







Hyperledger Fabric性能优化
由于最近在做Fabric方向的研究课题,读到一篇文章对于Fabric性能的优化提出了非常好的建议与算法。文章名称《Blurring the Lines between Blockchains andDatabase Systems: the Case of Hyperledger Fabric》,来自顶会Sigmod,附上下载链接,如果想细读,可自行下载。
链接: https://pan.baidu.com/s/1xE-xzyzxAe8COwLd-vqerw .
链接: 密码: j3o8
提出问题
(1)Fabric这样的系统与经典的分布式数据库系统之间,究竟存在哪些概念上的相似和差异?
(2)是否有可能通过将技术从数据库过渡到区块链,从而进一步模糊这两种类型系统之间的界限,进而提高Fabric性能?
实验
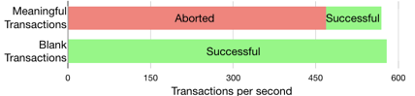
实验一:提交一组有意义的交易,这些交易源于资产传输场景,并报告了吞吐量,划分为中止的交易和成功的交易。这项揭示了Fabric的一个严重的问题:大量的交易最终都被中止了。中止的原因是交易发生冲突,这是并发执行的一个副作用。
解决方法:(a)增加系统的总吞吐量(b)将Fabric中止的交易转为成功的交易
实验二:提交没有任何逻辑的空白交易,空白的和有意义的交易的总吞吐量基本上是相等的,表明系统的吞吐量并不是由交易处理的核心组件控制的,而是由其他辅助因素控制的
Fabric交易处理流程
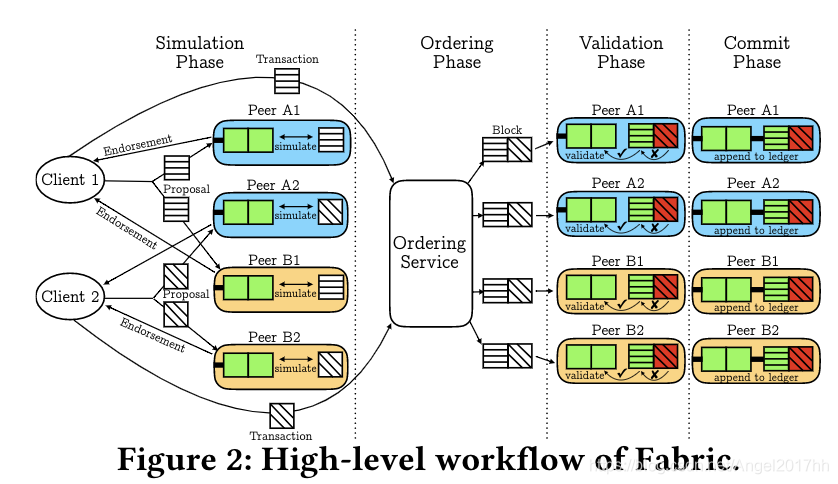
1、模拟阶段:客户端将交易提案发送给peer节点模拟交易,因为组织之间并不互相信任,所以每个组织至少有一个peer节点来模拟,模拟完成后将读写集和对提案的签名返回给客户端,客户端形成实际交易并发送给order节点;
2、排序阶段:排序节点将客户端发送来的交易经过排序后打包成块提交给peer节点进行验证,Fabric一般以交易到达顺序排序,不以任何方式检查语义,不能保证所有peer节点在同一时刻接收到区块,但能保证所有peer节点从order节点接收到的区块内的交易顺序是一样的;
3、验证阶段:验证交易是否遵守背书策略,验证交易是否发生冲突;
4、提交阶段:所有peer节点更新当前状态,并将包含有效和无效的交易的区块写入账本
交易中止、转为成功
一、交易重排序
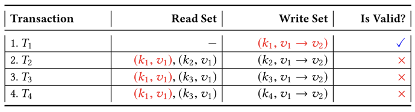
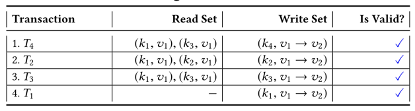
由于T2、T3、T4在模拟期间都读取v1版本中的k1,因此它们没有机会提交,因为它们使用的是k1的过期版本。在验证阶段它们被识别为无效交易,相应的交易提案必须由客户端重新提交,重新模拟->排序->验证->提交。交易重排序后:
交易重排序算法伪代码:
func reordering(Transaction[] S){
//step1:为S中的每个交易建立一个buildConflictGraph()函数来检查读写集并建立一个冲突图
Graph cg=buildConflictGraph(S)
//step2:在冲突图中,必须识别出所有环。我们用divideIntoSubgraphs(cg)方法将cg划分出最强连通子图
Graph[] cg_subgraphs=divideIntoSu 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









