



 本文从源码角度剖析mustache模板引擎的工作原理,介绍其历史、基本使用方法,并通过实例讲解其核心机理。通过手写实现mustache库,探讨其在数据绑定中的关键角色,尤其是tokens的概念和作用。
本文从源码角度剖析mustache模板引擎的工作原理,介绍其历史、基本使用方法,并通过实例讲解其核心机理。通过手写实现mustache库,探讨其在数据绑定中的关键角色,尤其是tokens的概念和作用。
mustache模板引擎知识前置
说白了,本篇从源码的角度,给我讲明白,双花括号如何就能拿到指定的数值,并展示到视图。
一、什么是模板引擎
模板引擎是将数据要变为视图最优雅的解决方案
1.0 历史上曾经出现的数据变为视图的方法
纯DOM法:非常笨拙, 没有实战价值
数组join法:曾几何时非常流行, 是曾经的前端必会知识
ES6的反引号法:ES6中新增的`${a}`语法糖, 很好用
模板引擎:解决数据变为视图的最优雅的方法
1.1 数据变为视图-纯DOM法
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Document</title>
</head>
<body>
<ul id="list">
</ul>
<script> var arr = [
{ "name": "小明", "age": 12, "sex": "男" },
{ "name": "小红", "age": 11, "sex": "女" },
{ "name": "小强", "age": 13, "sex": "男" }
];
var list = document.getElementById('list');
for (var i = 0; i < arr.length; i++) {
// 每遍历一项,都要用DOM方法去创建li标签
let oLi = document.createElement('li');
// 创建hd这个div
let hdDiv = document.createElement('div');
hdDiv.className = 'hd';
hdDiv.innerText = arr[i].name + '的基本信息';
// 创建bd这个div
let bdDiv = document.createElement('div');
bdDiv.className = 'bd';
// 创建三个p
let p1 = document.createElement('p');
p1.innerText = '姓名:' + arr[i].name;
bdDiv.appendChild(p1);
let p2 = document.createElement('p');
p2.innerText = '年龄:' + arr[i].age;
bdDiv.appendChild(p2);
let p3 = document.createElement('p');
p3.innerText = '性别:' + arr[i].sex;
bdDiv.appendChild(p3);
// 创建的节点是孤儿节点,所以必须要上树才能被用户看见
oLi.appendChild(hdDiv);
// 创建的节点是孤儿节点,所以必须要上树才能被用户看见
oLi.appendChild(bdDiv);
// 创建的节点是孤儿节点,所以必须要上树才能被用户看见
list.appendChild(oLi);
} </script>
</body>
</html>
1.2 数据变为视图-数组join法
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Document</title>
</head>
<body>
<ul id="list"></ul>
<script> var arr = [
{ "name": "小明", "age": 12, "sex": "男" },
{ "name": "小红", "age": 11, "sex": "女" },
{ "name": "小强", "age": 13, "sex": "男" }
];
var list = document.getElementById('list');
// 遍历arr数组,每遍历一项,就以字符串的视角将HTML字符串添加到list中
for (let i = 0; i < arr.length; i++) {
list.innerHTML += [
'<li>',
' <div class="hd">' + arr[i].name + '的信息</div>',
' <div class="bd">',
' <p>姓名:' + arr[i].name + '</p>',
' <p>年龄:' + arr[i].age + '</p>',
' <p>性别:' + arr[i].sex + '</p>',
' </div>',
'</li>'
].join('')
} </script>
</body>
</html>
1.3 数据变为视图-ES6的反引号法
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Document</title>
</head>
<body>
<ul id="list"></ul>
<script> var arr = [
{ "name": "小明", "age": 12, "sex": "男" },
{ "name": "小红", "age": 11, "sex": "女" },
{ "name": "小强", "age": 13, "sex": "男" }
];
var list = document.getElementById('list');
// 遍历arr数组,每遍历一项,就以字符串的视角将HTML字符串添加到list中
for (let i = 0; i < arr.length; i++) {
list.innerHTML += `
<li>
<div class="hd">${arr[i].name}的基本信息</div>
<div class="bd">
<p>姓名:${arr[i].name}</p>
<p>性别:${arr[i].sex}</p>
<p>年龄:${arr[i].age}</p>
</div>
</li>
`;
} </script>
</body>
</html>
二、mustache的基本使用
• mustache官方git: github.com/janl/mustac…
• mustache是“胡子” 的意思, 因为它的嵌入标记{{ }}非常像胡子。没错, {{ }}的语法也被Vue沿用, 这就是我们学习mustache的原因。
• mustache是最早的模板引擎库, 比Vue诞生的早多了, 它的底层实现机理在当时是非常有创造性的、 轰动性的, 为后续模板引擎的发展提供了崭新的思路。
• 必须要引入mustache库, 可以在bootcdn.com上找到它。
• mustache的模板语法非常简单。
2.1 mustache基本使用-循环对象数组
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Document</title>
</head>
<body>
<div id="container"></div>
<!-- 模板 注意type不是text/javascript-->
<script type="text/template" id="mytemplate"> <ul> {{#arr}}<!-- 循环开始 -->
<li>
<div class="hd">{{name}}的基本信息</div>
<div class="bd">
<p>姓名:{{name}}</p>
<p>性别:{{sex}}</p>
<p>年龄:{{age}}</p>
</div>
</li> {{/arr}}<!-- 循环结束 -->
</ul> </script>
<script src="jslib/mustache.js"></script>
<script> var templateStr = document.getElementById('mytemplate').innerHTML;
var data = {
arr: [
{ "name": "小明", "age": 12, "sex": "男" },
{ "name": "小红", "age": 11, "sex": "女" },
{ "name": "小强", "age": 13, "sex": "男" }
]
};
var domStr = Mustache.render(templateStr, data);
var container = document.getElementById('container');
container.innerHTML = domStr; </script>
</body>
</html>
2.2 mustache基本使用-不循环
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Document</title>
</head>
<body>
<div id="container"></div>
<script src="jslib/mustache.js"></script>
<script> var templateStr = `
<h1>我买了一个{{thing}},好{{mood}}啊</h1>
`;
var data = {
thing: '华为手机',
mood: '开心'
};
var domStr = Mustache.render(templateStr, data);
var container = document.getElementById('container');
container.innerHTML = domStr; </script>
</body>
</html>
2.3 mustache基本使用-循环简单数组
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Document</title>
</head>
<body>
<div id="container"></div>
<script src="jslib/mustache.js"></script>
<script> var templateStr = `
<ul>
{{#arr}}
<li>{{.}}</li>
{{/arr}}
</ul>
`;
var data = {
arr: ['A', 'B', 'C']
};
var domStr = Mustache.render(templateStr, data);
var container = document.getElementById('container');
container.innerHTML = domStr; </script>
</body>
</html>
2.4 mustache基本使用-数组的嵌套情况
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Document</title>
</head>
<body>
<div id="container"></div>
<script src="jslib/mustache.js"></script>
<script> var templateStr = `
<ul>
{{#arr}}
<li>
{{name}}的爱好是:
<ol>
{{#hobbies}}
<li>{{.}}</li>
{{/hobbies}}
</ol>
</li>
{{/arr}}
</ul>
`;
var data = {
arr: [
{'name': '小明', 'age': 12, 'hobbies': ['游泳', '羽毛球']},
{'name': '小红', 'age': 11, 'hobbies': ['编程', '写作文', '看报纸']},
{'name': '小强', 'age': 13, 'hobbies': ['打台球']},
]
};
var domStr = Mustache.render(templateStr, data);
var container = document.getElementById('container');
container.innerHTML = domStr; </script>
</body>
</html>
2.5 mustache基本使用-布尔值
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Document</title>
</head>
<body>
<div id="container"></div>
<script src="jslib/mustache.js"></script>
<script> var templateStr = ` {{#m}} <h1>你好</h1> {{/m}} `;
var data = {
m: false <!-- true时看得见 -->
};
var domStr = Mustache.render(templateStr, data);
var container = document.getElementById('container');
container.innerHTML = domStr; </script>
</body>
</html>
三、mustache的底层核心机理
3.1 mustache库不能用简单的正则表达式思路实现

3.2 演示一下正则表达式实现简单模板数据填充
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Document</title>
</head>
<body>
<script> var templateStr = '<h1>我买了一个{{thing}},花了{{money}}元,好{{mood}}</h1>';
var data = {
thing: '白菜',
money: 5,
mood: '激动'
};
// 最简单的模板引擎的实现机理,利用的是正则表达式中的replace()方法。
// replace()的第二个参数可以是一个函数,这个函数提供捕获的东西的参数,就是$1
// 结合data对象,即可进行智能的替换
function render(templateStr, data) {
return templateStr.replace(/\{\{(\w+)\}\}/g, function (findStr, $1) {
return data[$1];
});
}
var result = render(templateStr, data);
console.log(result); </script>
</body>
</html>
3.3 mustache库的机理
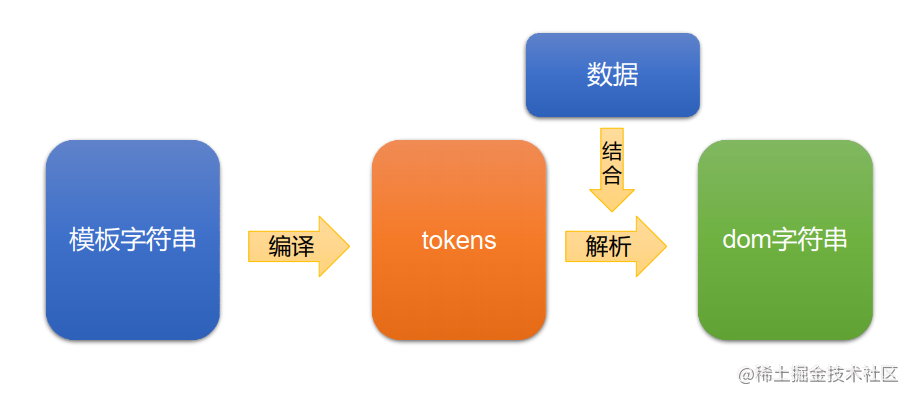
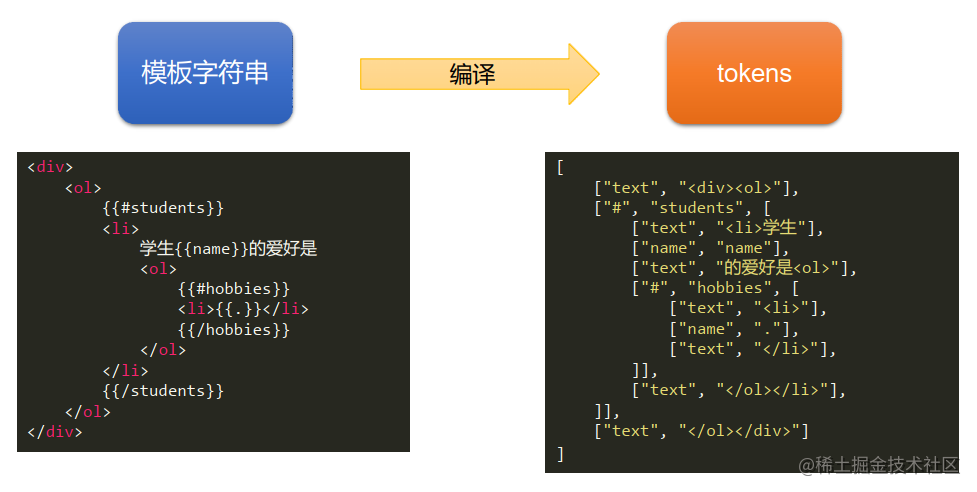
3.4 什么是tokens?



3.5 mustache库底层重点要做两个事情
- 将模板字符串编译为tokens形式
- 将tokens结合数据, 解析为dom字符串
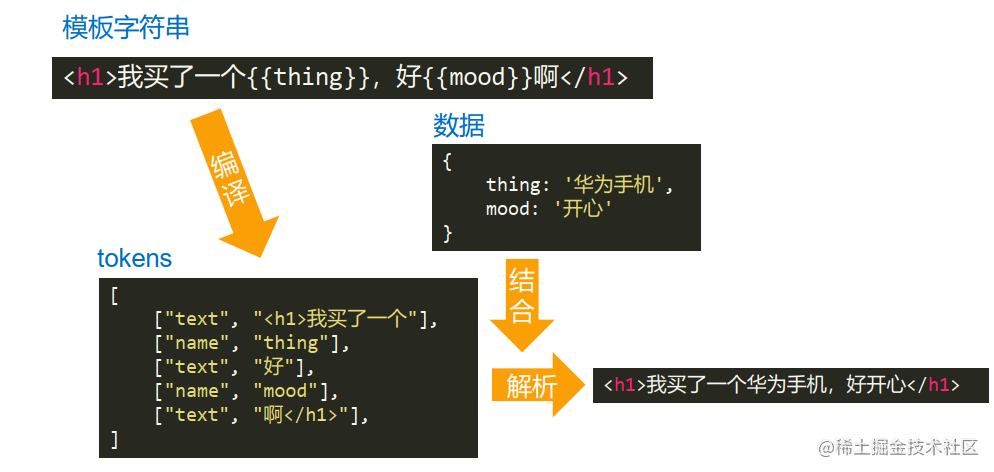
3.6 观察一下tokens
说白了,就是遇到花括号,算一组
<!-- 这里看视频更好些,看清楚[[]] 里面的划分-->
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Document</title>
</head>
<body>
<script src="jslib/mustache.js"></script>
<script> var templateStr1 = `
<ul> {{#arr}} <li>
<div class="hd">{{name}}的基本信息</div>
<div class="bd">
<p>姓名:{{name}}</p>
<p>性别:{{sex}}</p>
<p>年龄:{{age}}</p>
</div>
</li> {{/arr}} </ul>
`;
var templateStr2 = `
<ul> {{#arr}} <li> {{name}}的爱好是:
<ol> {{#hobbies}} <li>{{.}}</li> {{/hobbies}} </ol>
</li> {{/arr}} </ul>
`;
Mustache.render(templateStr2, {}); </script>
</body>
</html>
带你手写实现mustache库
一、使用webpack和webpack-dev-server构建
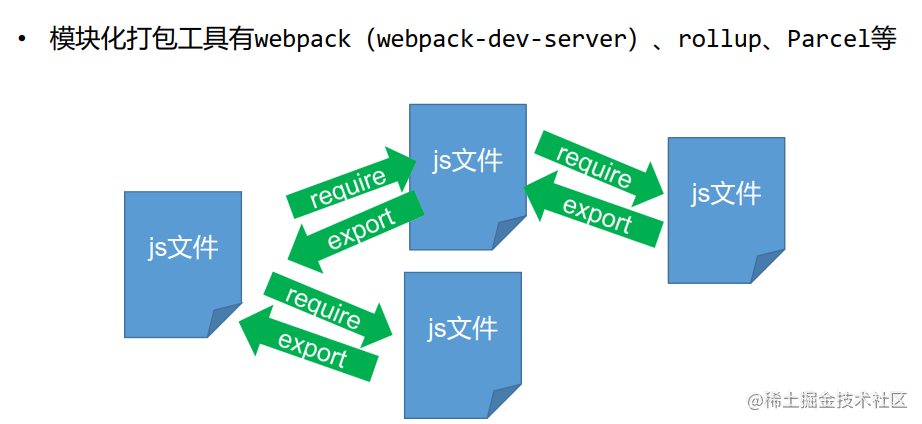
• 模块化打包工具(亦称构建工具)有webpack(webpack-dev-server) 、 rollup、 Parcel等
• mustache官方库使用rollup进行模块化打包, 而我们今天使用webpack
(webpack-dev-server) 进行模块化打包, 这是因为webpack(webpackdev-server) 能让我们更方便地在浏览器中(而不是nodejs环境中) 实时调试程序, 相比nodejs控制台, 浏览器控制台更好用, 比如能够点击展开数组的每项。
• 生成库是UMD的, 这意味着它可以同时在nodejs环境中使用, 也可以在浏览器环境中使用。 实现UMD不难, 只需要一个“通用头” 即可。
• 模块化打包工具有webpack(webpack-dev-server) 、 rollup、 Parcel等
 [外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-F9GQ36Q5-1656422889283)(https://p9-juejin.byteimg.com/tos-cn-i-k3u1fbpfcp/e0efc54094c24fbf9e8b3201584748a5~tplv-k3u1fbpfcp-zoom-in-crop-mark:1956:0:0:0.image?)]
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-F9GQ36Q5-1656422889283)(https://p9-juejin.byteimg.com/tos-cn-i-k3u1fbpfcp/e0efc54094c24fbf9e8b3201584748a5~tplv-k3u1fbpfcp-zoom-in-crop-mark:1956:0:0:0.image?)]
webpack.config.js文件

• 学习源码时, 源码思想要借鉴, 而不要抄袭。 要能够发现源码中书写的精彩的地方;
• 将独立的功能拆写为独立的js文件中完成, 通常是一个独立的类, 每个单独的功能必须能独立的“单元测试” ;
• 应该围绕中心功能, 先把主干完成, 然后修剪枝叶;
• 功能并不需要一步到位, 功能的拓展要一步步完成, 有的非核心功能甚至不需实现;
1.1 创建项目、环境配置
步骤:
新建一个空文件夹
vscode打开
npm init
npm i -D webpack@4 webpack-dev-server@3 webpack-cli@3
新建webpack.config.js文件,自己配
//package.json
{
"name": "sgg_templateengine",
"version": "1.0.0",
"description": "",
"main": "index.js",
"scripts": {
//npm run dev 就可跑起来了
"dev": "webpack-dev-server"
},
"author": "",
"license": "ISC",
"devDependencies": {
"webpack": "^4.44.2",
"webpack-cli": "^3.3.12",
"webpack-dev-server": "^3.11.0"//如果报错,就全局装一下这个webpack-dev-server
}
}
//webpack.config.js
const path = require('path');
module.exports = {
// 模式,开发
mode: 'development',
// 入口
entry: './src/index.js',
// 打包到什么文件
output: {
filename: 'bundle.js'
},
// 配置一下webpack-dev-server
devServer: {
// 静态文件根目录 即www/index.html页面
// 以后项目中,路径不一定要一样,知道怎么配,这是干什么的才行
contentBase: path.join(__dirname, "www"),
// 不压缩
compress: false,
// 端口号
port: 8080,
// 虚拟打包的路径,bundle.js文件没有真正的生成
publicPath: "/xuni/"
}
};
1.2 手写实现scanner类
/*
扫描器类
*/
export default class Scanner {
constructor(templateStr) {
// 将模板字符串写到实例身上
this.templateStr = templateStr;
// 指针
this.pos = 0;
// 尾巴,一开始就是模板字符串原文
this.tail = templateStr;
}
// 功能弱,就是走过指定内容,没有返回值
scan(tag) {
if (this.tail.indexOf(tag) == 0) {
// tag有多长,比如{{长度是2,就让指针后移多少位
this.pos += tag.length;
// 尾巴也要变,改变尾巴为从当前指针这个字符开始,到最后的全部字符
this.tail = this.templateStr.substring(this.pos);
}
}
// 让指针进行扫描,直到遇见指定内容结束,并且能够返回结束之前路过的文字
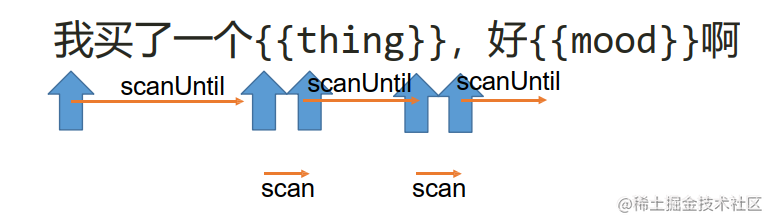
scanUtil(stopTag) {
// 记录一下执行本方法的时候pos的值
const pos_backup = this.pos;
// 当尾巴的开头不是stopTag的时候,就说明还没有扫描到stopTag
// 写&&很有必要,因为防止找不到,那么寻找到最后也要停止下来
while (!this.eos() && this.tail.indexOf(stopTag) != 0) {
this.pos++;
// 改变尾巴为从当前指针这个字符开始,到最后的全部字符
this.tail = this.templateStr.substring(this.pos);
}
return this.templateStr.substring(pos_backup, this.pos);
}
// 指针是否已经到头,返回布尔值。end of string
eos() {
return this.pos >= this.templateStr.length;
}
};
1.2 手写将HTML变为Tokens,将零散的Tokens嵌套起来

// src/parseTemplateToTokens.js
import Scanner from './Scanner.js';
import nestTokens from './nestTokens.js';
/*
将模板字符串变为tokens数组
*/
export default function parseTemplateToTokens(templateStr) {
var tokens = [];
// 创建扫描器
var scanner = new Scanner(templateStr);
var words;
// 让扫描器工作
while (!scanner.eos()) {
// 收集开始标记出现之前的文字
words = scanner.scanUtil('{{');
if (words != '') {
// 尝试写一下去掉空格,智能判断是普通文字的空格,还是标签中的空格
// 标签中的空格不能去掉,比如<div class="box">不能去掉class前面的空格
let isInJJH = false;
// 空白字符串
var _words = '';
for (let i = 0; i < words.length; i++) {
// 判断是否在标签里
if (words[i] == '<') {
isInJJH = true;
} else if (words[i] == '>') {
isInJJH = false;
}
// 如果这项不是空格,拼接上
if (!/\s/.test(words[i])) {
_words += words[i];
} else {
// 如果这项是空格,只有当它在标签内的时候,才拼接上
if (isInJJH) {
_words += ' ';
}
}
}
// 存起来,去掉空格
tokens.push(['text', _words]);
}
// 过双大括号
scanner.scan('{{');
// 收集开始标记出现之前的文字
words = scanner.scanUtil('}}');
if (words != '') {
// 这个words就是{{}}中间的东西。判断一下首字符
if (words[0] == '#') {
// 存起来,从下标为1的项开始存,因为下标为0的项是#
tokens.push(['#', words.substring(1)]);
} else if (words[0] == '/') {
// 存起来,从下标为1的项开始存,因为下标为0的项是/
tokens.push(['/', words.substring(1)]);
} else {
// 存起来
tokens.push(['name', words]);
}
}
// 过双大括号
scanner.scan('}}');
}
// 返回折叠收集的tokens
return nestTokens(tokens);
}
// src/nestTokens.js
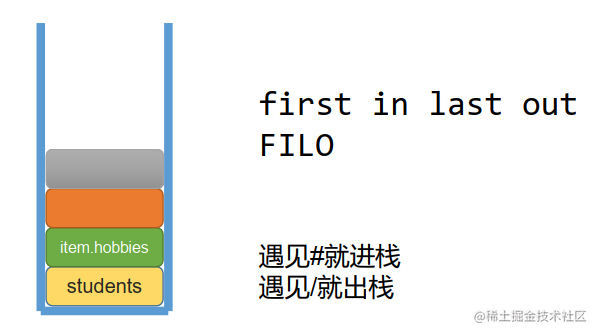
/*
函数的功能是折叠tokens,将#和/之间的tokens能够整合起来,作为它的下标为3的项
*/
export default function nestTokens(tokens) {
// 结果数组
var nestedTokens = [];
// 栈结构,存放小tokens,栈顶(靠近端口的,最新进入的)的tokens数组中当前操作的这个tokens小数组
var sections = [];
// 收集器,天生指向nestedTokens结果数组,引用类型值,所以指向的是同一个数组
// 收集器的指向会变化,当遇见#的时候,收集器会指向这个token的下标为2的新数组
var collector = nestedTokens;
for (let i = 0; i < tokens.length; i++) {
let token = tokens[i];
switch (token[0]) {
case '#':
// 收集器中放入这个token
collector.push(token);
// 入栈
sections.push(token);
// 收集器要换人。给token添加下标为2的项,并且让收集器指向它
collector = token[2] = [];
break;
case '/':
// 出栈。pop()会返回刚刚弹出的项
sections.pop();
// 改变收集器为栈结构队尾(队尾是栈顶)那项的下标为2的数组
collector = sections.length > 0 ? sections[sections.length - 1][2] : nestedTokens;
break;
default:
// 甭管当前的collector是谁,可能是结果nestedTokens,也可能是某个token的下标为2的数组,甭管是谁,推入collctor即可。
collector.push(token);
}
}
return nestedTokens;
};
1.3 手写将tokens注入数据,解析为dom字符串
// src/renderTemplate.js
import lookup from './lookup.js';
import parseArray from './parseArray.js';
/*
函数的功能是让tokens数组变为dom字符串
*/
export default function renderTemplate(tokens, data) {
// 结果字符串
var resultStr = '';
// 遍历tokens
for (let i = 0; i < tokens.length; i++) {
let token = tokens[i];
// 看类型
if (token[0] == 'text') {
// 拼起来
resultStr += token[1];
} else if (token[0] == 'name') {
// 如果是name类型,那么就直接使用它的值,当然要用lookup
// 因为防止这里是“a.b.c”有逗号的形式
resultStr += lookup(data, token[1]);
} else if (token[0] == '#') {
resultStr += parseArray(token, data);
}
}
return resultStr;
}

// src/lookup.js
/*
功能是可以在dataObj对象中,寻找用连续点符号的keyName属性
比如,dataObj是
{
a: {
b: {
c: 100
}
}
}
那么lookup(dataObj, 'a.b.c')结果就是100
不忽悠大家,这个函数是某个大厂的面试题
*/
export default function lookup(dataObj, keyName) {
// 看看keyName中有没有点符号,但是不能是.本身
if (keyName.indexOf('.') != -1 && keyName != '.') {
// 如果有点符号,那么拆开
var keys = keyName.split('.');
// 设置一个临时变量,这个临时变量用于周转,一层一层找下去。
var temp = dataObj;
// 每找一层,就把它设置为新的临时变量
for (let i = 0; i < keys.length; i++) {
temp = temp[keys[i]];
}
return temp;
}
// 如果这里面没有点符号
return dataObj[keyName];
};
// src/parseArray.js
import lookup from './lookup.js';
import renderTemplate from './renderTemplate.js';
/*
处理数组,结合renderTemplate实现递归
注意,这个函数收的参数是token!而不是tokens!
token是什么,就是一个简单的['#', 'students', [
]]
这个函数要递归调用renderTemplate函数,调用多少次???
千万别蒙圈!调用的次数由data决定
比如data的形式是这样的:
{
students: [
{ 'name': '小明', 'hobbies': ['游泳', '健身'] },
{ 'name': '小红', 'hobbies': ['足球', '蓝球', '羽毛球'] },
{ 'name': '小强', 'hobbies': ['吃饭', '睡觉'] },
]
};
那么parseArray()函数就要递归调用renderTemplate函数3次,因为数组长度是3
*/
export default function parseArray(token, data) {
// 得到整体数据data中这个数组要使用的部分
var v = lookup(data, token[1]);
// 结果字符串
var resultStr = '';
// 遍历v数组,v一定是数组
// 注意,下面这个循环可能是整个包中最难思考的一个循环
// 它是遍历数据,而不是遍历tokens。数组中的数据有几条,就要遍历几条。
for(let i = 0 ; i < v.length; i++) {
// 这里要补一个“.”属性
// 拼接
resultStr += renderTemplate(token[2], {
...v[i],
'.': v[i]
});
}
return resultStr;
};
// www/index.html
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Document</title>
</head>
<body>
<div id="container"></div>
<script src="/xuni/bundle.js"></script>
<script> // 模板字符串
var templateStr = `
<div>
<ul>
{{#students}}
<li class="myli">
学生{{name}}的爱好是
<ol>
{{#hobbies}}
<li>{{.}}</li>
{{/hobbies}}
</ol>
</li>
{{/students}}
</ul>
</div>
`;
// 数据
var data = {
students: [
{ 'name': '小明', 'hobbies': ['编程', '游泳'] },
{ 'name': '小红', 'hobbies': ['看书', '弹琴', '画画'] },
{ 'name': '小强', 'hobbies': ['锻炼'] }
]
};
// 调用render
var domStr = SSG_TemplateEngine.render(templateStr, data);
console.log(domStr);
// 渲染上树
var container = document.getElementById('container');
container.innerHTML = domStr; </script>
</body>
</html>
// src/index.js
import parseTemplateToTokens from './parseTemplateToTokens.js';
import renderTemplate from './renderTemplate.js';
// 全局提供SSG_TemplateEngine对象
window.SSG_TemplateEngine = {
// 渲染方法
render(templateStr, data) {
// 调用parseTemplateToTokens函数,让模板字符串能够变为tokens数组
var tokens = parseTemplateToTokens(templateStr);
// 调用renderTemplate函数,让tokens数组变为dom字符串
var domStr = renderTemplate(tokens, data);
return domStr;
}
};


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









