









前言
我们在建表的时候关于字段类型的选择会有这么几类人:
- 严谨型
严格调研每个字段可能的大小,然后根据不同字段类型的限制,进行选择,这一类人在创建关系型数据表的时候是没有问题的。 - 图自己省事型
把所有字段都设置为String,这样他可以一股脑的把所有数据导入进来。这种人在用关系型数据库(如mysql)的时候,会被骂死,在大数据(如hive)中,可能ODS层这么搞,原则上是可行,毕竟还有建模的时候可以处理这些数据类型,但是建模的人也会抱怨。 - 根据不同场景进行甄别型
(1)大数据领域
由于大数据字段类型差异带来性能影响远远无法和数据量相提并论,因此不需要那么严谨。
(2)关系型数据库
需要尽可能给用户带来极致的体验,字段类型尽可能要选择合理。
常用的字段类型
| 数据类型 | 描述 |
|---|---|
| TINYINT | 1-byte signed integer, from -128 to 127 |
| SMALLINT | 2-byte signed integer, from -32,768 to 32,767 |
| INT/INTEGER | 4-byte signed integer, from -2,147,483,648 to 2,147,483,647 |
| BIGINT | 8-byte signed integer, from -9,223,372,036,854,775,808 to 9,223,372,036,854,775,807 |
| FLOAT | 4-byte single precision floating point number |
| DOUBLE | 8-byte double precision floating point number |
| DECIMAL | Hive中的DECIMAL类型基于Java的BigDecimal,用于在Java中表示不可变的任意精度十进制数。所有常规的数值操作(例如+、-、*、/)和相关的UDF(例如Floor、Ceil、Round等)都可以处理DECIMAL类型。您可以像处理其他数值类型一样,对DECIMAL类型进行类型转换。DECIMAL类型的持久化格式同时支持科学计数法和非科学计数法。因此,无论您的数据集包含类似4.004E+3(科学计数法)还是4004(非科学计数法)或两者的组合的数据,都可以使用DECIMAL来处理。 |
| STRING | 字符串,变长,字符串文字可以用单引号(')或双引号(“)表示 |
| VARCHAR | Varchar类型在创建时需要指定长度(在1到65535之间),它定义了字符字符串中允许的最大字符数。如果转换/分配给varchar值的字符串值超过了长度指定值,那么该字符串将被静默截断 |
| CHAR | 字符类型(Char types)与Varchar类似,但它们的长度是固定的,这意味着短于指定长度值的值会用空格填充,但在比较时尾部空格并不重要。最大长度固定在255 |
| TIMESTAMP | 支持具有可选纳秒精度的传统UNIX时间戳 |
| DATE | DATE值描述特定的年/月/日,格式为YYYY-MM-DD。例如,日期为“2013年01月01日”。日期类型没有一天中的时间组件。Date类型支持的值范围为0000-01-01到9999-12-31,这取决于原始Java Date类型的支持 |
| BOOLEAN | true/false |
| INTERVAL | 时间频率间隔 |
| ARRAY | 有序的的同类型的集合 |
| MAP | key-value,key必须为原始类型,value可以任意类型 |
| STRUCT | 字段集合,类型可以不同 |
| UNION | 在有限取值范围内的一个值 |
大数据(Hive)字段类型选择
数据仓库Hive中的字段长度尽量满足相应源系统字段中最大长度的要求,当然也会考虑字段的业务含义,对于一些源系统定义过长,而从实际业务含义又不可能有那么长的字段,由仓库自行选择一个合适的长度定义;为了尽可能的保持仓库中数据类型的一致性以及规范性,数据仓库中的数据类型定义不宜过杂,建议只定义string、bigint、double类型,使得仓库中的字段类型保持整齐。
关系型数据库(Mysql)字段类型选择
- 原则
尽可能选择合适的类型。比如某个字段只有0和1,那么绝对是tinyint优先于int。 - tinyint和int性能
- 存储空间
INT字段占用4个字节,而TINYINT字段只占用1个字节。因此,如果你的数据量较大,使用TINYINT可以节省存储空间,减少磁盘IO的开销。 - 内存消耗
INT字段存储时会占用更多的内存空间,如果表中有很多INT字段,并且数据量较大,会增加MySQL服务器的内存消耗。 - 索引效率
使用TINYINT字段来创建索引会比使用INT字段创建索引效率更高。因为在索引建立和查询过程中,TINYINT占用的空间小,可以减少IO操作次数,提高查询效率。 - 运算和比较速度
INT字段相较于TINYINT字段在运算和比较操作上可能稍微慢一些,因为需要处理更多的字节。
如果你的数据范围可以在TINYINT的取值范围内(-128到127或0到255),并且对存储空间和索引效率有较高的要求,使用TINYINT字段会更合适。如果数据范围超出了TINYINT的取值范围,或者对于内存消耗和运算速度要求更高,可以考虑使用INT字段。
- int(1)和int(10)有什么区别
INT(1)和INT(10)实际上并没有区别。在MySQL中,当定义整数类型(如INT)时,括号中的数字表示显示宽度,而不是存储大小或值的范围。
显示宽度只影响在查询结果集中显示的值的宽度。例如,如果你使用INT(10),并在查询结果中有一个值为123,那么它仍然会显示为123,而不是用前导零填充到10位。显示宽度不会限制值的范围或存储大小。
实际上,对于整数类型,如INT,存储大小和值的范围是由类型本身确定的,而不是显示宽度。INT类型总是使用4个字节(32位)的存储空间,并且值的范围始终是从-2147483648到2147483647(有符号)或从0到4294967295(无符号)。
因此,无论使用INT(1)还是INT(10),它们的存储大小和值的范围都是相同的。选择适当的显示宽度只是为了在查询结果中更好地格式化显示的值。
总结起来,INT(1)和INT(10)在MySQL 8中没有实际的区别,它们只是用于指定查询结果中显示的值的宽度。
为了更加直观的理解:
-
建一张表:
create table intVsIntAnyThingDemo ( Number1 int(1) unsigned zerofill, Number int(8) unsigned zerofill );建表语句详解:
在MySQL中,unsigned 和 zerofill 是两种属性,它们可以用来修饰整数类型(如 int)。
unsigned: 表示该字段只能存储非负整数。也就是说,这个字段不能存储负数。
zerofill: 表示如果值的位数小于指定的整数位数,那么在这个值的左侧填充零。
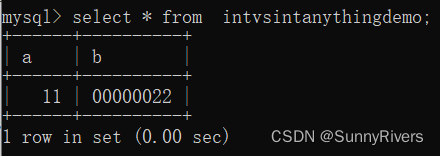
对于字段 Number1 int(1) unsigned zerofill,由于指定了int(1),这意味着这个字段只能显示一位数字。但由于使用了unsigned zerofill,当你插入一个数字时,它会自动被填充为两位数。例如,插入5会变成05。
对于字段 Number int(8) unsigned zerofill,它可以显示8位数字。所以,插入42会变成00000042。
总结:在这个例子中,unsigned确保了字段只存储非负数,而zerofill确保字段在显示时,如果实际数字位数小于指定的位数,那么会在左侧填充零。但需要注意的是,尽管显示上似乎Number1只能存储0到9的数字,但实际上由于其unsigned属性,它可以存储从0到255的整数值。这是因为int(1)在无符号的情况下,仍然按照整数的底层存储来对待,其范围是0到255。 -
插入数据
insert into intVsIntAnyThingDemo values(11,22);
- 查看数据















 8355
8355











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











