






描述:
使用的是impala数据库,假设有四笔数据,是无序的,业务上要求将其行转列成一行数据,并且里面的数据要按从小到大排序。
过程:
猜测:
数据库Oracle、Mysql、MSsql等支持group_concat中使用order by,那么impala支持不支持呢?实践一下发现:Impala不支持group_concat中使用order by
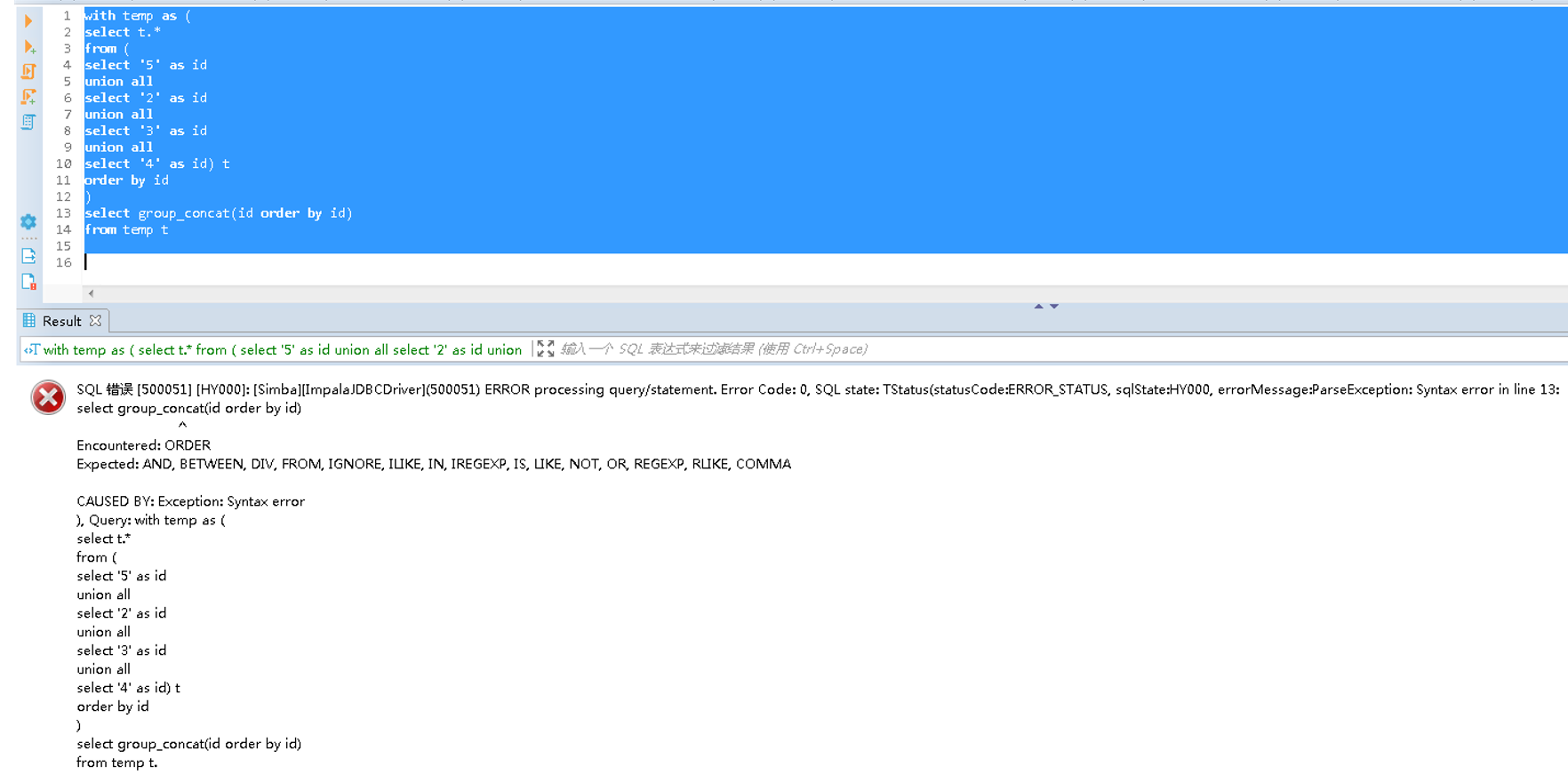
总结:常见数据库Oracle、Mysql、MSsql等支持group_concat中使用order by,但是Impala不支持group_concat中使用order by
方法一:
尝试先对这四笔数据进行排序,再进行行转列,但发现最终出来的数据还是达不到预期:

总结:内层的order by语句单独使用不会影响结果集仅排序在执行期间就被代码分析器给优化掉了。内层的order by要影响结果集,可以配合limit使用。
with temp as (
select t.*
from (
select '5' as id
union all
select '2' as id
union all
select '3' as id
union all
select '4' as id ) t
order by id
limit 4
)
select group_concat(id)
from temp;
方法二:
采用 row_number + concat_ws + group_concat,达到预期效果。
注意:如果是业务强烈要求、或者数据量不会太大的话,建议这么处理
步骤:
1、聚合前的数据筛选,完成数据过滤
2、开窗,row_number进行数据排序,添加序号,并cast转为字符串;
3、多字段组合,concat_ws进行聚合字段和序号字段的拼接,并replace掉序号为空串(concat_ws只支持字符串)
4、单字段聚合,group_concat进行最后的数据拼接
5、输出结果!
with temp as (
select '5' as id
union all
select '2' as id
union all
select '3' as id
union all
select '4' as id ),
rn as (select id,cast(row_number() over(order by id) as string) as rn from temp),
re as (select group_concat(concat_ws('',id,replace(rn,rn,''))) id from rn)
select *
from re;
总结:
1、 内层的order by语句单独使用不会影响结果集仅排序在执行期间就被代码分析器给优化掉了。内层的order by要影响结果集,可以配合limit使用。
2、如果是业务强烈要求、或者数据量不会太大的话,采用 row_number + concat_ws + group_concat,达到预期效果。
















 3537
3537











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











