







通常一个Xml映射文件,都会写一个Dao接口与之对应,请问,这个Dao接口的工作原理是什么?Dao接口里的方法,参数不同时,方法能重载吗?
Dao接口,就是人们常说的Mapper接口,接口的全限名,就是映射文件中的namespace的值,接口的方法名,就是映射文件中MappedStatement的id值,接口方法内的参数,就是传递给sql的参数。Mapper接口是没有实现类的,当调用接口方法时,接口全限名+方法名拼接字符串作为key值,可唯一定位一个MappedStatement
com.mybatis3.mappers.StudentDao.findStudentById,可以唯一找到namespace为com.mybatis3.mappers.StudentDao下面id = findStudentById的MappedStatement。在Mybatis中,每一个、、、标签,都会被解析为一个MappedStatement对象。
Dao接口里的方法,是不能重载的,因为是全限名+方法名的保存和寻找策略。
Dao接口的工作原理是JDK动态代理,Mybatis运行时会使用JDK动态代理为Dao接口生成代理proxy对象,代理对象proxy会拦截接口方法,转而执行MappedStatement所代表的sql,然后将sql执行结果返回。
mybatis的两种分页方式:RowBounds和PageHelper
Mybatis使用RowBounds对象进行分页,它是针对ResultSet结果集执行的内存分页,而非物理分页,可以在sql内直接书写带有物理分页的参数来完成物理分页功能,也可以使用分页插件来完成物理分页。
分页插件的基本原理是使用Mybatis提供的插件接口,实现自定义插件,在插件的拦截方法内拦截待执行的sql,然后重写sql,根据dialect方言,添加对应的物理分页语句和物理分页参数。
举例:select * from student,拦截sql后重写为:
select t.* from (select * from student)t limit 0,10
Mybatis是否支持延迟加载?如果支持,它的实现原理是什么?
Mybatis仅支持association关联对象和collection关联集合对象的延迟加载,association指的就是一对一,collection指的就是一对多查询。在Mybatis配置文件中,可以配置是否启用延迟加载lazyLoadingEnabled=true|false。
它的原理是,使用CGLIB创建目标对象的代理对象,当调用目标方法时,进入拦截器方法,比如调用a.getB().getName(),拦截器invoke()方法发现a.getB()是null值,那么就会单独发送事先保存好的查询关联B对象的sql,把B查询上来,然后调用a.setB(b),于是a的对象b属性就有值了,接着完成a.getB().getName()方法的调用。这就是延迟加载的基本原理。
简述Mybatis的插件运行原理,以及如何编写一个插件。
答:Mybatis仅可以编写针对ParameterHandler、ResultSetHandler、StatementHandler、Executor这4种接口的插件,Mybatis使用JDK的动态代理,为需要拦截的接口生成代理对象以实现接口方法拦截功能,每当执行这4种接口对象的方法时,就会进入拦截方法,具体就是InvocationHandler的invoke()方法,当然,只会拦截那些你指定需要拦截的方法。
Mybatis连接池

不使用数据库连接池时、正常使用数据库连接的情况下、当使用完毕之后我们就会调用其close()方法来关闭连接、避免资源浪费。但是当使用了数据库连接池之后、一个数据库连接被使用完之后就不再是调用其close方法关闭掉、而是应该将这个数据库连接放回连接池、那么我们就要拦截Connection.close()方法、将这个Connection放回连接池、而不是关闭。
使用动态代理的方式实现上述功能、PooledConnection实现了InvocationHandler接口、并提供了invoke方法的实现。
spring dataSource连接池的配置
公司的配置

MyBatis中井号与美元符号的区别
#{变量名}可以进行预编译、类型匹配等操作,#{变量名}会转化为jdbc的类型。
select * from tablename where id = #{id}
假设id的值为12,其中如果数据库字段id为字符型,那么#{id}表示的就是’12’,如果id为整型,那么id就是12,并且MyBatis会将上面SQL语句转化为jdbc的select * from tablename where id=?,把?参数设置为id的值。
${变量名}不进行数据类型匹配,直接替换。
select * from tablename where id = i d 如果字段 i d 为整型, s q l 语句就不会出错,但是如果字段 i d 为字符型,那么 s q l 语句应该写成 s e l e c t ∗ f r o m t a b l e w h e r e i d = ′ {id} 如果字段id为整型,sql语句就不会出错, 但是如果字段id为字符型, 那么sql语句应该写成select * from table where id = ' id如果字段id为整型,sql语句就不会出错,但是如果字段id为字符型,那么sql语句应该写成select∗fromtablewhereid=′{id}'。
#方式能够很大程度防止sql注入。
$方式无法方式sql注入。
$方式一般用于传入数据库对象,例如传入表名。
尽量多用#方式,少用$方式。
MyBatis 延迟加载(懒加载)
如果想要开始延迟加载功能,就需要在总配置文件 SqlMapConfig.xml 中配置 setting 属性,也就是将延迟加载 lazyLoadingEnable 的开关设置成 teue ,由于是按需加载,所以还需要将积极加载修改为消极加载,也就是将 aggressiveLazyLoading 改为 false

二级缓存

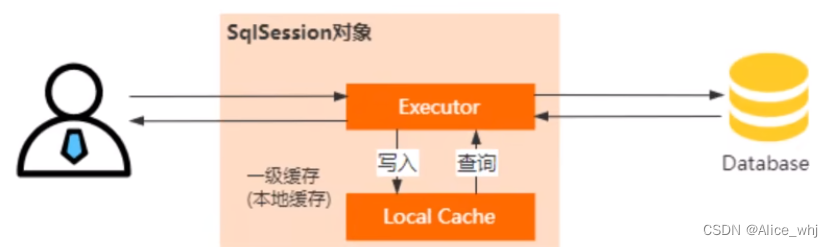
一级缓存是sqlsession级别的,是一个本地缓存,生命周期是sqlsession,分布式场景下可能存在脏读
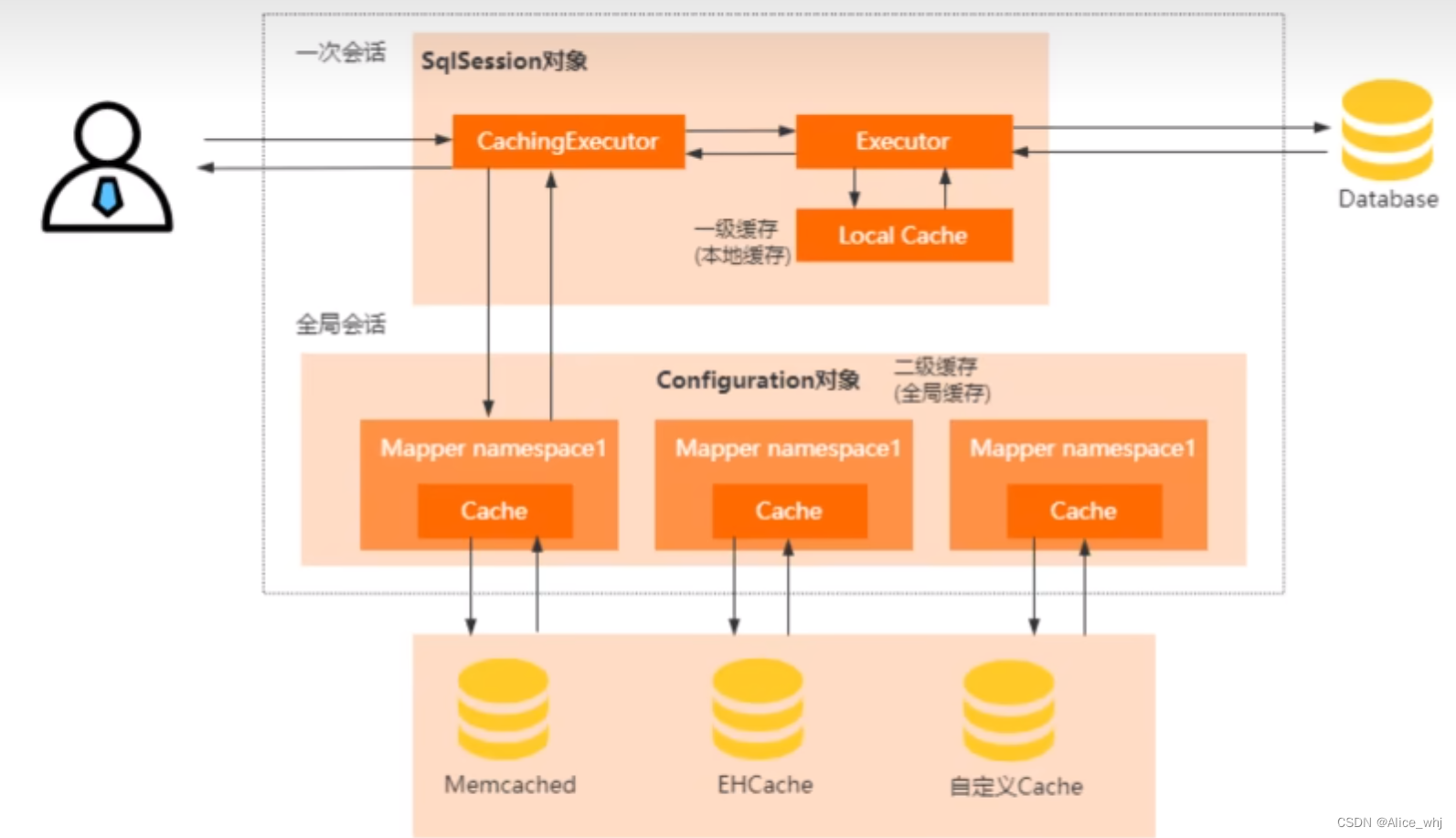
二级缓存,多用户跨sqlsession,全局的,缓存粒度控制在nameSpace
MyBatis 一级缓存最大的共享范围就是一个SqlSession内部,那么如果多个 SqlSession 需要共享缓存,则需要开启二级缓存,开启二级缓存后,会使用 CachingExecutor 装饰 Executor,进入一级缓存的查询流程前,先在CachingExecutor 进行二级缓存的查询,具体的工作流程如下所示
当二级缓存开启后,同一个命名空间(namespace) 所有的操作语句,都影响着一个共同的 cache,也就是二级缓存被多个 SqlSession 共享,是一个全局的变量。当开启缓存后,数据的查询执行的流程就是 二级缓存 -> 一级缓存 -> 数据库。
二级缓存开启条件
二级缓存默认是不开启的,需要手动开启二级缓存,实现二级缓存的时候,MyBatis要求返回的POJO必须是可序列化的。开启二级缓存的条件也是比较简单,通过直接在 MyBatis 配置文件中通过
<settings>
<setting name = "cacheEnabled" value = "true" />
</settings>
来开启二级缓存,还需要在 Mapper 的xml 配置文件中加入 标签
设置 cache 标签的属性
cache 标签有多个属性,一起来看一些这些属性分别代表什么意义
eviction: 缓存回收策略,有这几种回收策略
LRU - 最近最少回收,移除最长时间不被使用的对象
FIFO - 先进先出,按照缓存进入的顺序来移除它们
SOFT - 软引用,移除基于垃圾回收器状态和软引用规则的对象
WEAK - 弱引用,更积极的移除基于垃圾收集器和弱引用规则的对象
默认是 LRU 最近最少回收策略



探究多表操作对二级缓存的影响
AB表,查A连表查了B的数据,放到A对应nameSpace下,这时去更新B表,A中缓存的数据没变,造成错误。
如果是两个mapper命名空间的话,可以使用 来把一个命名空间指向另外一个命名空间,从而消除上述的影响。
是否应该使用二级缓存?
那么究竟应该不应该使用二级缓存呢?先来看一下二级缓存的注意事项:
缓存是以namespace为单位的,不同namespace下的操作互不影响。
insert,update,delete操作会清空所在namespace下的全部缓存。
通常使用MyBatis Generator生成的代码中,都是各个表独立的,每个表都有自己的namespace。
多表操作一定不要使用二级缓存,因为多表操作进行更新操作,一定会产生脏数据。
如果你遵守二级缓存的注意事项,那么你就可以使用二级缓存。



















 1523
1523











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









