









相关性分析
参考资料:https://zhuanlan.zhihu.com/p/59543716
数据分析:https://zhuanlan.zhihu.com/p/108491355?from_voters_page=true
一、二维数据
1.图形观测法
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
# 随机生成一组数据(X,Y)
data = pd.DataFrame(np.random.randn(200,2)*100, columns=['X','Y'])
# 绘制散点图
plt.figure(figsize = (6,6)) # 图片像素大小
plt.scatter(data.X, data.Y,color="blue") # 散点图绘制
plt.grid() # 显示网格线
plt.show() # 显示图片

2.科学计算
对数据进行假设检验,获得p值<0.05(或者0.01),得到结论:总体的数据呈现相关性然后进行相关性分析,得到r值
相关系数
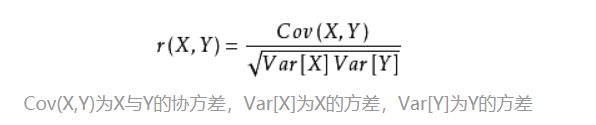

import numpy as np
import pandas as pd
import scipy.stats as stats
data = pd.DataFrame(np.random.randn(200,2)*100, columns=['X','Y'])
r,p = stats.pearsonr(data.X,data.Y) # 相关系数和P值
print('相关系数r为 = %6.3f,p值为 = %6.3f'%(r,p))
二、多维数据
可以得到两两之间的相关性系数r 和变量之间的散点分布图
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import scipy.stats as stats
# 导入数据
data = pd.DataFrame(np.random.randn(200,4)*100, columns = ['A','B','C','D'])
# 相关性计算
print(data.corr())
# 绘图
fig = pd.plotting.scatter_matrix(data,figsize=(6,6),c ='blue',marker = 'o',diagonal='',alpha = 0.8,range_padding=0.2) # diagonal只能为'hist'/'kde'
plt.show()
三、Apriori关联分析算法
找频繁项集
association_rules(df, metric=“confidence”,
min_threshold=0.8,
support_only=False):
参数介绍:
df:这个不用说,就是 Apriori 计算后的频繁项集。metric:可选值[‘support’,‘confidence’,‘lift’,‘leverage’,‘conviction’]。
里面比较常用的就是置信度和支持度。这个参数和下面的min_threshold参数配合使用。
min_threshold:参数类型是浮点型,根据 metric 不同可选值有不同的范围,
metric = ‘support’ => 取值范围 [0,1]
metric = ‘confidence’ => 取值范围 [0,1]
metric = ‘lift’ => 取值范围 [0, inf]
support_only:默认是 False。仅计算有支持度的项集,若缺失支持度则用 NaNs 填充。
import pandas as pd
from mlxtend.preprocessing import TransactionEncoder
from mlxtend.frequent_patterns import apriori
#设置数据集
dataset = [['牛奶','洋葱','肉豆蔻','芸豆','鸡蛋','酸奶'],
['莳萝','洋葱','肉豆蔻','芸豆','鸡蛋','酸奶'],
['牛奶','苹果','芸豆','鸡蛋'],
['牛奶','独角兽','玉米','芸豆','酸奶'],
['玉米','洋葱','洋葱','芸豆','冰淇淋','鸡蛋']]
te = TransactionEncoder()
#进行 one-hot 编码
te_ary = te.fit(records).transform(records)
df = pd.DataFrame(te_ary, columns=te.columns_)
#利用 Apriori 找出频繁项集
freq = apriori(df, min_support=0.05, use_colnames=True)
#导入关联规则包
from mlxtend.frequent_patterns import association_rules
#计算关联规则
result = association_rules(freq, metric="confidence", min_threshold=0.6)















 760
760











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









