







原创作品 转载请注明出http://blog.csdn.net/always2015/article/details/49449699
一、字典
我们要介绍一个新的类,词典 (dictionary)。与列表相似,词典也可以储存多个元素。这种储存多个元素的对象称为容器。和c++容器(container)类似。字典值可以是任意类型的 Python 对象,字典元素用大括号({ })包裹。说道容器,那么我们就知道容器内部是由键-值(key-value)对构成,所以我们一般声明字典的方法如下:
>>> dix={"xiaoming":19,"xiaosan":18,"xiaoliu":20}
>>> print dix
{'xiaoming': 19, 'xiaosan': 18, 'xiaoliu': 20}
>>>
>>> print type(dix)
<type 'dict'>
>>>
由于键——值对应,所以上述’xiaoming’对应 19, ‘xiaosan’对应18, ‘xiaoliu’对应20.
与表不同的是,字典的元素没有顺序。你不能通过下标引用元素。词典是通过键来引用。例如:
>>> print dix["xiaosan"]
18
>>>
>>> dix["xiaoliu"]=30
>>> print dix
{'xiaoming': 19, 'xiaosan': 18, 'xiaoliu': 30}
1、字典的常用方法
他的常用方法和容器的类似,一些常用的方法如下:
>>>print dix.keys() # 返回dix所有的键
>>>print dix.values() # 返回dix所有的值
>>>print dix.items() # 返回dix所有的元素(键值对)
>>>dix.clear() # 清空dix,dict变为{}
>>>del dix['xiaosan'] # 删除 dix 的‘xiaosan’元素
>>>print len(dix) #返回字典元素的个数2、文件和内建函数 open()
我们打开一个文件,并使用一个对象来表示该文件:
对象名 = open(文件名,模式)最常用的模式有:
- r 打开只读文件,该文件必须存在
- r+ 打开可读写的文件,该文件必须存在
- w 打开只写文件,若文件存在则文件长度清为0,即该文件内容会消失。若文件不存在则建立该文件。
- w+ 打开可读写文件,若文件存在则文件长度清为零,即该文件内容会消失。若文件不存在则建立该文件
- a 以附加的方式打开只写文件。若文件不存在,则会建立该文件,如果文件存在,写入的数据会被加到文件尾,即文件原先的内容会被保留
- a+ 以附加方式打开可读写的文件。若文件不存在,则会建立该文件,如果文件存在,写入的数据会被加到文件尾后,即文件原先的内容会被保留。
上述的形态字符串都可以再加一个b字符,如rb、w+b或ab+等组合,加入b 字符用来告诉函数库打开的文件为二进制文件,而非纯文字文件。
比如可以写成以下形式:
>>>f = open("test.txt","r")2.1、文件对象的方法
读取:
content = f.read(N) #读取N bytes的数据
content = f.readline() # 读取一行
content = f.readlines() # 读取所有行,储存在列表中,每个元素是一行。
写入:
f.write("I am a good boy!!\n") #注意:该文件必须为可写入文件,要不会出错关闭文件:
f.close()二、模块
1、引入模块
模块是一种组织形式, 它将彼此有关系的 Python 代码组织到一个个独立文件当中。模块可以包含可执行代码, 函数和类或者这些东西的组合。
在Python中,一个.py文件就构成一个模块。通过模块,你可以调用其它文件中的程序
先写一个first.py文件。加入如下代码:
def say_hello():
print "hello"再写一个second.py,并引入first中的程序:
import first #将first模块引入
for i in range(5):
first.say_hello()直接在终端上输入python second.py运行结果如下:
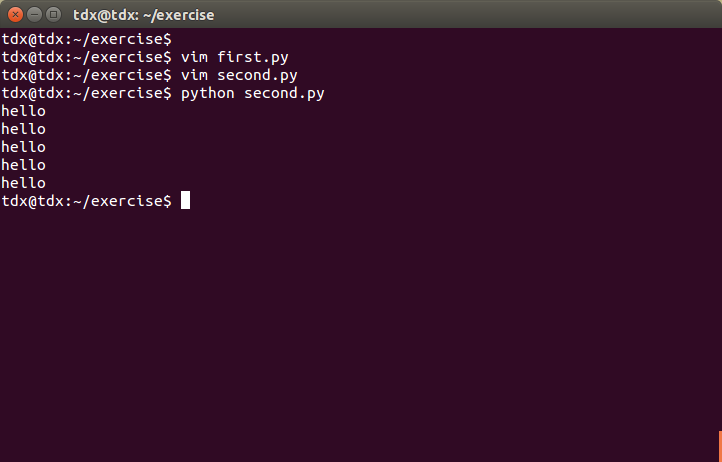
Python中还有其它的引入方式:
import a as b # 引入模块a,并将模块a重命名为b
from a import function # 从模块a中引入function对象。调用a中对象时,我们不用再说明模块,即直接使用function,而不是a.function。
from a import * # 从模块a中引入所有对象。调用a中对象时,我们不用再说明模块,即直接使用对象,而不是a.对象。2、模块搜索路径
Python会在以下路径中搜索模块:
- 程序所在的文件夹
- 操作系统环境变量PYTHONPATH所包含的路径
- 标准库的安装路径
3、模块包
可以将功能相似的模块放在同一个文件夹(比如说this_dir)中,构成一个模块包。通过
import this_dir.module引入this_dir文件夹中的module模块
该文件夹中必须包含一个 _init_.py 的文件,提醒Python,该文件夹为一个模块包。_init_.py 可以是一个空文件
三、函数参数的传递
前面我们已经接触到了函数的参数传递。当时我们根据位置,传递对应的参数。
def func(a,b,c):
return a+b+c
print(func(1,2,3))1、关键字传递
有些情况下,用位置传递会感觉比较死板。关键字(keyword)传递是根据每个参数的名字传递参数。关键字并不用遵守位置的对应关系。依然沿用上面func的定义,更改调用方式:
print(func(c=3,b=2,a=1))关键字传递可以和位置传递混用。但位置参数要出现在关键字参数之前
print(f(1,c=3,b=2))2、包裹传递
在定义函数时,我们有时候并不知道调用的时候会传递多少个参数。这时候,包裹(packing)位置参数,或者包裹关键字参数,来进行参数传递,会非常有用。
下面是包裹位置传递的例子:
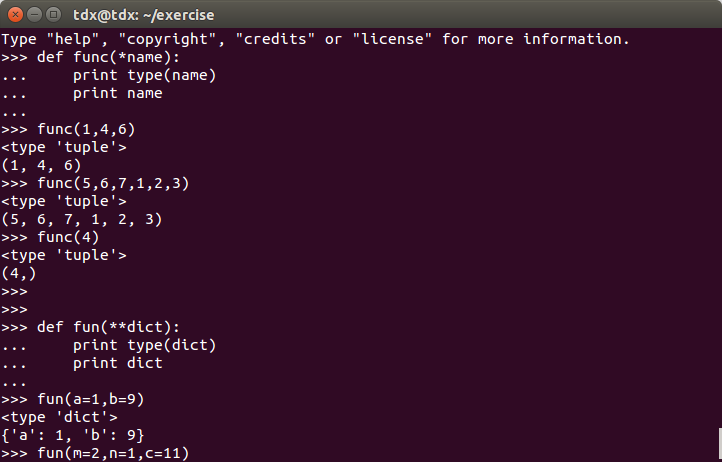
def func(*name):
print type(name)
print name
func(1,4,6)
func(5,6,7,1,2,3)两次调用,尽管参数个数不同,都基于同一个func定义。在func的参数表中,所有的参数被name收集,根据位置合并成一个元组(tuple),这就是包裹位置传递。
为了提醒Python参数,name是包裹位置传递所用的元组名,在定义func时,在name前加*号
下面是包裹关键字传递的例子:
def func(**dict):
print type(dict)
print dict
func(a=1,b=9)
func(m=2,n=1,c=11)与上面一个例子类似,dict是一个字典,收集所有的关键字,传递给函数func。为了提醒Python,参数dict是包裹关键字传递所用的字典,在dict前加 * *。
包裹传递的关键在于定义函数时,在相应元组或字典前加 * 或 * * 。
上面两个例子运行情况如下:
3、解包裹
一个星和两个星,也可以在调用的时候使用,即解包裹(unpacking), 下面为例:
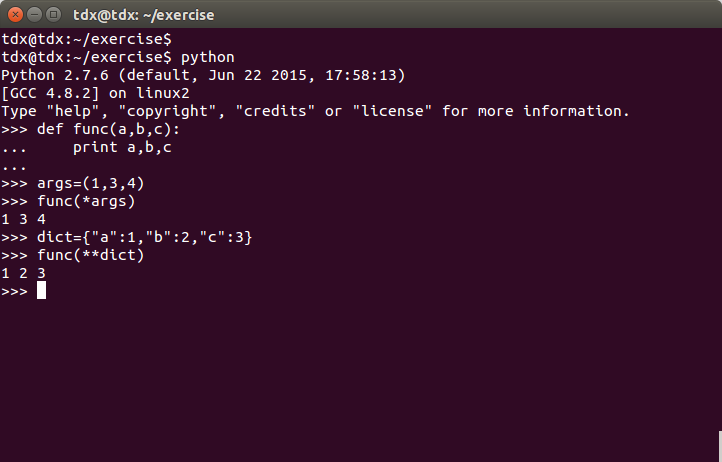
def func(a,b,c):
print a,b,c
args = (1,3,4)
func(*args)在这个例子中,所谓的解包裹,就是在传递tuple时,让tuple的每一个元素对应一个位置参数。在调用func时使用 * ,是为了提醒Python:我想要把args拆成分散的三个元素,分别传递给a,b,c。
相应的,也存在对词典的解包裹,使用相同的func定义,然后:
dict = {'a':1,'b':2,'c':3}
func(**dict)在传递词典dict时,让词典的每个键值对作为一个关键字传递给func.
以上两个函数运行结果如下:
5、混合
在定义或者调用参数时,参数的几种传递方式可以混合。但在过程中要小心前后顺序。基本原则是:先位置,再关键字,再包裹位置,再包裹关键字,并且根据上面所说的原理细细分辨。
注意:请注意定义时和调用时的区分。包裹和解包裹并不是相反操作,是两个相对独立的过程。

















 339
339

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









