







hadoop分布式集群搭建1主1从(含虚拟机安装教程)
1.搭建虚拟机
下载VMware软件使用软件搭建 VMware官网(傻瓜式安装)
1. 新建虚拟机、并且配置虚拟机


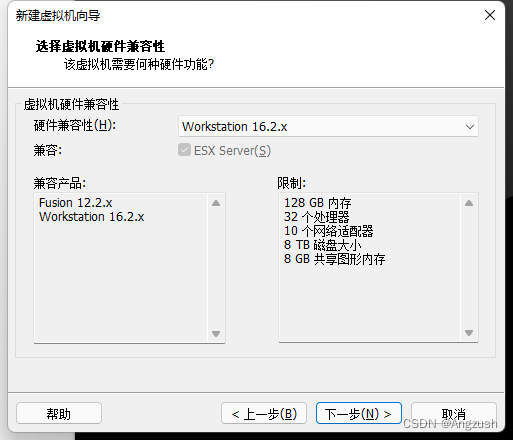

这里要选择你所下载的iso镜像 我的版本是center os 7 这是我的镜像地址在百度网盘()
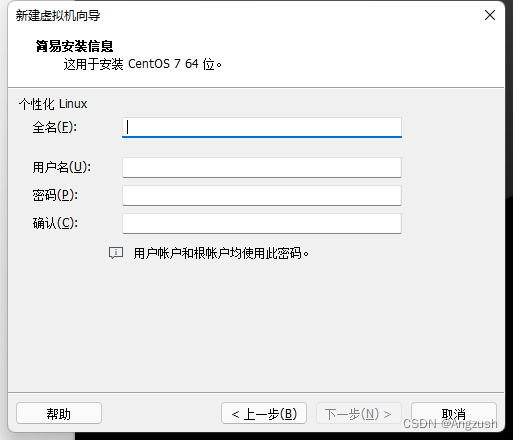
全名: 虚拟机登录界面显示的名称(随意)
用户名: 设置用户名(例:angzush_) 此用户名需跟后续进入linux设置的一致,不然无法切换root用户
密码: 设置用户密码(例:123456)此密码需跟后续进入linux设置的一致
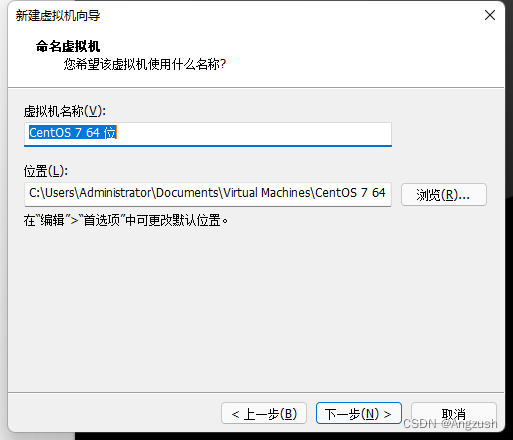
虚拟机名称:随意命名
位置:虚拟机搭建的位置建议别在c盘

处理器和处理器内核数、根据自己电脑配置来

给虚拟机分配内存根据自己电脑配置来(一般不要低于1g)
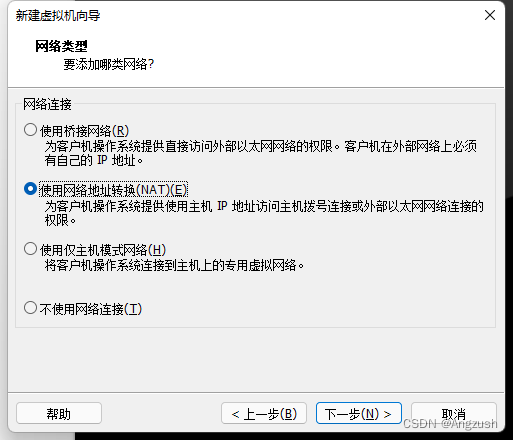
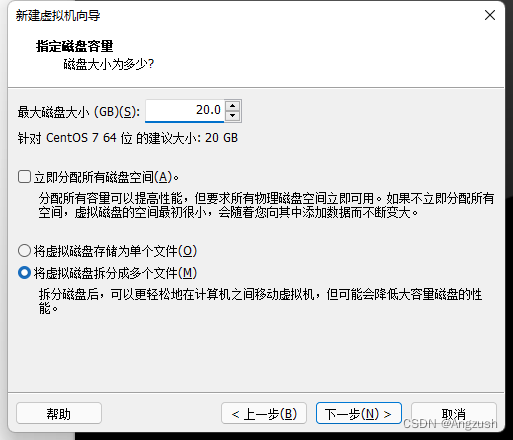
自己根据分配磁盘大小我的是100g
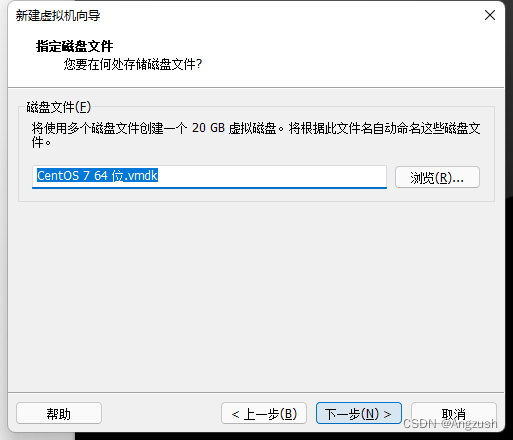
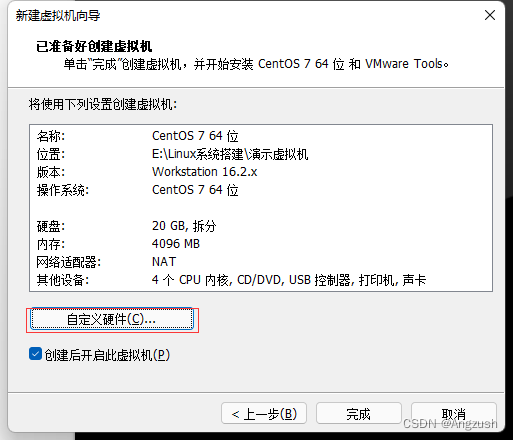
点击自定义硬件配置指向iso映像文件
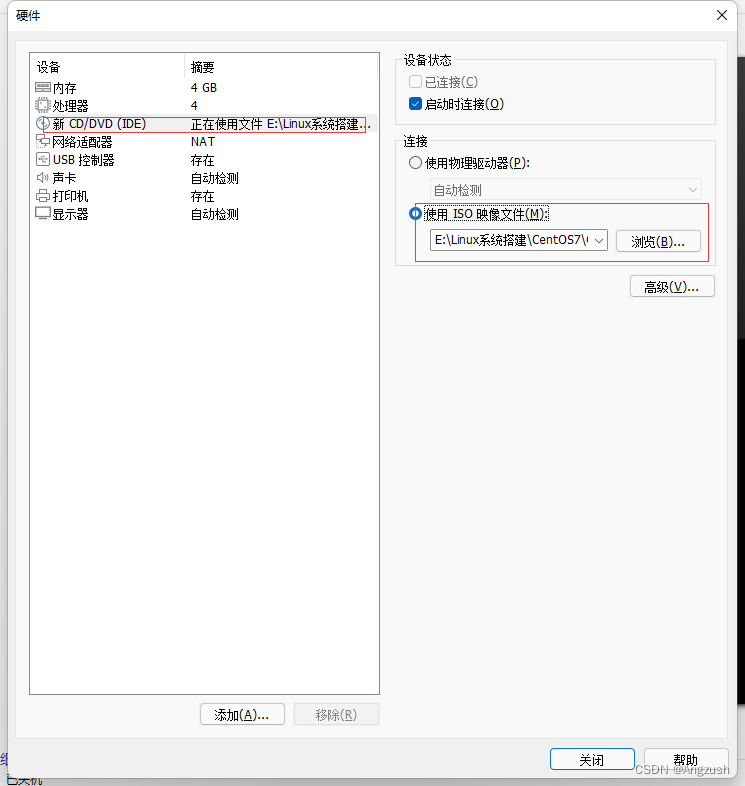
然后点击完成自启动(在这一步一些电脑会出现这个bug)

这个问题是因为本地电脑未支持虚拟机需要开启支持(重启电脑然后按F2进入BIOS界面一些电脑在Configuration选项里有 intel virtual technology 选项将Disabled 改为 Enabled)
例:
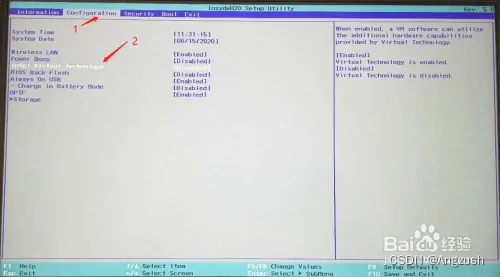
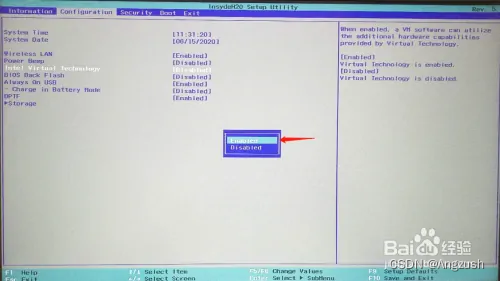
然后按F10保存启动就行了
重新打开VMware开启虚拟机
进入user 创建用户
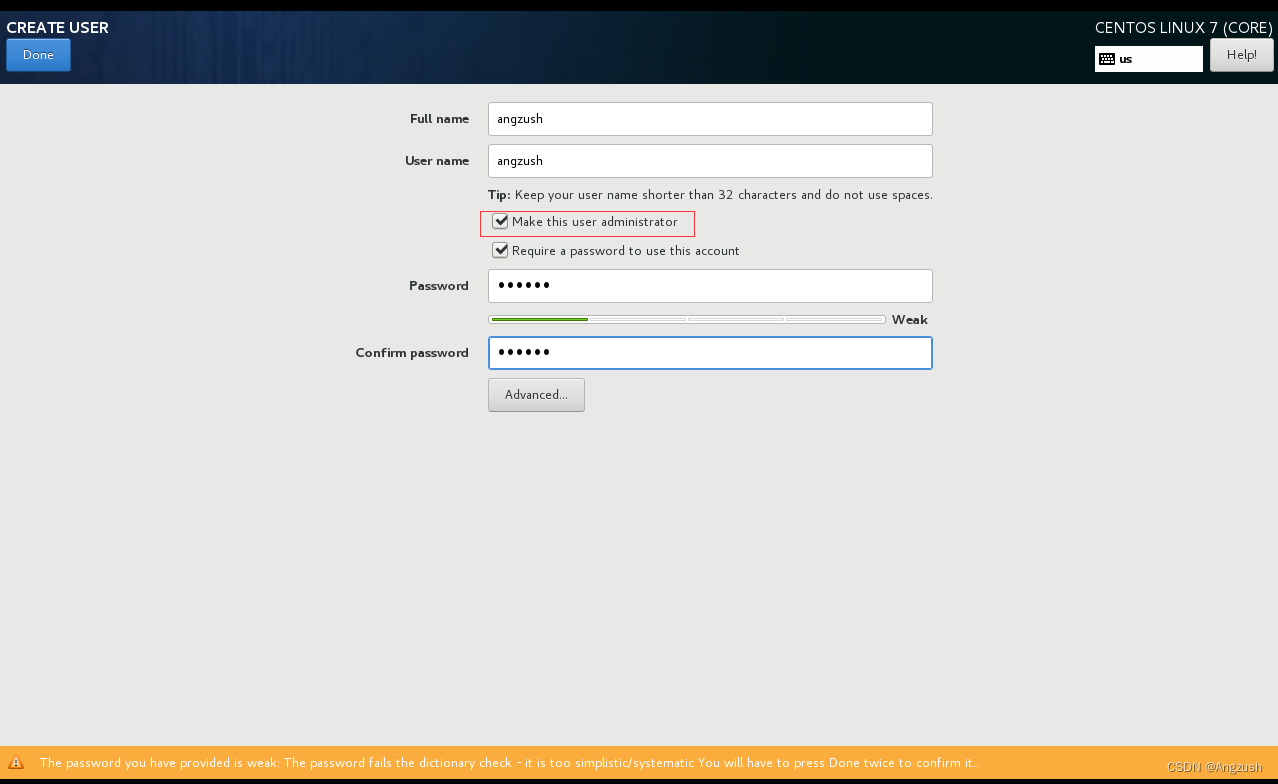
用户一定要和之前在虚拟机创建的一致、我这勾选了Make this user administrator 意思是让该用户拥有admin的权限、然后双击DONE


这就算安装完成了、输入密码直接进入(例:123456)

然后右键 openTerminal 打开控制台、输入ifconfig查看IP地址
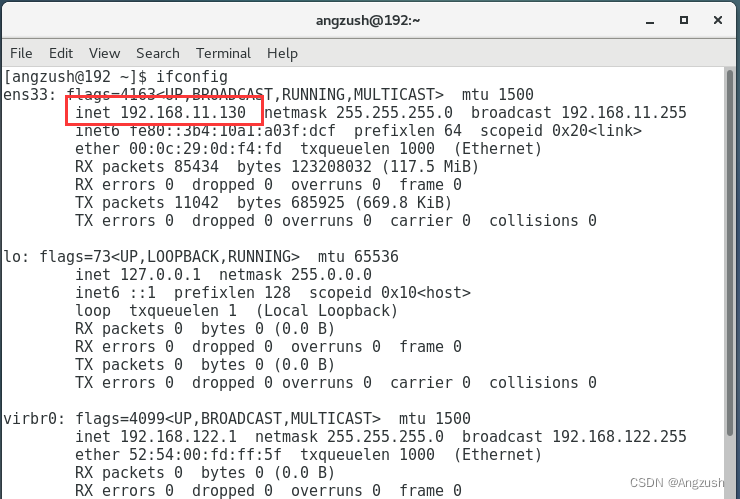
我的ip地址是192.168.11.130、然后用本地电脑ping 这个ip看是否能ping通、接着用虚拟机控制台ping 百度看是否有网
// 在本地电脑DOS命令行ping虚拟机ip
ping 192.168.11.130
// 在虚拟机控制台ping 百度
ping www.baidu.com
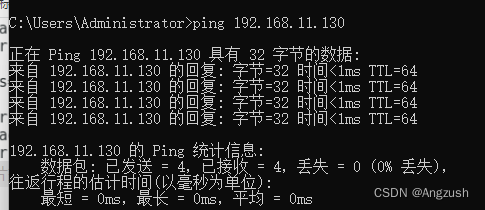
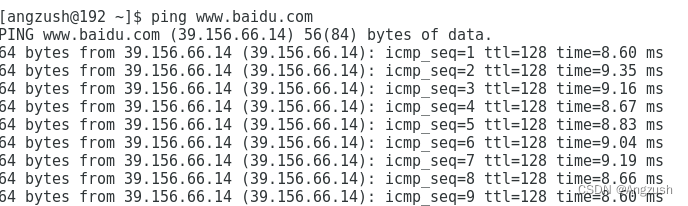
出现以上两种代表成功、接下来需要给虚拟机快照
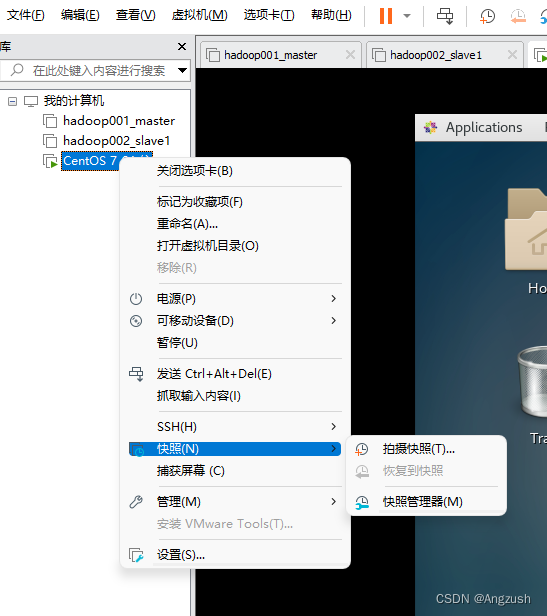
使用拍摄快照将虚拟机环境保存下来
2. Hadoop搭建
1. 安装java
在java官网下载 Java官网
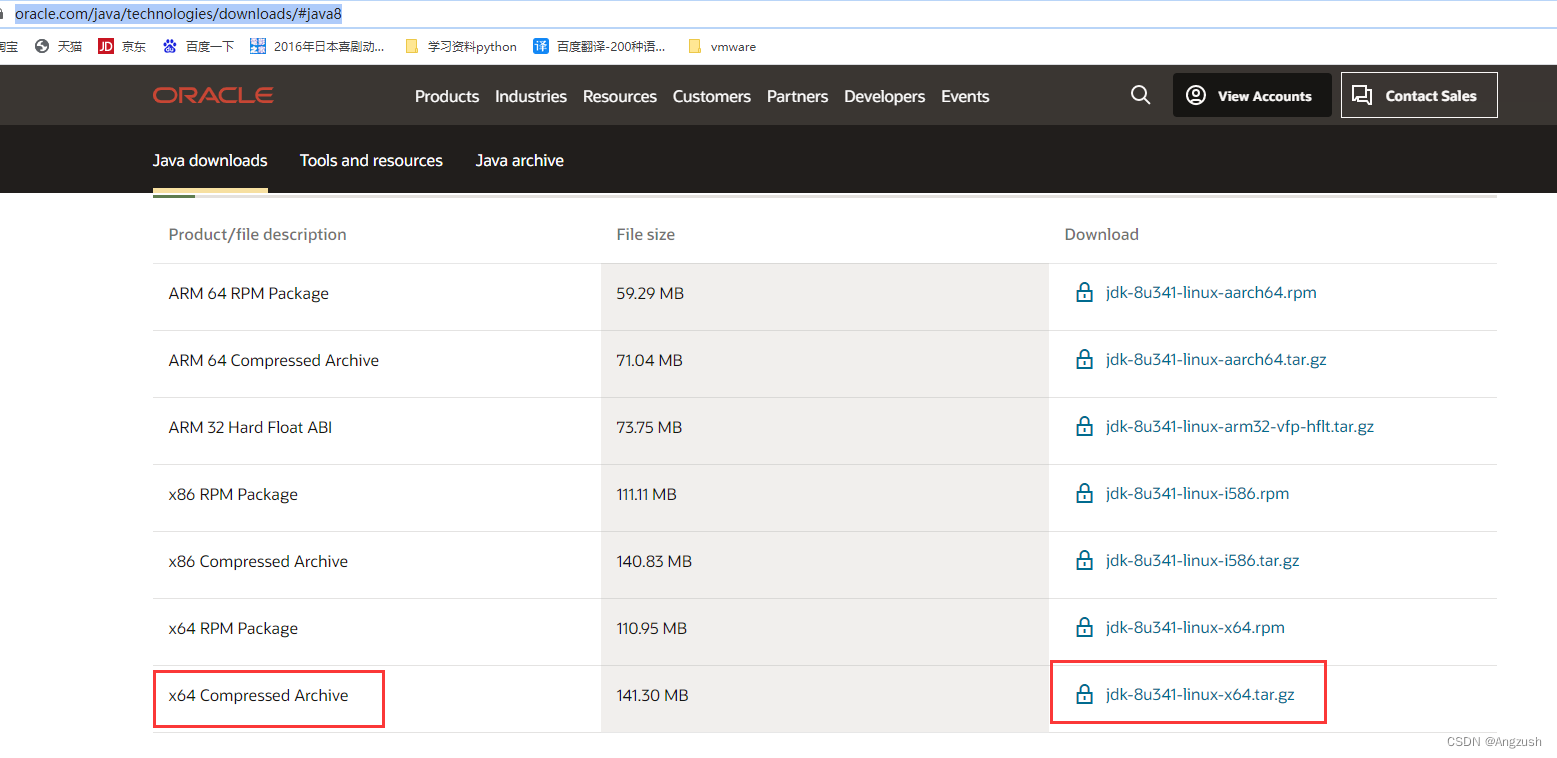
然后用xshell 拉入到Linux root目录下
(xshell、xftp下载地址)链接:https://pan.baidu.com/s/1WSun7g70e9LCdpsUkaTJuA 提取码:0326
然后在xshell中解压jdk安装包、tar -zxvf 安装包名称 ,接着使用 mv命令将jdk文件夹移动到 /usr/local 下、并将文件夹名称改为java、所以java的路径为 /usr/local/java
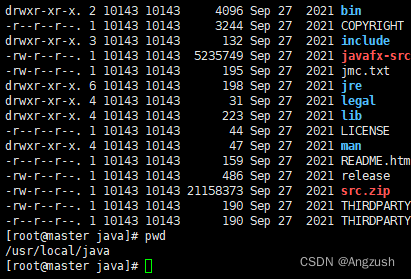
然后修改全局环境 vim/etc/profile 在最下面添加export
#this is for java environment
export JAVA_HOME=/usr/local/java
export PATH=$PATH:$JAVA_HOME/bin
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
export JRE_HOME=$JAVA_HOME/jre

#重新加载文件
source /etc/profile
使用 java、javac、java -version 查看环境搭建是否正确
2. 搭建hadoop运行环境
-
使用 hostname 查看主机名称

如果不是master建议将主服务器名修改为master
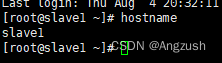
从服务器改为slave1
#使用该命令 sudo hostnamectl set-hostname master sudo hostnamectl set-hostname slave1 -
修改host文件
vim /etc/hosts
添加主服务器IP、和从服务器IP及名称
例:192.168.11.128 master
192.168.11.129 slave1 -
ssh免密登录配置
首先在master上运行、接着一直回车生成密钥ssh-keygen -t rsa然后将密钥加入到 authorized_keys 文件中
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys然后将authorized_keys文件发送到slave1机器上
scp authorized_keys root@192.168.11.129:/root/.ssh/接着在slave1服务器中重复上面的命令、要将生成的authorized_keys文件发送到master服务器/root/.ssh里
然后使用 ssh主机名来切换(第一次是需要输入yes但不需要输入密码)#切换到slave1 ssh slave1 #切换到master ssh master
-
下载Hadoop版本(我下载的是3.3.2版本) Hadoop下载地址
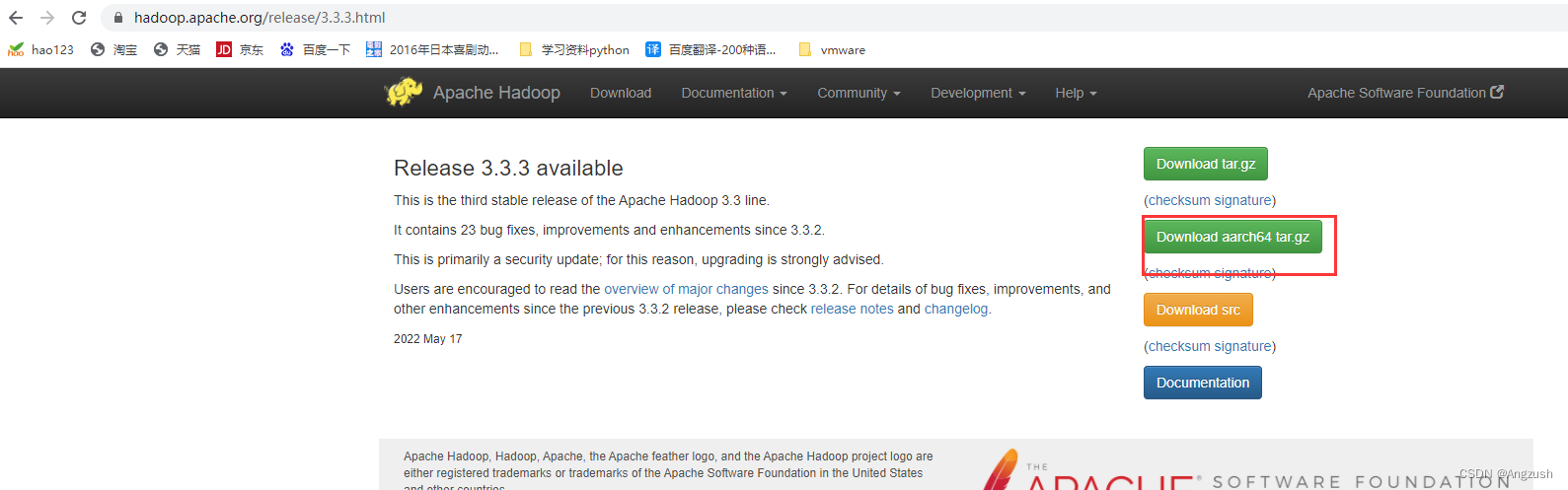
-
配置Hadoop环境变量
解压文件、放到/usr/local/改名为hadoop(不一定要是这个位置、最好放在已挂载的data数据文件夹下,这里只是演示用)然后配置环境变量
#我的目录是 /usr/local/hadoop 不一定要是这个位置、最好放在已挂载的data数据文件夹下,这里只是演示用 export HADOOP_HOME=/usr/local/hadoop export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin export HADOOP_CONF_DIR=${HADOOP_HOME}/etc/hadoop -
配置Hadoop文件:
文件 作用 workers 记录所有的数据节点的主机名或 IP 地址 core-site.xml Hadoop 核心配置 hdfs-site.xml HDFS 配置项 mapred-site.xml MapReduce 配置项 yarn-site.xml YRAN 配置项 -
修改core-site.xml
vim ${HADOOP_HOME}/etc/hadoop/core-site.xml<configuration> <property> <name>hadoop.tmp.dir</name> <value>file:/data/hadoop/hdfs/tmp</value> <description>临时存储目录,修改为自己想放的地方、前提是文件夹已被创建</description> </property> <property> <name>fs.defaultFS</name> <value>hdfs://master:9000</value> <description>hdfs默认地址与端口</description> </property> <property> <name>io.file.buffer.size</name> <value>131702</value> </property> </configuration> -
修改hdfs-site.xml
vim ${HADOOP_HOME}/etc/hadoop/hdfs-site.xml<configuration> <property> <name>dfs.namenode.name.dir</name> <value>file:/data/hadoop/hdfs/name</value> <description>namenode上存储hdfs名字空间元数据 </description> </property> <property><!--DataNode存放块数据的本地文件系统路径--> <name>dfs.datanode.data.dir</name> <value>file:/data/hadoop/hdfs/data</value> <description>datanode上数据块的物理存储位置</description> </property> <property><!--数据需要备份的数量,不能大于集群的机器数量,默认为3--> <name>dfs.replication</name> <value>2</value> </property> <property> <name>dfs.namenode.secondary.http-address</name> <value>slave1:50090</value> <description>这个主机名设置哪个节点,SecondaryNameNode就启动在哪个服务器上</description> </property> <property> <name>dfs.webhdfs.enabled</name> <value>true</value> </property> <property> <name>dfs.client.use.datanode.hostname</name> <value>true</value> <description>only cofig in clients</description> </property> </configuration> -
修改Mapred-site.xml
vim ${HADOOP_HOME}/etc/hadoop/mapred-site.xml<configuration> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> <property> <name>yarn.app.mapreduce.am.env</name> <value>HADOOP_MAPRED_HOME=/data/hadoop/mapreduce</value> </property> <property> <name>mapreduce.map.env</name> <value>HADOOP_MAPRED_HOME=/data/hadoop/mapreduce/map</value> </property> <property> <name>mapreduce.reduce.env</name> <value>HADOOP_MAPRED_HOME=/data/hadoop/mapreduce/reduce</value> </property> </configuration> -
修改Yarn-site.xml
vim ${HADOOP_HOME}/etc/hadoop/yarn-site.xml<configuration> <!-- Site specific YARN configuration properties --> <property> <name>yarn.resourcemanager.hostname</name> <value>master</value> <description>The hostname of the RM.修改为主节点主机名</description> </property> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> <!-- 因为我是虚拟机可能内存会不够 --> <property> <name>yarn.nodemanager.vmem-check-enabled</name> <value>false</value> </property> </configuration> -
然后在 hadoop-env.sh、mapred-env.sh、yarn-env.sh文件中各添加javahome
export JAVA_HOME=/usr/local/java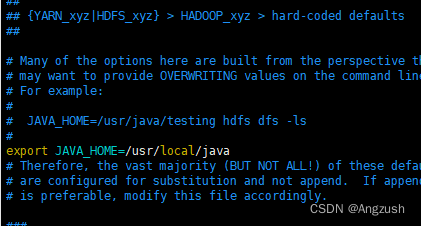
-
在workers文件中填写主机名,主从都写
vim ${HADOOP_HOME}/etc/hadoop/workers
-
进入Hadoop sbin目录下 cd ${HADOOP_HOME}/sbin 添加start-dfs.sh、stop-dfs.sh头部配置
HDFS_DATANODE_USER=root HDFS_DATANODE_SECURE_USER=hdfs HDFS_NAMENODE_USER=root HDFS_SECONDARYNAMENODE_USER=root -
给start-yarn.sh、stop-yarn.sh添加头部配置
YARN_RESOURCEMANAGER_USER=root HADOOP_SECURE_DN_USER=yarn YARN_NODEMANAGER_USER=root
然后执行 hadoop version 查看版本信息

-
这是给master配置好了 然后咱们再配置slave1
-
将Hadoop整体文件夹拷贝到slave1
scp /usr/local/hadoop root@192.168.11.129:/usr/local/ -
修改 /etc/profile 环境变量、添加之前再master配置的内容、或者可以直接将master 的 proflie文件放到slave1虚拟机上然后重新加载环境
slave1配置完成后切换到master格式化hdfs
hdfs namenode -format
启动hdfs和yarn
#启动hdfs
start-dfs.sh
#关闭hdfs
stop-dfs.sh

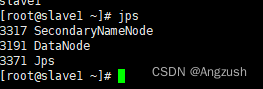
#启动yarn
start-yarn.sh
#关闭yarn
stop-yarn.sh
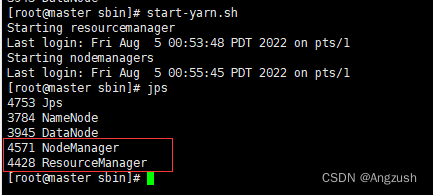
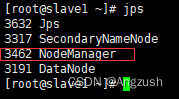
此刻代表Hadoop 启动成功、接下来咱们访问Hadoop的webUi界面
hdfsWebUi:http://ip:9870
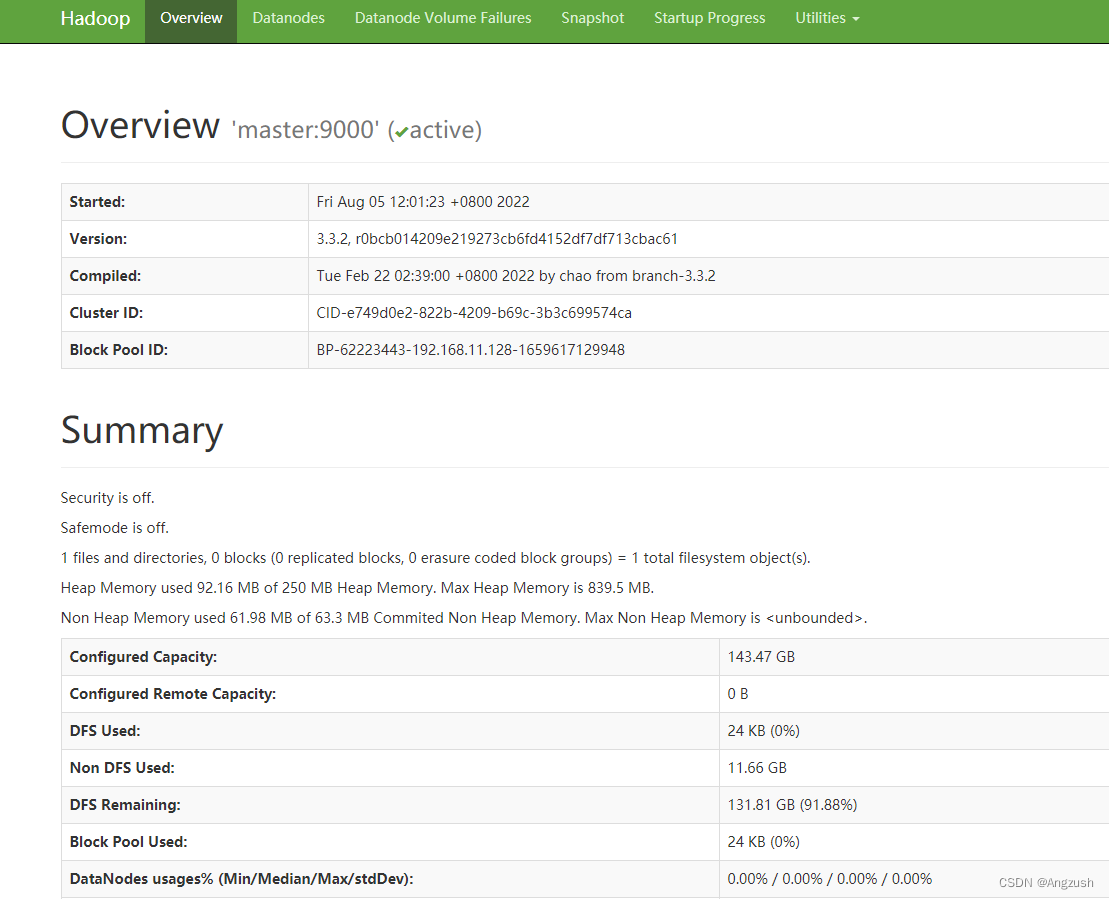
yarnWebUi:http://ip:8088
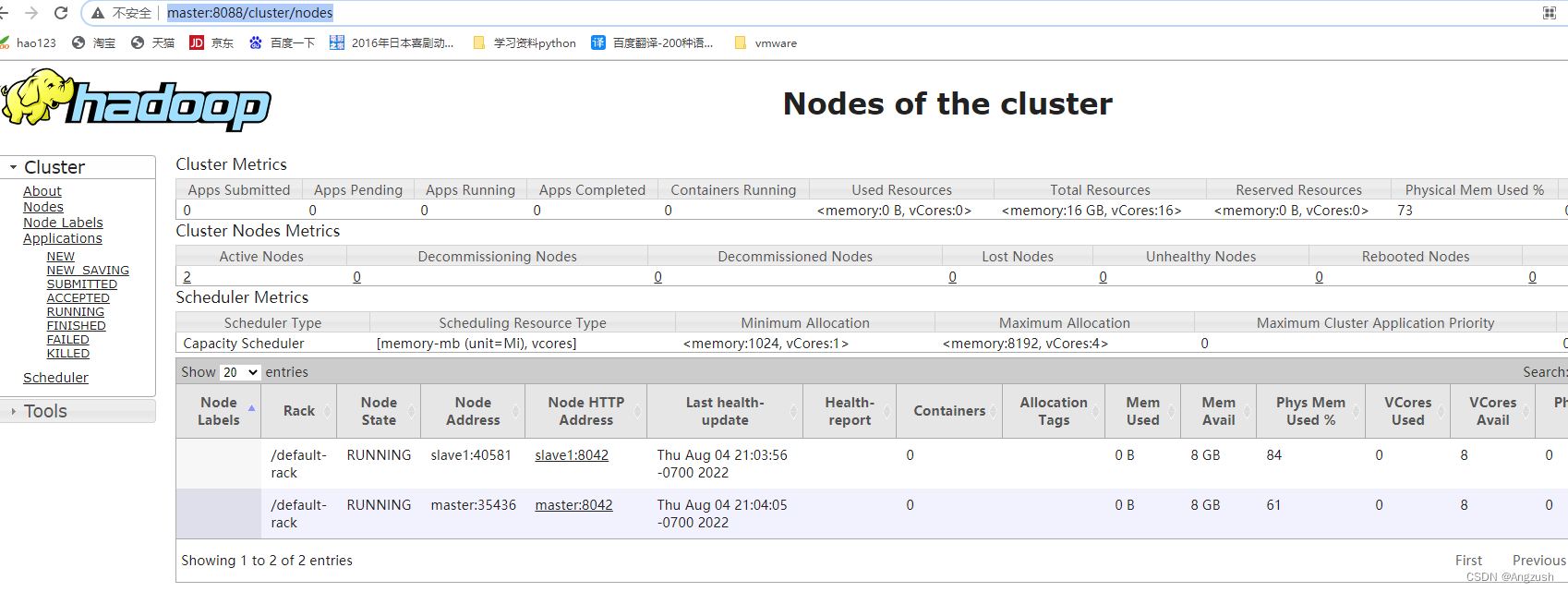
3. BUG集
1. 在hdfsWebUI查看数据目录会报这个错
Failed to retrieve data from /webhdfs/v1/?op=LISTSTATUS: Server Error
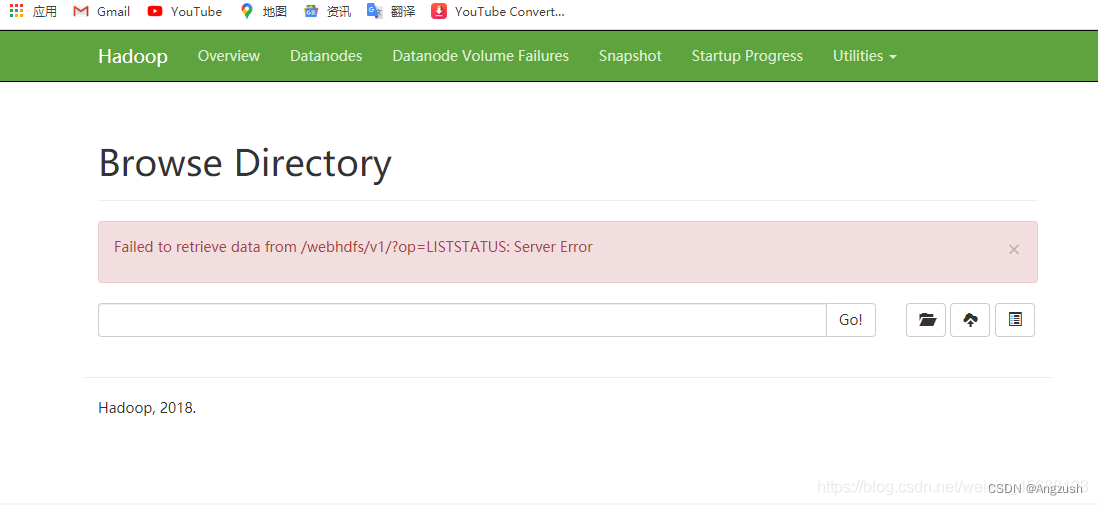
这是因为java 11以后 移除了javax.activation**、咱们需要将jar包放入Hadoop/share/hadoop/common 下
jar包位置:https://jar-download.com/?search_box=javax.activation
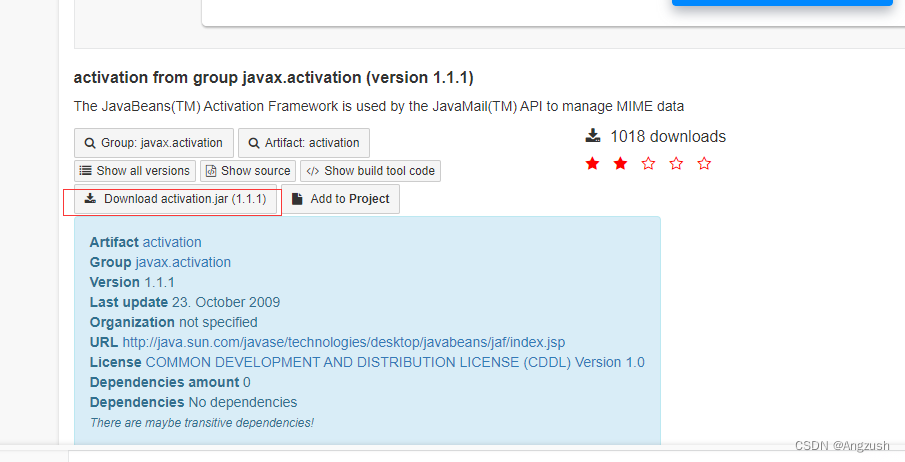
下载解压后放到 cd ${HADOOP_HOME}/share/hadoop/common/ master和slave1 都要、然后重启虚拟机就行
2.可能在启动虚拟机时启动不成功出现错误Failed to load SELinux policy freezing
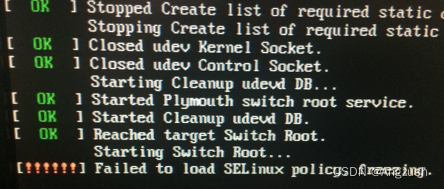
解决方案:在启动时按e grub编辑页面
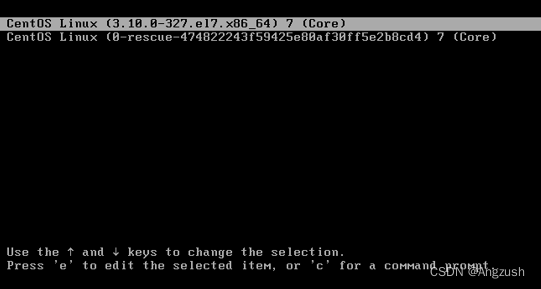
通过键盘的向上或向下箭头,找到linux16那行 在LANG=zh_CN.UTF-8 空格 加上 selinux=0或者 enforcing=0(我是第一个就解决问题了)
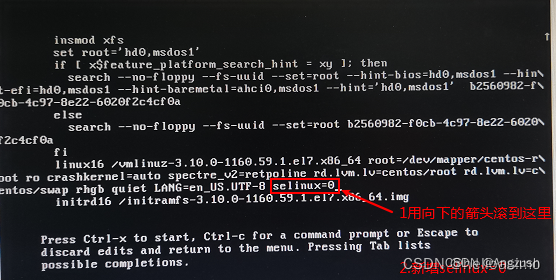
不要退出页面,在此处使用Ctrl+x启动,之后等会就会看到熟悉的页面了。要说一点的是,可能会在下图所示页面卡顿一会,等会就行了
进入系统之后记得把配置修改正确。
Step1: 使用su命令进入管理员权限;
Step2: 修改配置文件/etc/selinux/config/中的“SELINUX”参数

SELINUX=disable
SELINUXTYPE=targeted
















 1351
1351











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











