







论文发表年份:2012
主要内容:1、当前在个性化推荐中如何使用数据挖掘技术
2、从 Netflix竞赛中获得的经验;
3、Netflix竞赛中主要使用的个性化推荐技术
4、展望
相对于数据挖掘技术,还存在很多可能对推荐效果影响更大的问题。比如用户交互设计等。但这些不属于本文关注范围。
实际上,商业中使用的绝大多数高级的推荐系统很少是纯粹的协同过滤或者基于内容这样单一的推荐,而一般是混合的。
1.2.推荐系统中的数据挖掘方法
《Recommender Systems Handbook》中有专门的一章来介绍在推荐系统中使用数据挖掘技术。一般地,像PCA、SVD、决策树、聚类、分类、神经网络、贝叶斯及关联规则等都能在推荐系统中使用
2.Netflix 竞赛
2.1从竞赛中获得的经验
netflix半程冠军,经过了2000个小时的努力,共融合了107中算法,实现8.43%的提升。
3.Netflix个性化:不仅仅是评分预测
3.1消费者数据科学
Netflix是一家基于消费者数据科学的组织。也就是一家数据驱动的组织。实际是如何执行的呢?(对A/B test的轻微改变)
1)设定一个假设。比如,算法X能够增加用户参与度
2)设计测试
3)执行测试。将用户分到不同的组中,每组的经历不同,关注最终的反馈
4)让数据说话。基于指标评估
Netflix从线下提出假设到线上模型部署的整个流程如下:
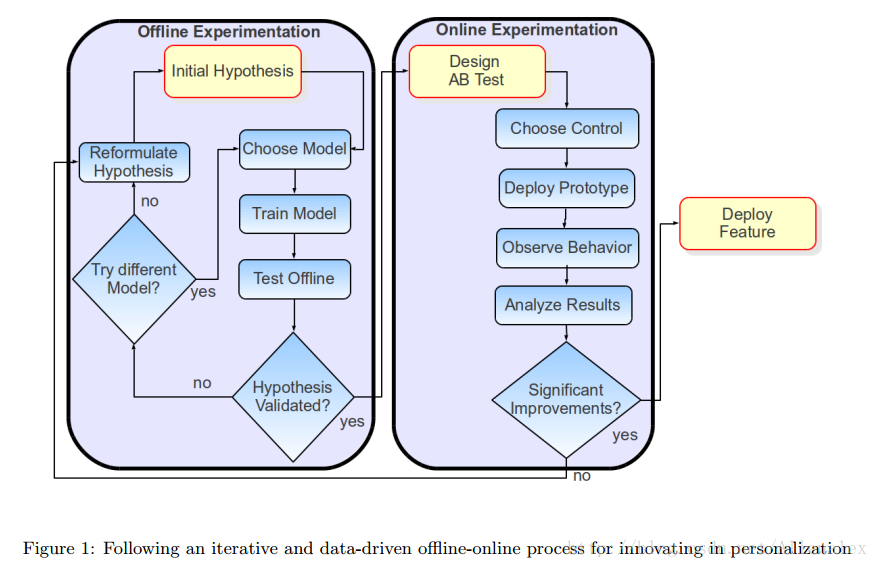
Netflix针对的是家庭的推荐,所以不仅仅是推荐准确性,推荐的多样性也非常的重要。此外,还有推荐结果被用户是否能意识到。推荐被用户意识到的好处有很多。比如,增加用户的信任;为了提高推荐效果,用户更加积极的参与反馈。增加用户
信任的另一种途径是增加推荐的解释。
排序
如何给用户生成一个用户感兴趣的推荐列表。最直接最保险的方法是考虑物品的流行度。但流行度是和个性化相对的,如果只考虑流行度,那每个用户的推荐列表都一样。但是如果只考虑个性化,推荐列表可能包含很多质量很差的物品。所以实际
的排序中,需要兼顾考虑流行度和个性化。有什么方法呢?
方法1:最直接的线性组合
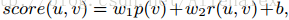
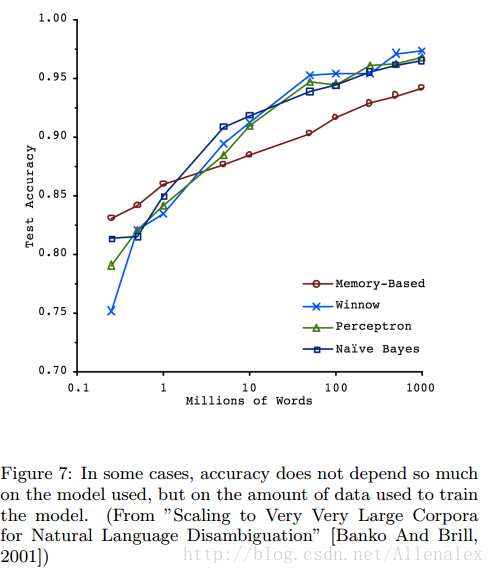
讨论:我们需要更多的数据还是要更好的模型?
参考文献【1】,【2】都宣称更多的数据会带来更好的效果,但模型对效果几乎没什么影响。如下图所示:
但是,这种观念只能说在某些情况下是正确的。但更多场景其实不然。本文作者总结的非常到位,如下:
将模型分为高方差( high variance )模型和高偏差( high bias)模型。
存在两种可能完全相反的原因会造成一个模型效果不好:
原因1:相对已有的数据量,模型太复杂了。这种场景称之为高方差,会造成过拟合(训练误差小,但测试误差大)。解决这种问题可以减小特征数量,或者增加数据。参考文献【1、2】中涉及到的就是这种——相对于训练样本,特征太多了。所以增加数据量能够提高准确性。
原因2:我们的模型太简单,无法“解析”已有的数据。这种场景叫做高偏差。你没法通过增加更多数据来提高效果。如下图所示:
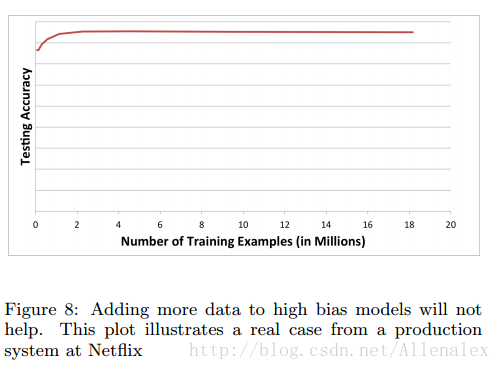
那么,对于这种高偏差模型,是不是增加更多的特征就一定有帮助呢? 那也要看情况。
数据还是非常重要的,但如果没有正确的方法,数据就是噪音
研究方向
1.非明确评分
很多的推荐引擎是基于明确评分的。实际上明确的评分有时候存在噪声等问题。能够有效利用到那些用户间接的评分/喜好可能会更好。这方面可以参考【3】、【4】、【5】和【6】。
2.基于上下文感知的推荐
【7】表明,在推荐中,考虑用户所处的上下文(地点、时间),有实际的商业价值。
《Recommender Systems Handbook》有专门的一章介绍基于上下文感知的推荐。感兴趣的可以去学习。
参考文献:
【1】A. Halevy, P. Norvig, and F. Pereira. The Unreasonable Eectiveness of Data. IEEE Intelligent Systems,
24(2):8{12, March 2009
【2】M. Banko and E. Brill. Scaling to very very large corpora for natural language disambiguation. In Proc. of
ACL ‘01, pages 26{33, 2001.
【3】S. Rendle, C. Freudenthaler, Z. Gantner, and L. S.Thieme. BPR: Bayesian personalized ranking from implicit feedback. In Proceedings of the 25th UAI, 2009.
【4】D. Parra and X. Amatriain. Walk the Talk: Analyzing the relation between implicit and explicit feedback for preference elicitation. In User Modeling, Adaption and
Personalization, volume 6787, chapter 22, pages 255{268. Springer, 2011.
【5】D. Parra, A. Karatzoglou, X. Amatriain, and I. Yavuz.Implicit feedback recommendation via implicit-toexplicit ordinal logistic regression mapping. In Proc. of
the 2011 CARS Workshop.
【6】D. H. Stern, R. Herbrich, and T. Graepel. Matchbox:large scale online bayesian recommendations. In Proc.of the 18th WWW, 2009.
【7】M. Gorgoglione, U. Panniello, and A. Tuzhilin. The effect of context-aware recommendations on customer purchasing behavior and trust. In Proc. of Recsys ‘11,
pages 85{92, 2011.


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









