







编写MR程序,让其可以适合大部分的HBase表数据导入到HBase表数据。其中包括可以设置版本数、可以设置输入表的列导入设置(选取其中某几列)、可以设置输出表的列导出设置(选取其中某几列)。
原始表test1数据如下:

每个row key都有两个版本的数据,这里只显示了row key为1的数据
在hbase shell 中创建数据表:
create 'test2',{NAME => 'cf1',VERSIONS => 10} // 保存无版本、无列导入设置、无列导出设置的数据
create 'test3',{NAME => 'cf1',VERSIONS => 10} // 保存无版本、无列导入设置、有列导出设置的数据
create 'test4',{NAME => 'cf1',VERSIONS => 10} // 保存无版本、有列导入设置、无列导出设置的数据
create 'test5',{NAME => 'cf1',VERSIONS => 10} // 保存有版本、无列导入设置、无列导出设置的数据
create 'test6',{NAME => 'cf1',VERSIONS => 10} // 保存有版本、无列导入设置、有列导出设置的数据
create 'test7',{NAME => 'cf1',VERSIONS => 10} // 保存有版本、有列导入设置、无列导出设置的数据
create 'test8',{NAME => 'cf1',VERSIONS => 10} // 保存有版本、有列导入设置、有列导出设置的数据
package GeneralHBaseToHBase;
import org.apache.hadoop.util.ToolRunner;
public class DriverTest {
public static void main(String[] args) throws Exception {
// 无版本设置、无列导入设置,无列导出设置
String[] myArgs1= new String[]{
"test1", // 输入表
"test2", // 输出表
"0", // 版本大小数,如果值为0,则为默认从输入表导出最新的数据到输出表
"-1", // 列导入设置,如果为-1 ,则没有设置列导入
"-1" // 列导出设置,如果为-1,则没有设置列导出
};
ToolRunner.run(HBaseDriver.getConfiguration(),
new HBaseDriver(),
myArgs1);
// 无版本设置、有列导入设置,无列导出设置
String[] myArgs2= new String[]{
"test1",
"test3",
"0",
"cf1:c1,cf1:c2,cf1:c10,cf1:c11,cf1:c14",
"-1"
};
ToolRunner.run(HBaseDriver.getConfiguration(),
new HBaseDriver(),
myArgs2);
// 无版本设置,无列导入设置,有列导出设置
String[] myArgs3= new String[]{
"test1",
"test4",
"0",
"-1",
"cf1:c1,cf1:c10,cf1:c14"
};
ToolRunner.run(HBaseDriver.getConfiguration(),
new HBaseDriver(),
myArgs3);
// 有版本设置,无列导入设置,无列导出设置
String[] myArgs4= new String[]{
"test1",
"test5",
"2",
"-1",
"-1"
};
ToolRunner.run(HBaseDriver.getConfiguration(),
new HBaseDriver(),
myArgs4);
// 有版本设置、有列导入设置,无列导出设置
String[] myArgs5= new String[]{
"test1",
"test6",
"2",
"cf1:c1,cf1:c2,cf1:c10,cf1:c11,cf1:c14",
"-1"
};
ToolRunner.run(HBaseDriver.getConfiguration(),
new HBaseDriver(),
myArgs5);
// 有版本设置、无列导入设置,有列导出设置
String[] myArgs6= new String[]{
"test1",
"test7",
"2",
"-1",
"cf1:c1,cf1:c10,cf1:c14"
};
ToolRunner.run(HBaseDriver.getConfiguration(),
new HBaseDriver(),
myArgs6);
// 有版本设置、有列导入设置,有列导出设置
String[] myArgs7= new String[]{
"test1",
"test8",
"2",
"cf1:c1,cf1:c2,cf1:c10,cf1:c11,cf1:c14",
"cf1:c1,cf1:c10,cf1:c14"
};
ToolRunner.run(HBaseDriver.getConfiguration(),
new HBaseDriver(),
myArgs7);
}
}
package GeneralHBaseToHBase;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.hbase.client.Put;
import org.apache.hadoop.hbase.client.Scan;
import org.apache.hadoop.hbase.io.ImmutableBytesWritable;
import org.apache.hadoop.hbase.mapreduce.TableMapReduceUtil;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.util.Tool;
import util.JarUtil;
public class HBaseDriver extends Configured implements Tool{
public static String FROMTABLE=""; //导入表
public static String TOTABLE=""; //导出表
public static String SETVERSION=""; //是否设置版本
// args => {FromTable,ToTable,SetVersion,ColumnFromTable,ColumnToTable}
@Override
public int run(String[] args) throws Exception {
if(args.length!=5){
System.err.println("Usage:\n demo.job.HBaseDriver <input> <inputTable> "
+ "<output> <outputTable>"
+"< versions >"
+ " <set columns from inputTable> like <cf1:c1,cf1:c2,cf1:c10,cf1:c11,cf1:c14> or <-1> "
+ "<set columns from outputTable> like <cf1:c1,cf1:c10,cf1:c14> or <-1>");
return -1;
}
Configuration conf = getConf();
FROMTABLE = args[0];
TOTABLE = args[1];
SETVERSION = args[2];
conf.set("SETVERSION", SETVERSION);
if(!args[3].equals("-1")){
conf.set("COLUMNFROMTABLE", args[3]);
}
if(!args[4].equals("-1")){
conf.set("COLUMNTOTABLE", args[4]);
}
String jobName ="From table "+FROMTABLE+ " ,Import to "+ TOTABLE;
Job job = Job.getInstance(conf, jobName);
job.setJarByClass(HBaseDriver.class);
Scan scan = new Scan();
// 判断是否需要设置版本
if(SETVERSION != "0" || SETVERSION != "1"){
scan.setMaxVersions(Integer.parseInt(SETVERSION));
}
// 设置HBase表输入:表名、scan、Mapper类、mapper输出键类型、mapper输出值类型
TableMapReduceUtil.initTableMapperJob(
FROMTABLE,
scan,
HBaseToHBaseMapper.class,
ImmutableBytesWritable.class,
Put.class,
job);
// 设置HBase表输出:表名,reducer类
TableMapReduceUtil.initTableReducerJob(TOTABLE, null, job);
// 没有 reducers, 直接写入到 输出文件
job.setNumReduceTasks(0);
return job.waitForCompletion(true) ? 0 : 1;
}
private static Configuration configuration;
public static Configuration getConfiguration(){
if(configuration==null){
/**
* TODO 了解如何直接从Windows提交代码到Hadoop集群
* 并修改其中的配置为实际配置
*/
configuration = new Configuration();
configuration.setBoolean("mapreduce.app-submission.cross-platform", true);// 配置使用跨平台提交任务
configuration.set("fs.defaultFS", "hdfs://master:8020");// 指定namenode
configuration.set("mapreduce.framework.name", "yarn"); // 指定使用yarn框架
configuration.set("yarn.resourcemanager.address", "master:8032"); // 指定resourcemanager
configuration.set("yarn.resourcemanager.scheduler.address", "master:8030");// 指定资源分配器
configuration.set("mapreduce.jobhistory.address", "master:10020");// 指定historyserver
configuration.set("hbase.master", "master:16000");
configuration.set("hbase.rootdir", "hdfs://master:8020/hbase");
configuration.set("hbase.zookeeper.quorum", "slave1,slave2,slave3");
configuration.set("hbase.zookeeper.property.clientPort", "2181");
//TODO 需export->jar file ; 设置正确的jar包所在位置
configuration.set("mapreduce.job.jar",JarUtil.jar(HBaseDriver.class));// 设置jar包路径
}
return configuration;
}
}
package GeneralHBaseToHBase;
import java.io.IOException;
import java.util.ArrayList;
import java.util.HashMap;
import java.util.HashSet;
import java.util.Map.Entry;
import java.util.NavigableMap;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.Cell;
import org.apache.hadoop.hbase.KeyValue;
import org.apache.hadoop.hbase.client.Put;
import org.apache.hadoop.hbase.client.Result;
import org.apache.hadoop.hbase.io.ImmutableBytesWritable;
import org.apache.hadoop.hbase.mapreduce.TableMapper;
import org.apache.hadoop.hbase.util.Bytes;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
public class HBaseToHBaseMapper extends TableMapper<ImmutableBytesWritable, Put> {
Logger log = LoggerFactory.getLogger(HBaseToHBaseMapper.class);
private static int versionNum = 0;
private static String[] columnFromTable = null;
private static String[] columnToTable = null;
private static String column1 = null;
private static String column2 = null;
@Override
protected void setup(Context context)
throws IOException, InterruptedException {
Configuration conf = context.getConfiguration();
versionNum = Integer.parseInt(conf.get("SETVERSION", "0"));
column1 = conf.get("COLUMNFROMTABLE",null);
if(!(column1 == null)){
columnFromTable = column1.split(",");
}
column2 = conf.get("COLUMNTOTABLE",null);
if(!(column2 == null)){
columnToTable = column2.split(",");
}
}
@Override
protected void map(ImmutableBytesWritable key, Result value,
Context context)
throws IOException, InterruptedException {
context.write(key, resultToPut(key,value));
}
/***
* 把key,value转换为Put
* @param key
* @param value
* @return
* @throws IOException
*/
private Put resultToPut(ImmutableBytesWritable key, Result value) throws IOException {
HashMap<String, String> fTableMap = new HashMap<>();
HashMap<String, String> tTableMap = new HashMap<>();
Put put = new Put(key.get());
if(! (columnFromTable == null || columnFromTable.length == 0)){
fTableMap = getFamilyAndColumn(columnFromTable);
}
if(! (columnToTable == null || columnToTable.length == 0)){
tTableMap = getFamilyAndColumn(columnToTable);
}
if(versionNum==0){
if(fTableMap.size() == 0){
if(tTableMap.size() == 0){
for (Cell kv : value.rawCells()) {
put.add(kv); // 没有设置版本,没有设置列导入,没有设置列导出
}
return put;
} else{
return getPut(put, value, tTableMap); // 无版本、无列导入、有列导出
}
} else {
if(tTableMap.size() == 0){
return getPut(put, value, fTableMap);// 无版本、有列导入、无列导出
} else {
return getPut(put, value, tTableMap);// 无版本、有列导入、有列导出
}
}
} else{
if(fTableMap.size() == 0){
if(tTableMap.size() == 0){
return getPut1(put, value); // 有版本,无列导入,无列导出
}else{
return getPut2(put, value, tTableMap); //有版本,无列导入,有列导出
}
}else{
if(tTableMap.size() == 0){
return getPut2(put,value,fTableMap);// 有版本,有列导入,无列导出
}else{
return getPut2(put,value,tTableMap); // 有版本,有列导入,有列导出
}
}
}
}
/***
* 无版本设置的情况下,对于有列导入或者列导出
* @param put
* @param value
* @param tableMap
* @return
* @throws IOException
*/
private Put getPut(Put put,Result value,HashMap<String, String> tableMap) throws IOException{
for(Cell kv : value.rawCells()){
byte[] family = kv.getFamily();
if(tableMap.containsKey(new String(family))){
String columnStr = tableMap.get(new String(family));
ArrayList<String> columnBy = toByte(columnStr);
if(columnBy.contains(new String(kv.getQualifier()))){
put.add(kv); //没有设置版本,没有设置列导入,有设置列导出
}
}
}
return put;
}
/***
* (有版本,无列导入,有列导出)或者(有版本,有列导入,无列导出)
* @param put
* @param value
* @param tTableMap
* @return
*/
private Put getPut2(Put put,Result value,HashMap<String, String> tableMap){
NavigableMap<byte[], NavigableMap<byte[], NavigableMap<Long, byte[]>>> map=value.getMap();
for(byte[] family:map.keySet()){
if(tableMap.containsKey(new String(family))){
String columnStr = tableMap.get(new String(family));
log.info("@@@@@@@@@@@"+new String(family)+" "+columnStr);
ArrayList<String> columnBy = toByte(columnStr);
NavigableMap<byte[], NavigableMap<Long, byte[]>> familyMap = map.get(family);//列簇作为key获取其中的列相关数据
for(byte[] column:familyMap.keySet()){ //根据列名循坏
log.info("!!!!!!!!!!!"+new String(column));
if(columnBy.contains(new String(column))){
NavigableMap<Long, byte[]> valuesMap = familyMap.get(column);
for(Entry<Long, byte[]> s:valuesMap.entrySet()){//获取列对应的不同版本数据,默认最新的一个
System.out.println("***:"+new String(family)+" "+new String(column)+" "+s.getKey()+" "+new String(s.getValue()));
put.addColumn(family, column, s.getKey(),s.getValue());
}
}
}
}
}
return put;
}
/***
* 有版本、无列导入、无列导出
* @param put
* @param value
* @return
*/
private Put getPut1(Put put,Result value){
NavigableMap<byte[], NavigableMap<byte[], NavigableMap<Long, byte[]>>> map=value.getMap();
for(byte[] family:map.keySet()){
NavigableMap<byte[], NavigableMap<Long, byte[]>> familyMap = map.get(family);//列簇作为key获取其中的列相关数据
for(byte[] column:familyMap.keySet()){ //根据列名循坏
NavigableMap<Long, byte[]> valuesMap = familyMap.get(column);
for(Entry<Long, byte[]> s:valuesMap.entrySet()){ //获取列对应的不同版本数据,默认最新的一个
put.addColumn(family, column, s.getKey(),s.getValue());
}
}
}
return put;
}
// str => {"cf1:c1","cf1:c2","cf1:c10","cf1:c11","cf1:c14"}
/***
* 得到列簇名与列名的k,v形式的map
* @param str => {"cf1:c1","cf1:c2","cf1:c10","cf1:c11","cf1:c14"}
* @return map => {"cf1" => "c1,c2,c10,c11,c14"}
*/
private static HashMap<String, String> getFamilyAndColumn(String[] str){
HashMap<String, String> map = new HashMap<>();
HashSet<String> set = new HashSet<>();
for(String s : str){
set.add(s.split(":")[0]);
}
Object[] ob = set.toArray();
for(int i=0; i<ob.length;i++){
String family = String.valueOf(ob[i]);
String columns = "";
for(int j=0;j < str.length;j++){
if(family.equals(str[j].split(":")[0])){
columns += str[j].split(":")[1]+",";
}
}
map.put(family, columns.substring(0, columns.length()-1));
}
return map;
}
private static ArrayList<String> toByte(String s){
ArrayList<String> b = new ArrayList<>();
String[] sarr = s.split(",");
for(int i=0;i<sarr.length;i++){
b.add(sarr[i]);
}
return b;
}
}
程序运行完之后,在hbase shell中查看每个表,看是否数据导入正确:
test2:(无版本、无列导入设置、无列导出设置)
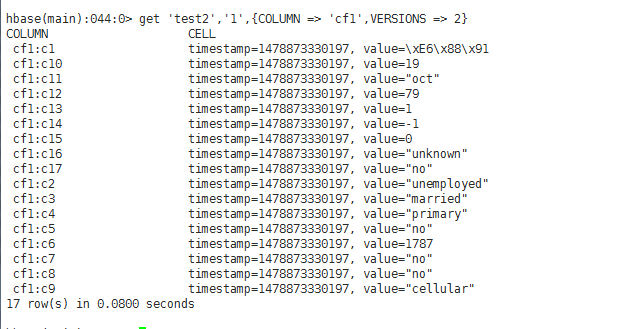
test3 (无版本、有列导入设置("cf1:c1,cf1:c2,cf1:c10,cf1:c11,cf1:c14")、无列导出设置)
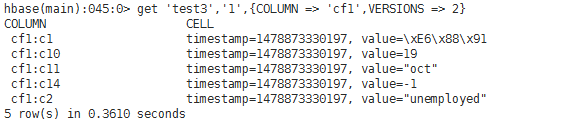
test4(无版本、无列导入设置、有列导出设置("cf1:c1,cf1:c10,cf1:c14"))
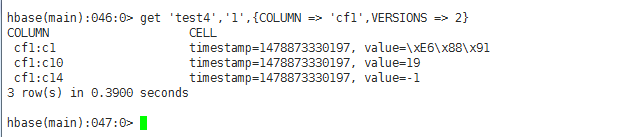
test5(有版本、无列导入设置、无列导出设置)
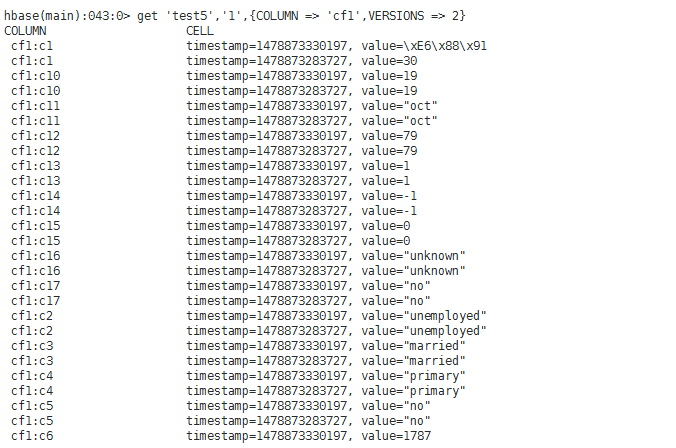
test6(有版本、有列导入设置("cf1:c1,cf1:c2,cf1:c10,cf1:c11,cf1:c14")、无列导出设置)
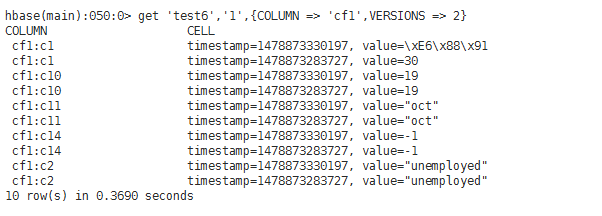
test7(有版本、无列导入设置、有列导出设置("cf1:c1,cf1:c10,cf1:c14"))
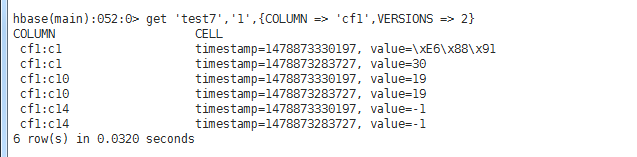
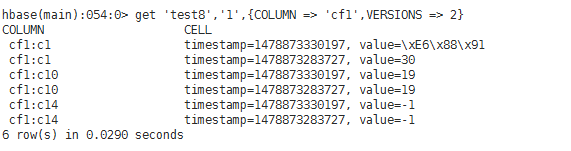
test8(有版本、有列导入设置("cf1:c1,cf1:c2,cf1:c10,cf1:c11,cf1:c14")、有列导出设置("cf1:c1,cf1:c10,cf1:c14"))















 199
199











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









