







第3章 入门
学会了如何安装和运行Redis,并了解了Redis的基础知识后,本章将详细介绍Redis的五种数据类型及相应的命令,真正进入Redis的世界。在学习的时候,手边打开一个redis-cli程序来跟着一起输入命令将会极大地提高学习效率。
3.2节到3.6节这5节将分别介绍Redis的5种数据类型,其中每节都是由4个部分组成,依次是“介绍”、“命令”、“实践”和“命令拾遗”。“介绍”部分是对数据类型的概述,“命令”部分会对“实践”部分将用到的命令进行介绍,“实践”部分会讲解该数据类型在开发中的应用方法,“命令拾遗”部分会对该数据类型其他比较有用的命令进行补充介绍。
3.1 热身
在介绍 Redis的数据类型之前,我们先来了解几个比较基础的命令作为热身,赶快打开redis-cli,跟着样例亲自输入命令来体验一下吧!
1.获得符合规则的键名列表
KEYS pattern
pattern支持glob风格通配符格式,具体规则如表3-1所示。
表3-1 glob 风格通配符规则
| 符号 | 含义 |
| ? | 匹配一个字符 |
| * | 匹配任意个(包含0个)字符 |
| [ ] | 匹配括号间的任一字符,可以使用”-”符号表示一个范围,如a[b-d]可以匹配“ab”,“ac”和“ad” |
| \x | 匹配字符x,用于转义符号。如要匹配“?”就需要使用\? |
现在Redis中空空如也(如果你从第2章开始就一直跟着进度输入命令,此时数据库中可能还会有个foo键),为了演示KEYS命令,首先我们得给Redis加点料。使用SET命令(会在 3.2节介绍)建立一个名为bar的键:
![]()
然后使用KEYS *就能获得Redis中所有的键了:
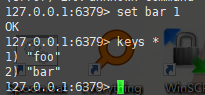
注意 KEYS命令需要遍历Redis中的所有键,当键的数量较多时会影响性能,不建议在生产环境中使用。
提示 Redis不区分命令大小写。简单的命令,我就不再截图了。
2.判断一个键是否存在
EXISTS key
如果键存在则返回整数类型1,否则返回0。如:
redis>EXISTS bar
(integer) 1
redis>EXISTS noexists
(integer)0
3.删除键
DEL key [key …]
可以删除一个或多个键,返回值是删除的键的个数。如:
redis>DEL bar
(integer) 1
redis>DEL bar
(integer) 0
第二次执行DEL命令时因为bar键已经被删除了,实际上并没有删除任何键,所以返回0。
技巧 DEL 命令的参数不支持通配符,但我们可以结合Linux 的管道和xargs 命令自己实现删除所有符合规则的键。比如要删除所有以“user:”开头的键,就可以执行redis-cli KEYS "user:*" | xargs redis-cli DEL。另外由于DEL 命令支持多个键作为参数,所以还可以执行 redis-cli DEL 'redis-cli KEYS"user:*"'来达到同样的效果,但是性能更好。
4.获得键值的数据类型
TYPE key
TYPE命令用来获得键值的数据类型,返回值可能是string(字符串类型)、hash(散列类型)、list(列表类型)、set(集合类型)、zset(有序集合类型)。例如:
redis>SET foo 1
OK
redis>TYPE foo
string
redis>LPUSH bar 1
(integer) 1
redis>TYPE bar
list
LPUSH命令的作用是向指定的列表类型键中增加一个元素,如果键不存在则创建它,3.4节会详细介绍。
3.2 字符串类型
3.2.1 介绍
字符串类型是Redis中最基本的数据类型,它能存储任何形式的字符串,包括二进制数据。你可以用其存储用户的邮箱、JSON化的对象甚至是一张图片。一个字符串类型键允许存储的数据的最大容量是512MB。
注释:在Redis 3.0版本之后放宽这一限制,但无论如何,考虑到Redis的数据是使用 内存存储的,512MB的限制已经非常宽松了。
字符串类型是其他4种数据类型的基础,其他数据类型和字符串类型的差别从某种角度来说只是组织字符串的形式不同。例如,列表类型是以列表的形式组织字符串,而集合类型是以集合的形式组织字符串。学习过本章后面几节后会有更深的理解。
3.2.2 命令
1.赋值与取值
SET key value
GET key
SET和GET是Redis中最简单的两个命令,它们实现的功能和编程语言中的读写变量相似,如key="hello"在Redis中是这样表示的:
redis>SET key hello
OK
想要读取键值则更简单:
redis>GET key
"hello"
当键不存在时会返回空结果。
2.递增数字
INCR key
前面说过字符串类型可以存储任何形式的字符串,当存储的字符串是整数形式时,Redis 提供了一个实用的命令INCR,其作用是让当前键值递增,并返回递增后的值,用法为:
redis>INCR num
(integer) 1
redis>INCR num
(integer) 2
当要操作的键不存在时会默认键值为0,所以第一次递增后的结果是1。当键值不是整数时Redis会提示错误:
redis>SET foo lorem
OK
redis>INCR foo
(error) ERR value is not an integer or out of range
可以借助GET和SET两个命令自己实现incr函数,伪代码如下:
def incr($key)
$value=GET $key
if not $value
$value=0
$value= $value+1
SET $key, $value
return $value
如果Redis同时只连接了一个客户端,那么上面的代码没有任何问题(其实还没有加入错误处理,不过这并不是此处讨论的重点)。可当同一时间有多个客户端连接到Redis时则有可能出现竞态条件(race condition)。例如,有两个客户端A和B都要执行我们自己实现的incr函数并准备将同一个键的键值递增,当它们恰好同时执行到代码第二行时二者读取到的键值是一 样的,如“5”,而后它们各自将该值递增到“6”并使用SET命令将其赋给原键,结果虽然对键执行了两次递增操作,最终的键值却是“6”而不是预想中的“7”。包括INCR在内的所有Redis命令都是原子操作(atomic operation),无论多少个客户端同时连接,都不会出现上述情况。之后我们还会介绍利用事务(4.1 节)和脚本(第6章)实现自定义的原子操作的方法。
注释:竞态条件是指一个系统或者进程的输出,依赖于不受控制的事件的出现顺序或者出现时机。
注释:原子操作取“原子”的“不可拆分”的意思,原子操作是最小的执行单位,不会在执行的过程中被其他命令插入打断。
3.2.3 实践
1.文章访问量统计
博客的一个常见的功能是统计文章的访问量,我们可以为每篇文章使用一个名为post:文章ID:page.view的键来记录文章的访问量,每次访问文章的时候使用INCR命令使相应的键值 递增。
提示 Redis对于键的命名并没有强制的要求,但比较好的实践是用“对象类型:对象 ID:对象属性”来命名一个键,如使用键user:1:friends来存储ID为1的用户的好友列表。对于多个单词则推荐使用“.”分隔,一方面是沿用以前的习惯(Redis以前版本的键名不能包含空格等特殊字符),另一方面是在redis-cli中容易输入,无需使用双引号包裹。另外为了日后维护方便,键的命名一定要有意义,如u:1:f的可读性显然不如user:1:friends好(虽然采用较短的名称可以节省存储空间,但由于键值的长度往往远远大于键名的长度,所以这 部分的节省大部分情况下并不如可读性来得重要)。
2.生成自增ID
那么怎么为每篇文章生成一个唯一ID呢?在关系数据库中我们通过设置字段属性为AUTO_INCREMENT来实现每增加一条记录自动为其生成一个唯一的递增ID的目的,而在 Redis中可以通过另一种模式来实现:对于每一类对象使用名为对象类型(复数形式):count①的 键(如users:count)来存储当前类型对象的数量,每增加一个新对象时都使用INCR命令递增该 键的值。由于使用INCR命令建立的键的初始键值是1,所以可以很容易得知,INCR命令的返回 值既是加入该对象后的当前类型的对象总数,又是该新增对象的ID。
注释:①这个键名只是参考命名,实际使用中可以使用任何容易理解的名称。
3.存储文章数据
由于每个字符串类型键只能存储一个字符串,而一篇博客文章是由标题、正文、作者与发 布时间等多个元素构成的。为了存储这些元素,我们需要使用序列化函数(如PHP中的serialize 和JavaScript中的JSON.stringify)将它们转换成一个字符串。除此之外因为字符串类型键可以 存储二进制数据,所以也可以使用MessagePack②进行序列化,速度更快,占用空间也更小。
注释:②MessagePack和JSON一样可以将对象序列化成字符串,但其性能更高,序列化后 的结果占用空间更小,序列化后的结果是二进制格式。MessagePack的项目地址是 http://msgpack.org. 至此我们已经可以写出发布新文章时与Redis操作相关的伪代码了:
#首先获得新文章的ID
$postID=INCR posts:count
#将博客文章的诸多元素序列化成字符串
$serializedPost=serialize( $title, $content, $author, $time)
#把序列化后的字符串存一个入字符串类型的键中
SET post: $postID:data, $serializedPost
获取文章数据的伪代码如下(以访问ID 为42的文章为例):
#从Redis 中读取文章数据
$serializedPost=GET post:42:data
#将文章数据反序列化成文章的各个元素
$title, $content, $author, $time=unserialize( $serializedPost)
#获取并递增文章的访问数量
$count=INCR post:42:page.view
除了使用序列化函数将文章的多个元素存入一个字符串类型键中外,还可以对每个元素使用一个字符串类型键来存储,这种方法会在3.3.3节讨论。
3.2.4 命令拾遗
1.增加指定的整数
INCRBY key increment
INCRBY命令与INCR命令基本一样,只不过前者可以通过increment参数指定一次增加的 数值,如:
redis>INCRBY bar 2
(integer) 2
redis>INCRBY bar 3
(integer) 5
2.减少指定的整数
DECR key
DECRBY key decrement
DECR命令与INCR命令用法相同,只不过是让键值递减,例如:
redis>DECR bar
(integer)4
而DECRBY命令的作用不用介绍想必你也可以猜到,DECRBY key 5 相当于INCRBY key -5。
3.增加指定浮点数
INCRBYFLOAT key increment
INCRBYFLOAT 命令类似INCRBY命令,差别是前者可以递增一个双精度浮点数,如:
redis>INCRBYFLOAT bar 2.7
"6.7"
redis>INCRBYFLOAT bar 5E+4
"50006.69999999999999929"
4.向尾部追加值
APPEND key value
APPEND作用是向键值的末尾追加value。如果键不存在则将该键的值设置为value,即相当于SET key value。返回值是追加后字符串的总长度。例如:
redis>SET key hello
OK
redis>APPEND key " world!"
(integer) 12
此时key的值是"hello world!"。APPEND命令的第二个参数加了双引号,原因是该参数包含空格,在redis-cli中输入需要双引号以示区分。
5.获取字符串长度
STRLEN key
STRLEN命令返回键值的长度,如果键不存在则返回0。例如:
redis>STRLEN key
(integer)12
redis>SET key 你好
OK
redis>STRLEN key
(integer)6
前面提到了字符串类型可以存储二进制数据,所以它可以存储任何编码的字符串。例子中Redis接收到的是使用UTF-8编码的中文,由于“你”和“好”两个字的UTF-8编码的长度都是 3,所以此例中会返回6。
6.同时获得/设置多个键值
MGET key [key …]
MSET key value [key value …]
MGET/MSET与GET/SET相似,不过MGET/MSET可以同时获得/设置多个键的键值。例如:
redis>MSET key1 v1 key2 v2 key3 v3
OK
redis>GET key2
"v2"
redis>MGET key1 key3
1) "v1"
2) "v3"
7.位操作
GETBIT key offset
SETBIT key offset value
BITCOUNT key [start] [end]
BITOP operation destkey key [key …]
一个字节由8个二进制位组成,Redis提供了4个命令可以直接对二进制位进行操作。为了演示,我们首先将foo键赋值为bar:
redis>SET foo bar
OK
bar的3个字母对应的ASCII码分别为98、97和114,转换成二进制后分别为1100010、1100001和1110010,所以foo键中的二进制位结构如图3-3所示。

图3-3 bar 的二进制存储结构
GETBIT命令可以获得一个字符串类型键指定位置的二进制位的值(0或1),索引从0开始:
redis>GETBIT foo 0
(integer) 0
redis>GETBIT foo 6
(integer) 1
如果需要获取的二进制位的索引超出了键值的二进制位的实际长度则默认位值是0:
redis>GETBIT foo 100000
(integer) 0
SETBIT 命令可以设置字符串类型键指定位置的二进制位的值,返回值是该位置的旧值。如我们要将foo键值设置为aar,可以通过位操作将foo键的二进制位的索引第6位设为0,第7位 设为1:
redis>SETBIT foo 6 0
(integer) 1
redis>SETBIT foo 7 1
(integer) 0
redis>GET foo "aar"
如果要设置的位置超过了键值的二进制位的长度,SETBIT命令会自动将中间的二进制位 设置为0,同理设置一个不存在的键的指定二进制位的值会自动将其前面的位赋值为0:
redis>SETBIT nofoo 10 1
(integer) 0
redis>GETBIT nofoo 5
(integer) 0
BITCOUNT命令可以获得字符串类型键中值是1的二进制位个数,例如:
redis>BITCOUNT foo
(integer)10
可以通过参数来限制统计的字节范围,如我们只希望统计前两个字节(即"aa"):
redis>BITCOUNT foo 0 1
(integer)6
BITOP命令可以对多个字符串类型键进行位运算,并将结果存储在destkey参数指定的键 中。BITOP命令支持的运算操作有AND、OR、XOR 和NOT。如我们可以对bar和aar进行OR运 算:
redis>SET foo1 bar
OK
redis>SET foo2 aar
OK
redis>BITOP OR res foo1 foo2
(integer) 3
redis>GET res
"car"
运算过程如图3-4所示。

图3-4 OR运算过程示意
利用位操作命令可以非常紧凑地存储布尔值。比如某网站的每个用户都有一个递增的整数ID,如果使用一个字符串类型键配合位操作来记录每个用户的性别(用户ID作为索引,二进 制位值1和0表示男性和女性),那么记录100万个用户的性别只需占用100 KB多的空间,而且 由于GETBIT和SETBIT的时间复杂度都是0(1),所以读取二进制位值性能很高。
3.3 散列类型
场景:
假如想要做的功能是博客的文章列表页,我设想在列表页中每个文章只显示标题部分,可是使用刚才介绍的方法,若想取得文章的标题,必须把整个文章数据字符串取出来反序列化,而其中占用空间最大的文章內容部分却是不需要的,这样会在传输和处理时造成资源浪费。不仅取数据时会有资源浪费,在修改数据时也会有这个问题,比如当你只想更改文章的标题时也不得不把整个文章数据字符串更新一遍。
前面说过Redis的强大特性之一就是提供了多种实用的数据类型,其中的散列类型可以非常好地解决这个问题。
3.3.1 介绍
我们现在已经知道Redis是采用字典结构以键值对的形式存储数据的,而散列类型(hash) 的键值也是一种字典结构,其存储了字段(field)和字段值的映射,但字段值只能是字符串,不支持其他数据类型,换句话说,散列类型不能嵌套其他的数据类型。一个散列类型键可以包含至多2^32-1个字段。
提示 除了散列类型,Redis的其他数据类型同样不支持数据类型嵌套。比如集合类型的每个元素都只能是字符串,不能是另一个集合或散列表等。
散列类型适合存储对象:使用对象类别和ID构成键名,使用字段表示对象的属性,而字段 值则存储属性值。例如要存储ID为2的汽车对象,可以分别使用名为color、name和price的3个字 段来存储该辆汽车的颜色、名称和价格。存储结构如图3-5所示。

图3-5 使用散列类型存储汽车对象的结构图
回想在关系数据库中如果要存储汽车对象,存储结构如表3-2所示。
表3-2 关系数据库存储汽车资料的表结构
| ID | Color | Name | Price |
| 1 | 黑色 | 宝马 | 100万 |
| 2 | 白色 | 奥迪 | 90万 |
| 3 | 蓝色 | 宾利 | 600万 |
数据是以二维表的形式存储的,这就要求所有的记录都拥有同样的属性,无法单独为某条记录增减属性。如果想为ID为1的汽车增加生产日期属性,就需要把数据表更改为如表3-3所 示的结构。
表3-3 为其中一辆汽车增加一个“属性”
| ID | Color | Name | Price | Date |
| 1 | 黑色 | 宝马 | 100万 | 2012年12月21日 |
| 2 | 白色 | 奥迪 | 90万 |
|
| 3 | 蓝色 | 宾利 | 600万 |
|
对于ID为2和3的两条记录而言date字段是冗余的。可想而知当不同的记录需要不同的属 性时,表的字段数量会越来越多以至于难以维护。而且当使用ORM① 将关系数据库中的对象 实体映射成程序中的实体时,修改表的结构往往意味着要中断服务(重启网站程序)。为了防止这些问题,在关系数据库中存储这种半结构化数据还需要额外的表才行。
注释:①即Object-Relational Mapping(对象关系映射)。
而Redis的散列类型则不存在这个问题。虽然我们在图3-5中描述了汽车对象的存储结构, 但是这个结构只是人为的约定,Redis并不要求每个键都依据此结构存储,我们完全可以自由 地为任何键增减字段而不影响其他键。
3.3.2 命令
1.赋值与取值
HSET key field value
HGET key field
HMSET key field value [field value …]
HMGET key field [field …]
HGETALL key
HSET命令用来给字段赋值,而HGET命令用来获得字段的值。用法如下:
redis>HSET car price 500
(integer) 1
redis>HSET car name BMW
(integer) 1
redis>HGET car name
"BMW"
HSET命令的方便之处在于不区分插入和更新操作,这意味着修改数据时不用事先判断字段是否存在来决定要执行的是插入操作(update)还是更新操作(insert)。当执行的是插入操作 时(即之前字段不存在)HSET命令会返回1,当执行的是更新操作时(即之前字段已经存 在)HSET命令会返回0。更进一步,当键本身不存在时,HSET命令还会自动建立它。
提示 在Redis中每个键都属于一个明确的数据类型,如通过HSET命令建立的键是散列类型,通过SET命令建立的键是字符串类型等。使用一种数据类型的命令操作另一种数据类型的键会提示错误:“ERR Operation against a key holding the wrong kind of value”① 。
注释:①并不是所有命令都是如此,比如SET命令可以覆盖已经存在的键而不论原来键是什么类型。
当需要同时设置多个字段的值时,可以使用HMSET命令。例如,下面两条语句
HSET key field1 value1
HSET key field2 value2
可以用HMSET命令改写成
HMSET key field1 value1 field2 value2
相应地,HMGET命令可以同时获得多个字段的值:
redis>HMGET car price name
1) "500"
2) "BMW"
如果想获取键中所有字段和字段值却不知道键中有哪些字段时(如3.3.1节介绍的存储汽车对象的例子,每个对象拥有的属性都未必相同)应该使用HGETALL命令。如:
redis>HGETALL car
1) "price"
2) "500"
3) "name"
4) "BMW"
返回的结果是字段和字段值组成的列表,不是很直观,好在很多语言的Redis客户端会将 HGETALL的返回结果封装成编程语言中的对象,处理起来就非常方便了。例如,在Node.js中:
redis.hgetall("car", function (error,car){
//hgetall方法的返回的值被封装成了JavaScript的对象
console.log(car.price);
console.log(car.name);
});
2.判断字段是否存在
HEXISTS key field
HEXISTS命令用来判断一个字段是否存在。如果存在则返回1,否则返回0(如果键不存在也会返回0)。
redis>HEXISTS car model
(integer) 0
redis>HSET car model C200
(integer) 1
redis>HEXISTS car model
(integer) 1
3.当字段不存在时赋值
HSETNX key field value
HSETNX① 命令与HSET命令类似,区别在于如果字段已经存在,HSETNX命令将不执行任何操作。其实现可以表示为如下伪代码:
注释:①HSETNX 中的“NX”表示“if Not eXists”(如果不存在)。
def hsetnx( $key, $field, $value)
$isExists=HEXISTS $key, $field
if $isExists is 0
HSET $key, $field, $value
return 1
else
return 0
只不过HSETNX命令是原子操作,不用担心竞态条件。
4.增加数字
HINCRBY key field increment
上一节的命令拾遗部分介绍了字符串类型的命令INCRBY,HINCRBY命令与之类似,可以使字段值增加指定的整数。散列类型没有HINCR命令,但是可以通过HINCRBY keyfield 1来 实现。 HINCRBY命令的示例如下:
redis>HINCRBY person score 60
(integer) 60
之前person键不存在,HINCRBY命令会自动建立该键并默认score字段在执行命令前的值为“0”。命令的返回值是增值后的字段值。
5.删除字段
HDEL key field [field …]
HDEL命令可以删除一个或多个字段,返回值是被删除的字段个数:
redis>HDEL car price
(integer) 1
redis>HDEL car price
(integer) 0
3.3.3 实践
1.存储文章数据
3.2.3节介绍了可以将文章对象序列化后使用一个字符串类型键存储,可是这种方法无法提供对单个字段的原子读写操作支持,从而产生竞态条件,如两个客户端同时获得并反序列化某个文章的数据,然后分别修改不同的属性后存入,显然后存入的数据会覆盖之前的数据,最后只会有一个属性被修改。另外如本节开始所说,即使只需要文章标题,程序也不得不将包括文章内容在内的所有文章数据取出并反序列化,比较消耗资源。除此之外,还有一种方法是组合使用多个字符串类型键来存储一篇文章的数据,如图3-6 所示。

图3-6 使用多个字符串类型键存储一个对象
使用这种方法的好处在于无论获取还是修改文章数据,都可以只对某一属性进行操作,十分方便。而本章介绍的散列类型则更适合此场景,使用散列类型的存储结构如图3-7所示。

图3-7 使用一个散列类型键存储一个对象
从图3-7可以看出使用散列类型存储文章数据比图3-6所示的方法看起来更加直观也更容 易维护(比如可以使用HGETALL命令获得一个对象的所有字段,删除一个对象时只需要删除 一个键),另外存储同样的数据散列类型往往比字符串类型更加节约空间,具体的细节会在4.6 节中介绍。
2.存储文章缩略名
使用过WordPress的读者可能会知道发布文章时一般需要指定一个缩略名(slug)来构成该篇文章的网址的一部分,缩略名必须符合网址规范且最好可以与文章标题含义相似,如“This Is A Great Post!”的缩略名可以为“this-is-a-great-post”。每个文章的缩略名必须是唯一的,所以在发布文章时程序需要验证用户输入的缩略名是否存在,同时也需要通过缩略名获得文章的 ID。
我们可以使用一个散列类型的键slug.to.id来存储文章缩略名和ID之间的映射关系。其中字段用来记录缩略名,字段值用来记录缩略名对应的ID。这样就可以使用HEXISTS命令来判 断缩略名是否存在,使用HGET命令来获得缩略名对应的文章ID了。现在发布文章可以修改成如下代码:
$postID=INCR posts:count
#判断用户输入的slug是否可用,如果可用则记录
$isSlugAvailable=HSETNX slug.to.id, $slug, $postID
if $isSlugAvailable is 0
#slug已经用过了,需要提示用户更换slug,
#这里为了演示方便直接退出。
exit
HMSET post: $postID, title, $title, content, $content, slug, $slug,...
这段代码使用了HSETNX命令原子地实现了HEXISTS和HSET两个命令以避免竞态条件。当用户访问文章时,我们从网址中得到文章的缩略名,并查询slug.to.id键来获取文章ID:
$postID=HGET slug.to.id, $slug
if not $postID
print文章不存在
exit
$post=HGETALL post: $postID
print文章标题: $post.title
需要注意的是如果要修改文章的缩略名一定不能忘了修改slug.to.id键对应的字段。如要修改ID为42的文章的缩略名为newSlug 变量的值:
#判断新的slug是否可用,如果可用则记录
$isSlugAvailable=HSETNX slug.to.id, $newSlug, 42
if $isSlugAvailable is 0
exit
#获得旧的缩略名
$oldSlug=HGET post:42, slug
#设置新的缩略名
HSET post:42, slug, $newSlug
#删除旧的缩略名
HDEL slug.to.id, $oldSlug
3.3.4 命令拾遗
1.只获取字段名或字段值
HKEYS key
HVALS key
有时仅仅需要获取键中所有字段的名字而不需要字段值,那么可以使用HKEYS命令,就像这样:
redis>HKEYS car
1) "name"
2) "model"
HVALS命令与HKEYS命令相对应,HVALS命令用来获得键中所有字段值,例如:
redis>HVALS car
1) "BMW"
2) "C200"
2.获得字段数量
HLEN key
例如:
redis>HLEN car
(integer) 2
















 496
496











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











