







在Flink开发中经常会有将数据写入到redis的需求,但是Flink官方并没有对应的扩展包,这个时候需要我们自己编译对应的jar资源,这个时候就用到了bahir,barhir是apahce的开源项目,是专门给spark和flink提供扩展包使用的,bahir官网,这篇文章就介绍下如何自己编译RedisSink扩展包.
- 下载源码包
通过下图进入到GitHub
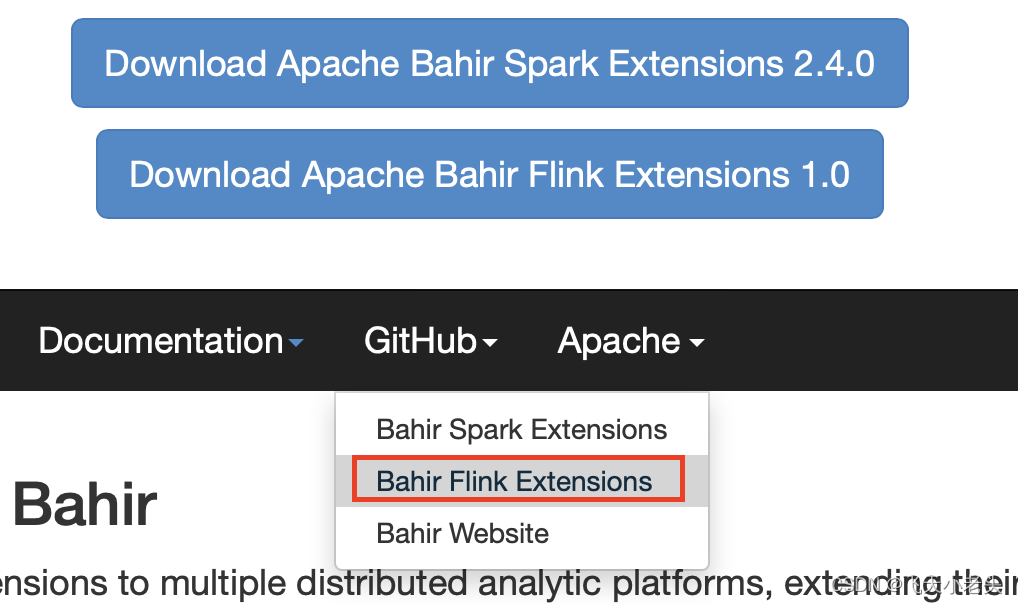
选择clone或download源码都可以,如下图
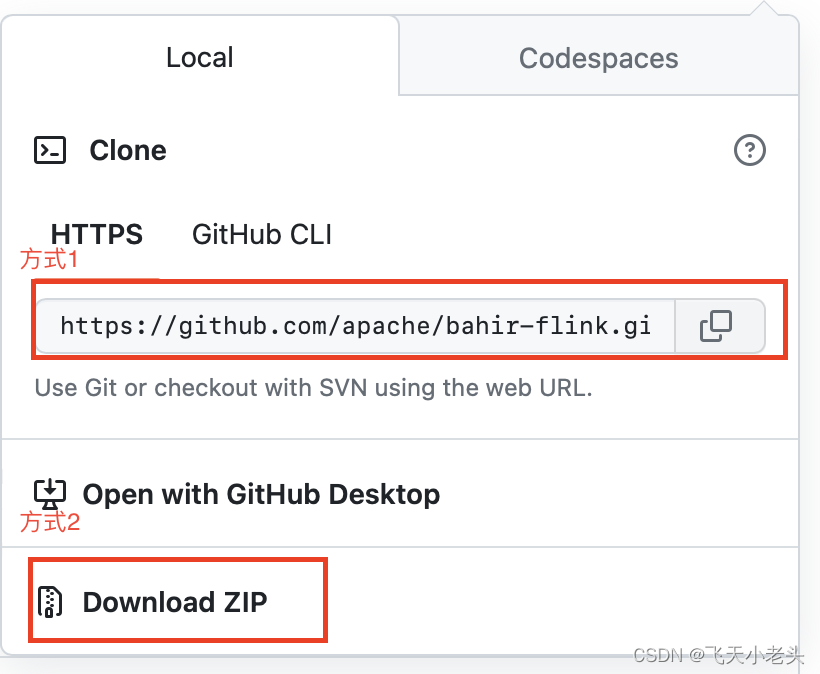
- 编译源码包
下载好源码后,maven会自动下载对应的依赖项- 删除不需要的子项目
因为我们这里需要编译redis对应的扩展包,所以其他的子项目都可以删除掉,下图中红色框标注的都可以删除
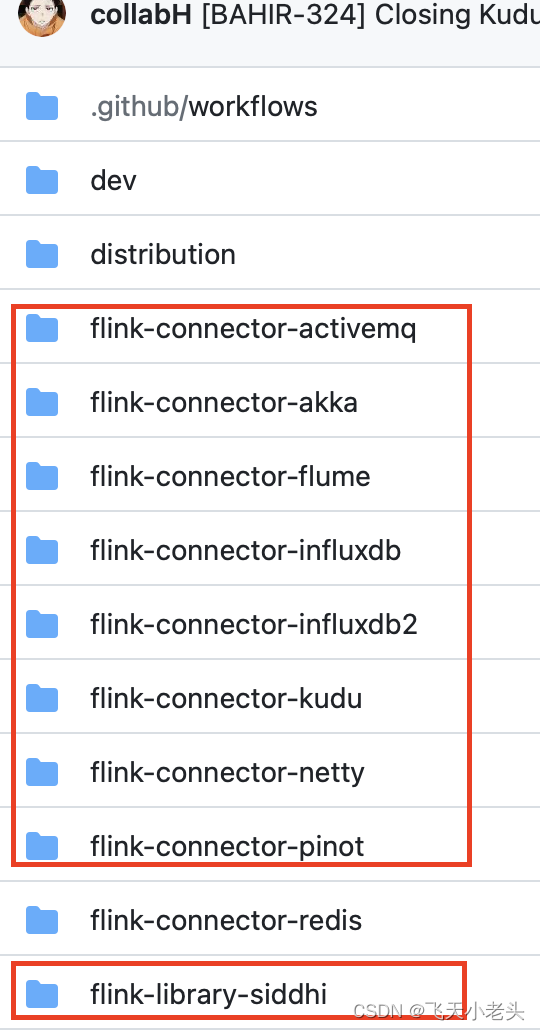
- 修改
pom文件
删除掉不需要的子项目后,在pom文件中也要删除对应的子项目配置
修改完成模块配置后,还需要修改对应的<!-- 这里只保留这一个模块就可以了 --> <modules> <module>flink-connector-redis</module> </modules>flink和scala版本依赖,这个根据自己实际的开发环境进行修改
这些都完成后就可以通过<properties> <!-- 修改这里的版本就可以 --> <!-- Flink version --> <flink.version>1.15.3</flink.version> <scala.binary.version>2.12</scala.binary.version> <scala.version>2.12.11</scala.version> </properties>maven下载对应的依赖了.
- 删除不需要的子项目
- 编译安装
依赖下载完成后pom文件中可能会有几处是报错的状态,如下图
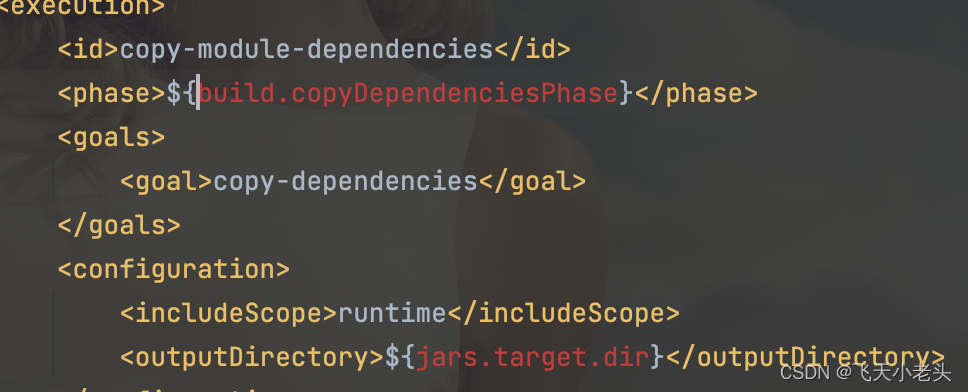
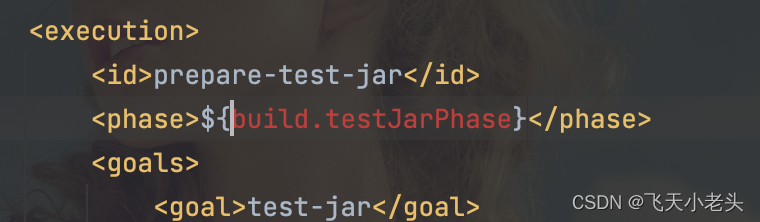
以上几处错误无需理会,不影响扩展包的编译.
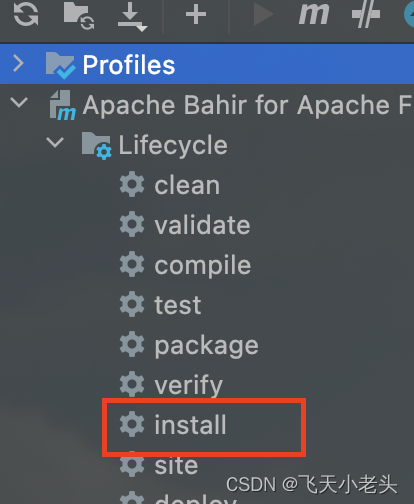
接下来通过maven的install将扩展包编译并安装到本地的maven资源库,如下图
编译完成后我们就可以在自己的flink项目中引入对应的扩展包了
上面依赖中<!-- Redis connector --> <dependency> <groupId>org.apache.bahir</groupId> <artifactId>flink-connector-redis</artifactId> <version>1.2-SNAPSHOT</version> </dependency>groupId是固定的,artifactId要根据flink-connector-redis项目中的pom文件中artifactId来拿,同样version也是一样,到这里扩展包的问题就已经解决了. - 代码
其实在GitHub上已经给了代码示例单机(java,scala)、集群(java,scala)的代码模板都是有的,下面就以单机redis作为示例.
这里我们要创建一个类实现RedisMapperimport org.apache.flink.api.java.tuple.Tuple2; import org.apache.flink.streaming.connectors.redis.common.mapper.RedisCommand; import org.apache.flink.streaming.connectors.redis.common.mapper.RedisCommandDescription; import org.apache.flink.streaming.connectors.redis.common.mapper.RedisMapper; /** * @Author: J * @Version: 1.0 * @CreateTime: 2023/8/4 * @Description: 测试 **/ public class RedisExampleMapper implements RedisMapper<Tuple2<String, String>> { @Override // 这个方法是选择使用哪种命令插入数据到Redis public RedisCommandDescription getCommandDescription() { return new RedisCommandDescription(RedisCommand.HSET, "HASH_NAME"); } @Override // 这个方法是选择哪个作为Key public String getKeyFromData(Tuple2<String, String> data) { return data.f0; } @Override // 这个方法是选择哪个作为Value public String getValueFromData(Tuple2<String, String> data) { return data.f1; } }
到这里代码就结束了,具体应用根据实际业务需求进行更改.import org.apache.flink.api.java.tuple.Tuple2; import org.apache.flink.streaming.api.datastream.DataStreamSource; import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator; import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment; import org.apache.flink.streaming.connectors.redis.RedisSink; import org.apache.flink.streaming.connectors.redis.common.config.FlinkJedisPoolConfig; /** * @Author: J * @Version: 1.0 * @CreateTime: 2023/8/4 * @Description: 测试 **/ public class FlinkRedisSink { public static void main(String[] args) throws Exception { // 构建流环境 StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); // 这里使用的是自定义数据源为了方便测试 DataStreamSource<CustomizeBean> customizeSource = env.addSource(new CustomizeSource()); // 将数据转换成Tuple的形式 SingleOutputStreamOperator<Tuple2<String, String>> tuple2Stream = customizeSource .map((MapFunction<CustomizeBean, Tuple2<String, String>>) value -> Tuple2.of(value.getAge() + "-" + value.getHobbit(), value.toString())) .returns(TypeInformation.of(new TypeHint<Tuple2<String, String>>() {}));// Tuple2是flink中提供的类型java无法自动推断,所以加上这段代码 // 配置Redis FlinkJedisPoolConfig conf = new FlinkJedisPoolConfig.Builder() .setHost("127.0.0.1") // redis服务器地址 .setPassword("password") // redis密码 .build(); // 添加Sink tuple2Stream.addSink(new RedisSink<Tuple2<String, String>>(conf, new RedisExampleMapper()); env.execute("Redis Sink"); } }















 1293
1293











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









