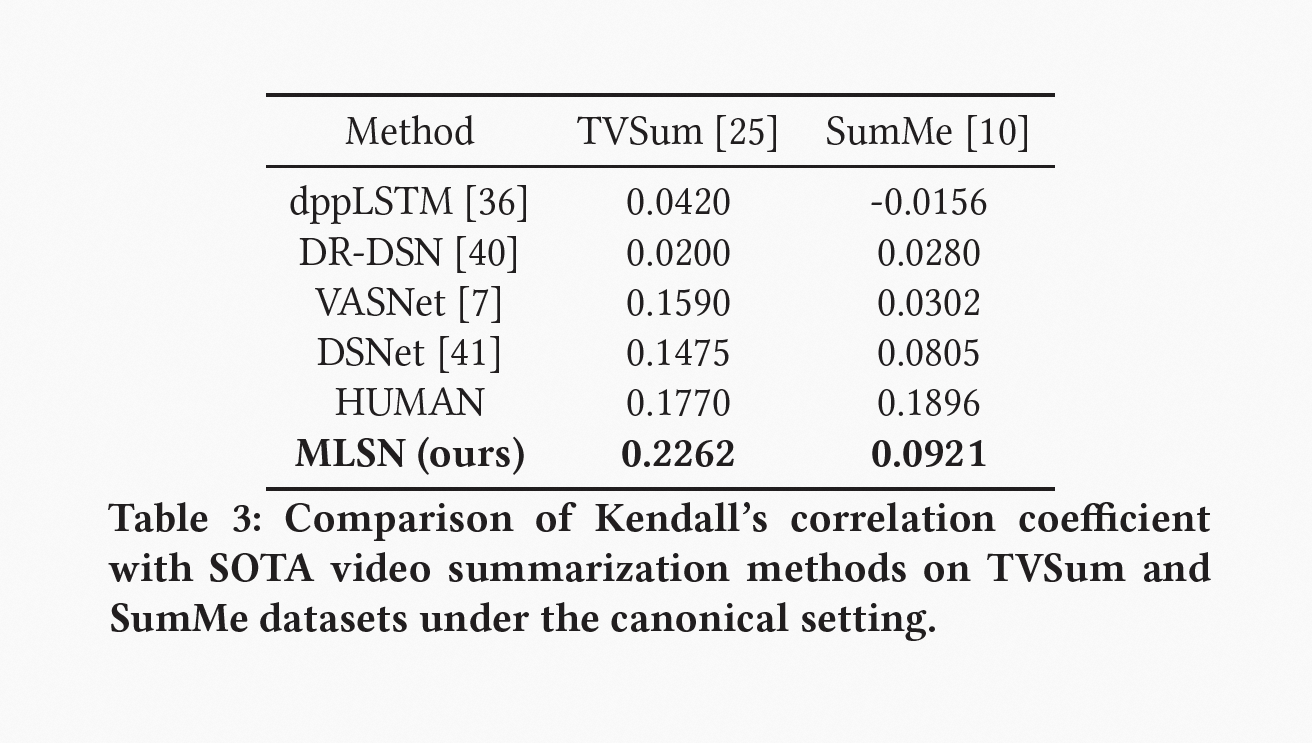
本文还通过 Kendall 相关系数对 MLSN 方法的性能进行评估,实验结果表明,它在 TVSum 和 SumMe 上的表现优于 dppLSTM、DR-DSN、VASNET 和 DSNET,在 TVSum 上的表现甚至超过 HUMAN。
此外,为了验证所提及的公开方法在实际产业长镜头视频应用场景中发挥出的效果,我们进行了一组实验, 以 dppLSTM、MAVS、DR-DSN、VASNet、DSNet 等方法中公布的原始代码为基础,采用相同的数据分割、训练批大小以及评估方法,使用 DKFS 算法生成最终视频摘要(细节见表2)。结果表明,MLSN 在 LSVD 数据集中取得出色的表现,其 F1 Score 57.4% 显著优于其它方法,相比最接近的竞争对手 VASNet,高出 7%,这些优势源自于对不同粒度的时空特征关系的引入和局部偏序关系的监督。
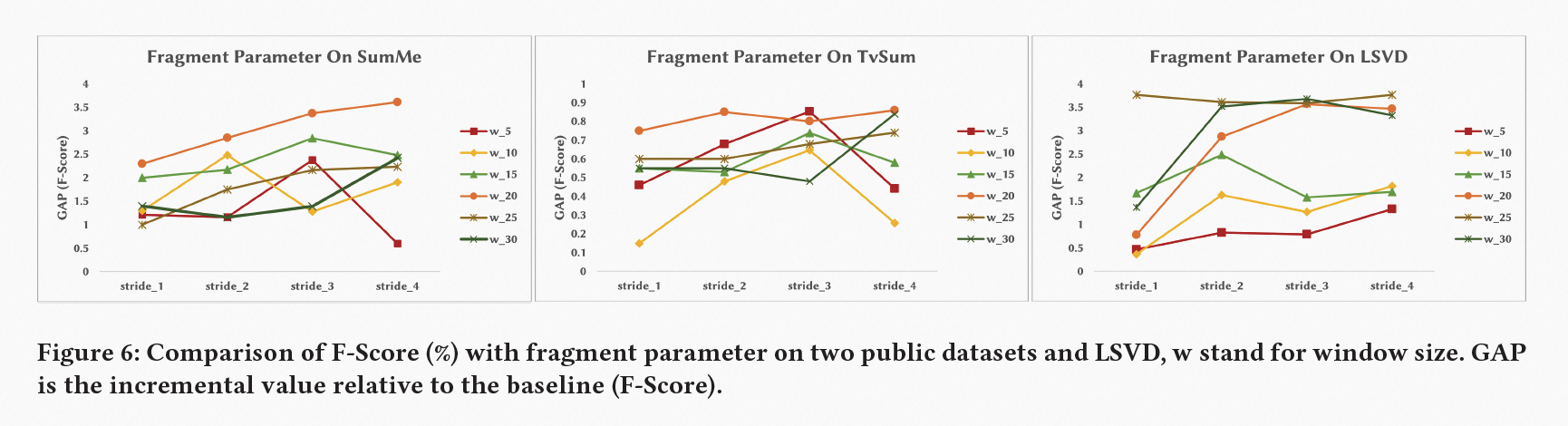
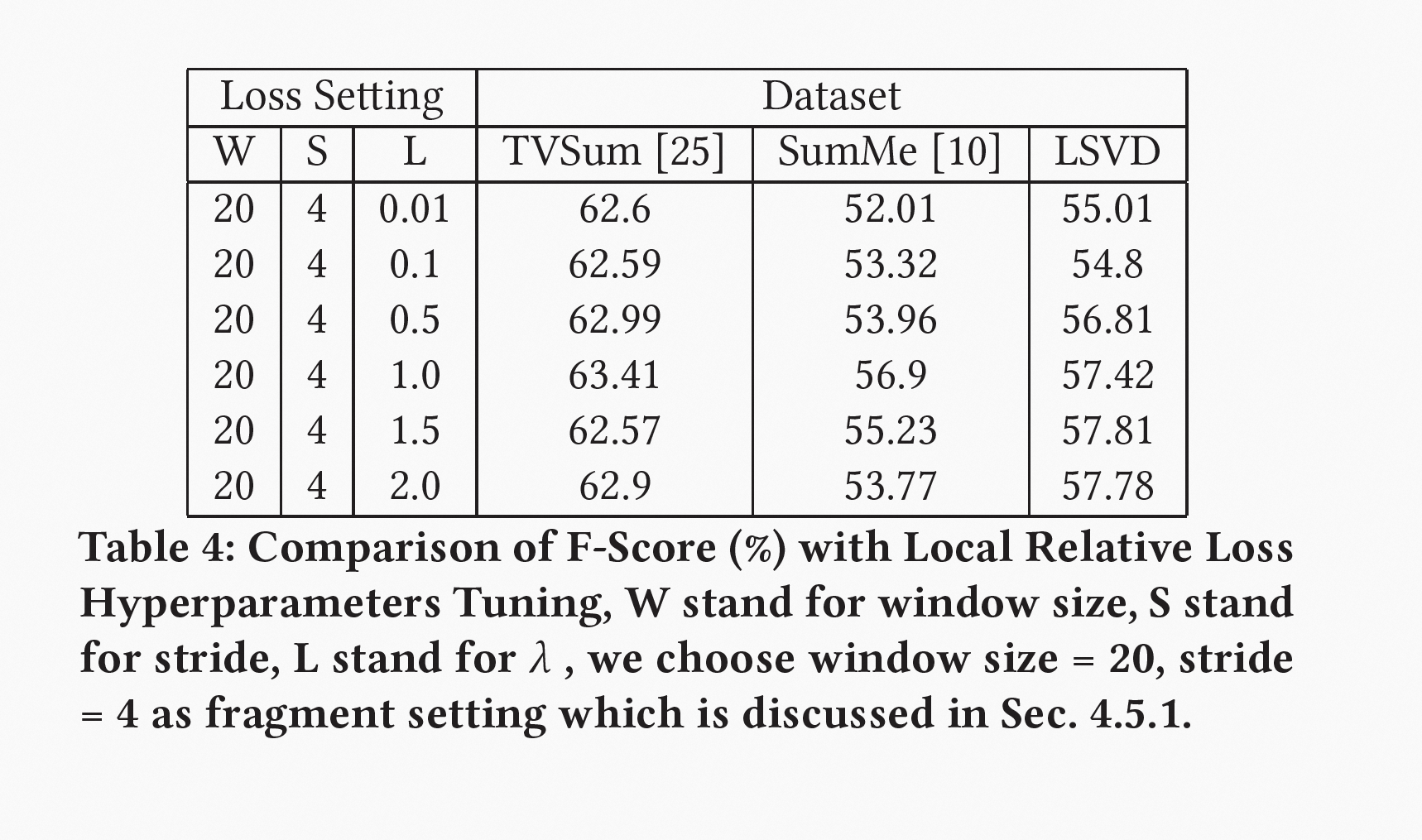
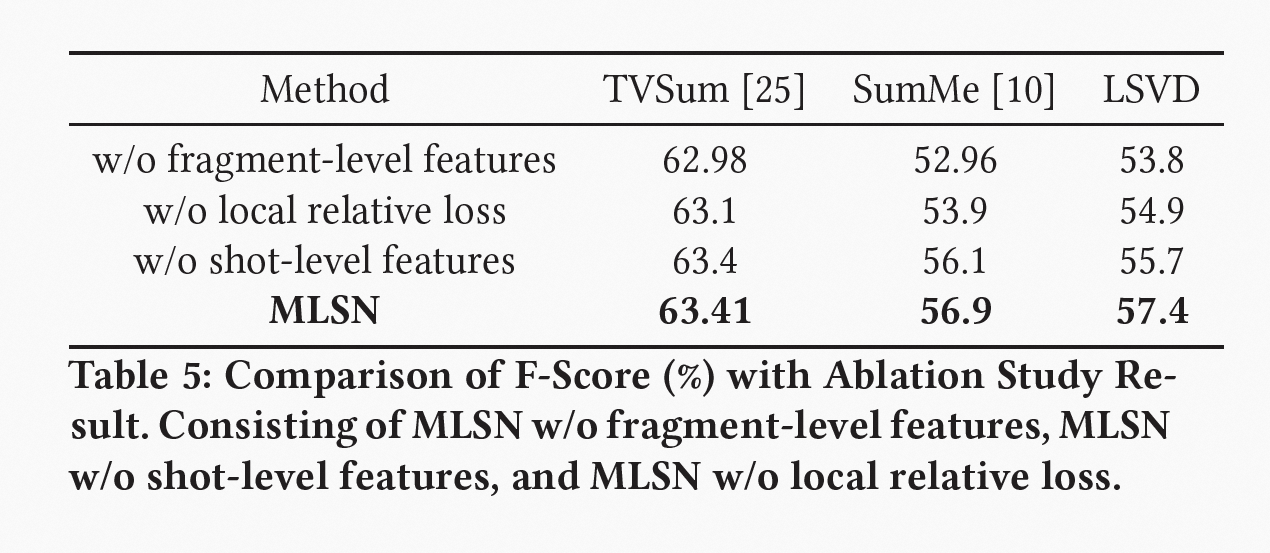
如上图所示,本文在固定配置下进行了五次随机数据拆分的平均性能消融实验,实验结果证实了片段级特征的缺失会对 F-Score(%) 产生负面作用,帧间的时空关系利用也对模型性能的提升提供了帮助。在 TVSum 和 SumMe 数据集上,镜头级特征缺失造成的影响较小,这也与我们的预期相符,因为短镜头视频中,片段级特征可以弥补镜头级信息的不足,这也侧面证明了 MLSN 在不同时长镜头数据下的自适应能力。
通过实验结果可以得出结论:结合帧级特征、片段级特征和镜头级特征对视频进行建模可以取得更佳性能,而基于偏序关系的部分相对损失函数也能在不同数据集上取得可靠的积极结果,这证明了我们提出的方法的有效性和可行性。
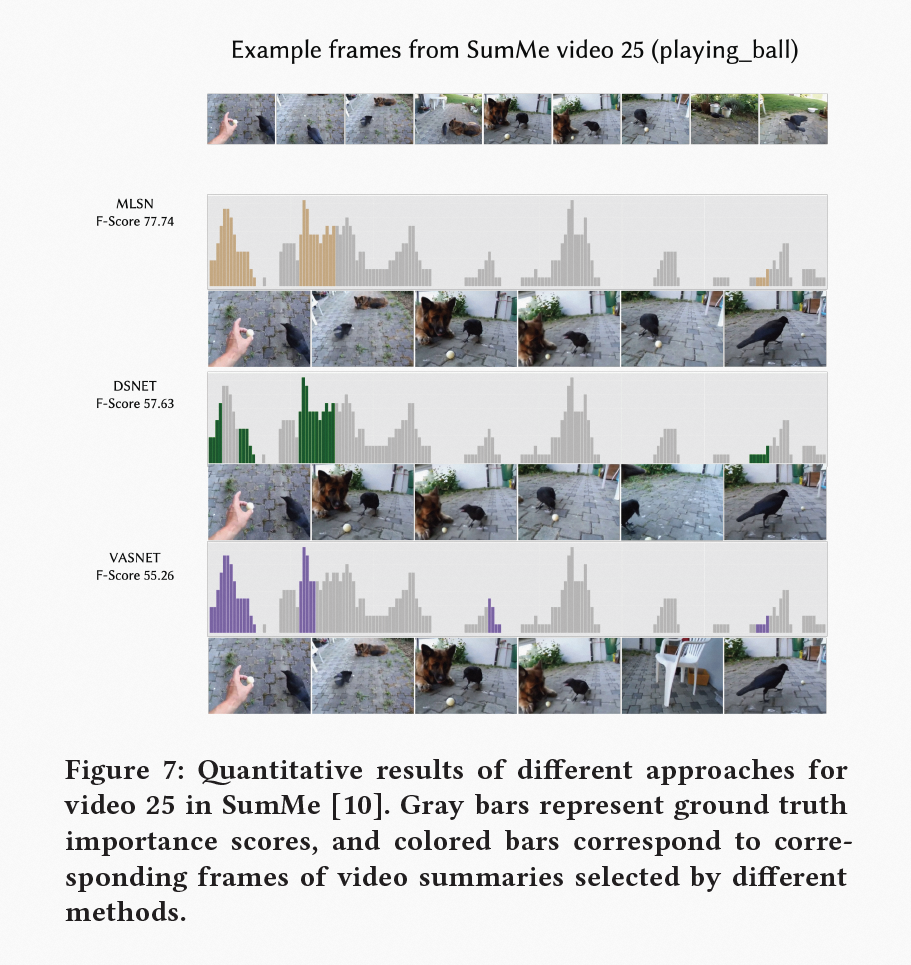
如上图所示,为了这直观地反映出 MLSN 模型在摘要算法方面的特色和优势,我们提供一组公开数据集中的实验案例,其中,灰色条代表从视频 “playing_ball“(SumMe)中提取的帧重要性(ground truth)的得分,而黄色、绿色和紫色分别反映了 MLSN 模型、DSNet 和 VASNet 在该视频上的打分结果,经比较可以发现,MLSN 模型更加精确地捕捉到具有丰富局部细节和语义信息更连贯的帧,比如与狗互动的鸟和啄球的鸟,而 DSNet 和 VASNet 在此方面表现略逊一筹。
五、总结
本文详细介绍了阿里云视频摘要 SOTA 模型 MLSN,该模型通过提取帧级特征、片段级特征和镜头级特征等多层特征,从而对多时空粒度进行特征表征,并引入局部相对偏序损失函数,来挑选出视频中的局部高质量帧。此外,本文还提出了 DKFS 摘要生成算法,来满足行业的长镜头以及多样性的需求。实验结果表明,该模型在 TVSum 和 SumMe 等标准数据集上取得了优异的性能,同时在阿里云的产业应用中取得了显著的效果。



















 912
912

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









