







 超级会员免费看
超级会员免费看
 本文深入探讨了Spark中的一个常见问题,即`spark.driver.maxResultSize`超限。当序列化结果超过该配置设定的值时,作业会因内存异常而失败。文章解释了序列化的概念,`spark.driver.maxResultSize`的作用,以及它与`driver-memory`的区别。提出了增大`spark.driver.maxResultSize`作为直接解决方案,并引发了关于是否应将大量数据拉取到driver节点的思考。
本文深入探讨了Spark中的一个常见问题,即`spark.driver.maxResultSize`超限。当序列化结果超过该配置设定的值时,作业会因内存异常而失败。文章解释了序列化的概念,`spark.driver.maxResultSize`的作用,以及它与`driver-memory`的区别。提出了增大`spark.driver.maxResultSize`作为直接解决方案,并引发了关于是否应将大量数据拉取到driver节点的思考。
Bug信息
org.apache.spark.SparkException: Job aborted due to stage failure: Total size of serialized results of x tasks (y MB) is bigger
than spark.driver.maxResultSize (z MB)
Bug本质
程序返回给driver端的序列化数据大小超过了spark.driver.maxResultSize的限制,默认该值为1GB。
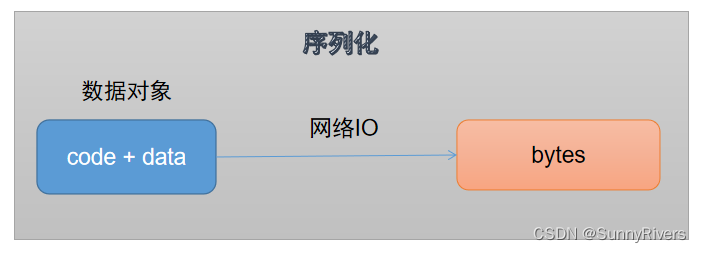
什么是序列化
序列化是在网络传输过程中将数据对象转换为一系列字节的处理。在我们的Spark场景中,executor之间或driver和executor之间的数据传输是通过序列化数据进行的。
spark.driver.maxResultSize
根据Spark官方文档,Spark.driver.maxResultSize定义了驱动程序可以为每个Spark收集操作存储的序列化结果总大小的最大限制(数据以字节为单位)。有时,此属性也有助于Spark应用程序的

 订阅专栏 解锁全文
订阅专栏 解锁全文



















 8171
8171

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











