






1. 问题&背景
测试环境测试时,已经正常运行了一段时间的接口突然报错了,根据RequestId很快定位到是因为调用ElasticSearch时出现了超时。
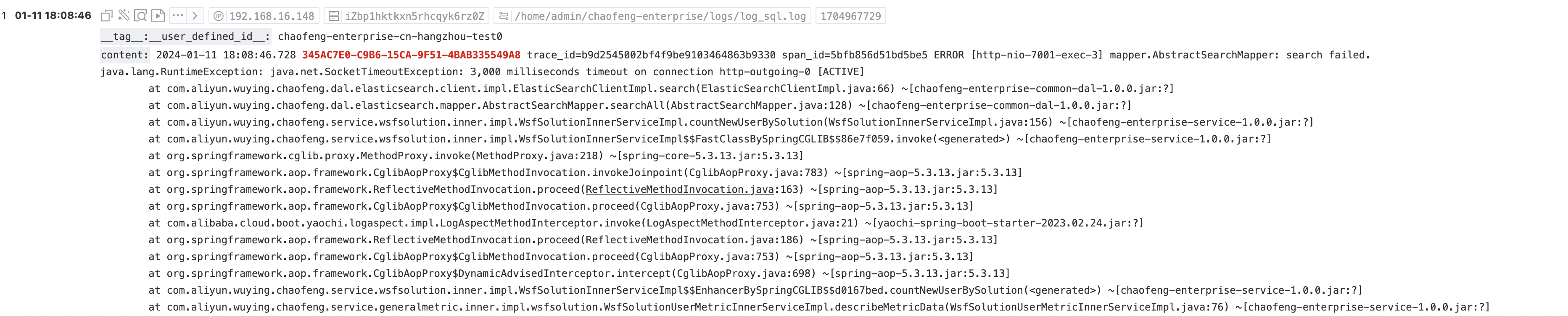
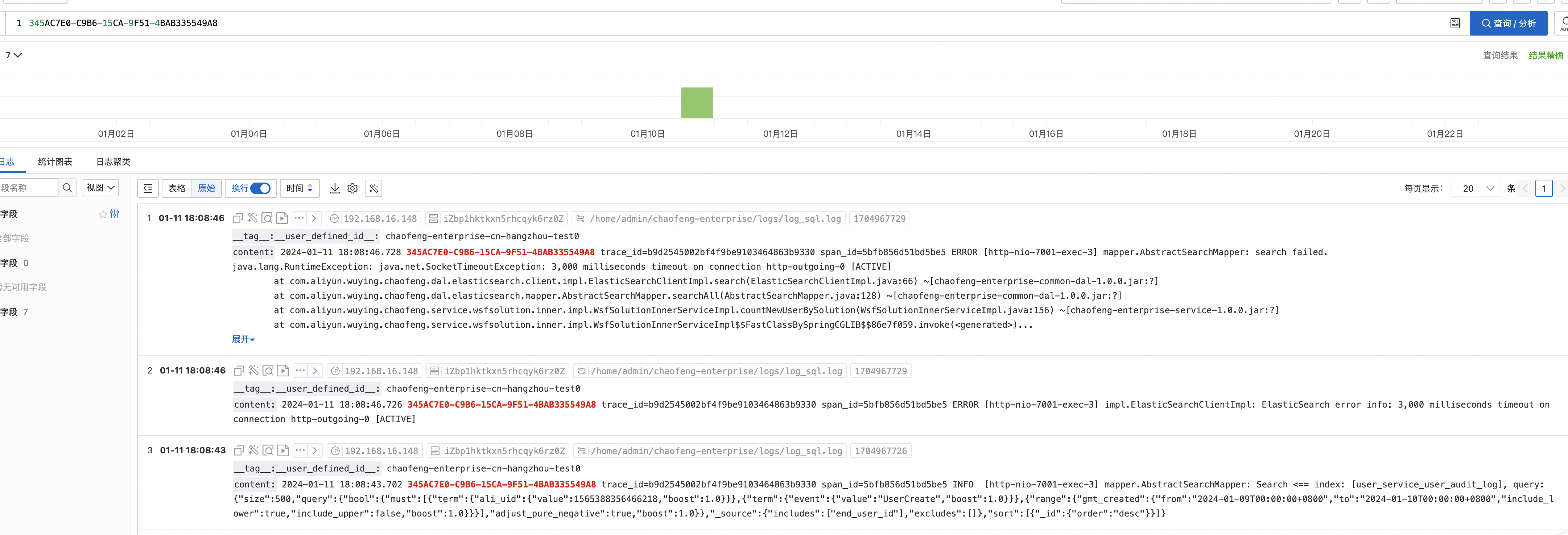
- 相关代码
底层封装了一个通用搜索方法,功能是根据查询条件查找出所有符合条件的文档。
为了避免单次查询返回的结果集过大,使用了ES的search_after参数,将结果集分批次返回。使用search_after参数需要一个排序字段,由于不同文档的mapping不一样,所以无法再mapping的字段中找到一个统一字段,而_id字段是每个文档都有的唯一标识,为了底层方法的通用性,使用了_id字段。
public <T extends BaseSearchDO> List<T> searchAll(DefaultSearchParam param, Class<T> resultClazz) {
...
param.closePagination()
.maxResults(BATCH_SIZE)
.clearOrder()
.appendOrder(DefaultSearchParam.SORT_FIELD_ID); // _id
for (; ; ) {
SimpleSearchRequest simpleSearchRequest = param.getSimpleSearchRequest();
SearchRequest searchRequest = buildRequest(simpleSearchRequest);
log.info("Search <== index: {}, query: {}", Arrays.toString(simpleSearchRequest.getIndices()), searchRequest.source().toString());
SearchResponse searchResponse = getElasticSearchClient().search(searchRequest);
if (log.isDebugEnabled()) {
log.debug("Search ==> response: {}", searchResponse.toString());
}
List<T> hits = toGenericResult(searchResponse, resultClazz).getHits();
result.addAll(hits);
if (CollectionUtils.isEmpty(hits) || hits.size() < BATCH_SIZE) {
break;
}
Object[] lastSortValue = hits.get(hits.size() - 1).get_sortValue();
param.maxResults(BATCH_SIZE)
.clearOrder()
.appendOrder(DefaultSearchParam.SORT_FIELD_ID, lastSortValue[0]);
}
...
}2. 定位
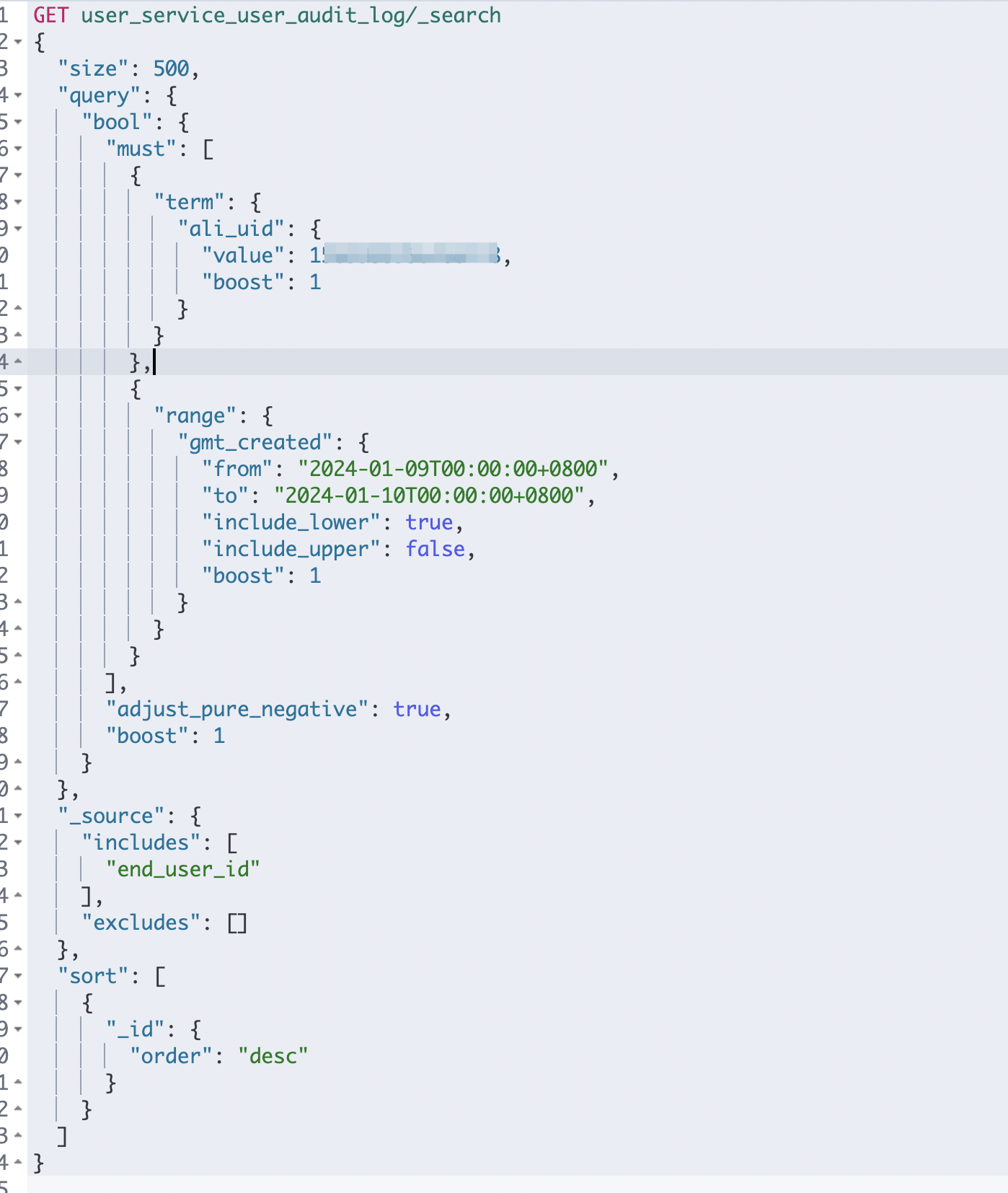
- 复制query语句至kibana中进行查询,ES查询直接出现了异常:
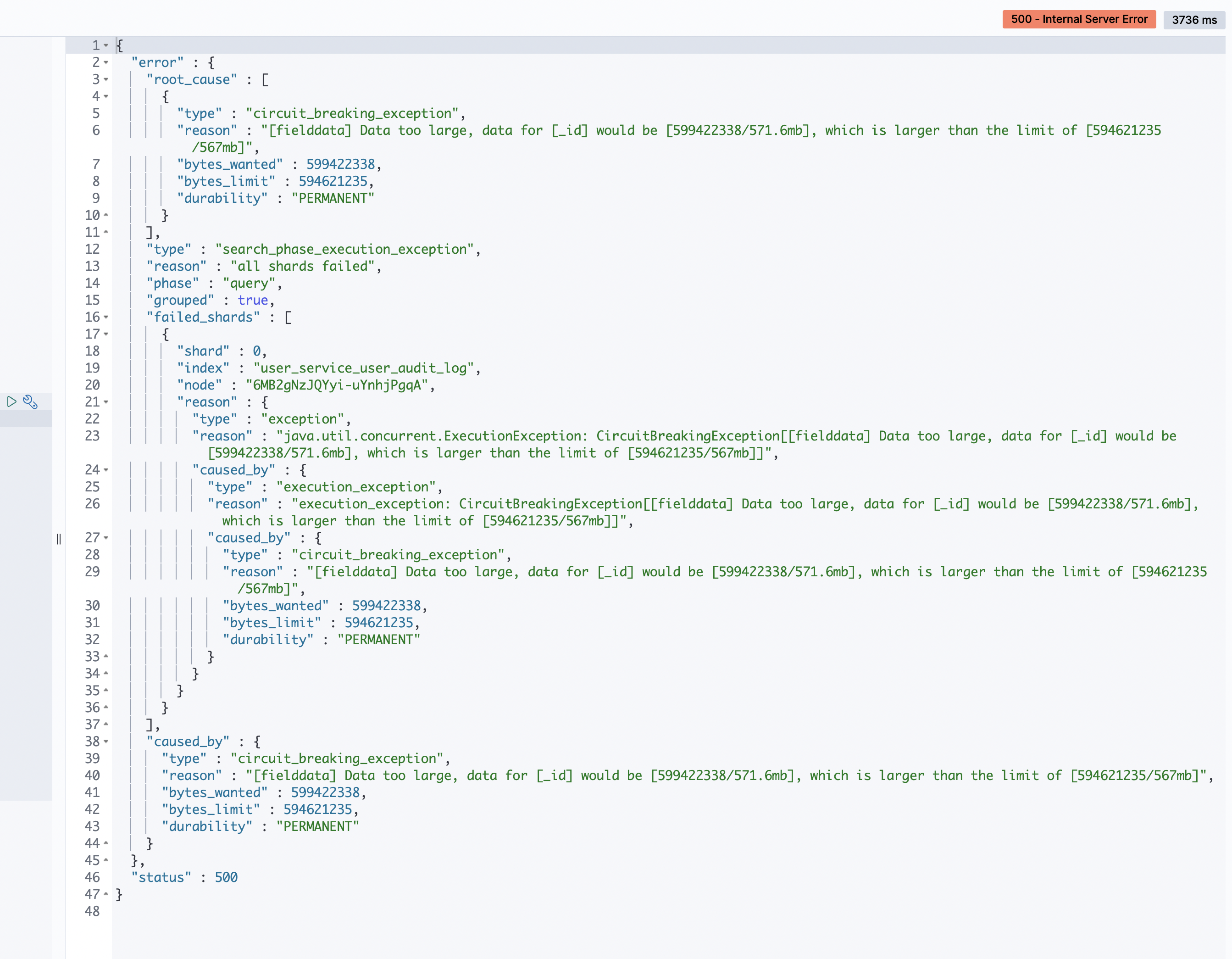
- ES官网对于解释Field data circuit breaker的解释:

可以得出结论:出现异常是由于在查询时由于 _id 字段太多超出了FieldData 缓存限制。
- 此时首先想到的就是去掉和_id有关的条件再查询试试,查询语句中和_id相关的字段只有排序,去掉后再次查询,果然正常了,而且查询速度很快。

此时就有了两个问题:
- 为什么去掉_id 相关的排序后就正常了?
- 满足查询条件的文档数为0,为什么会超出FieldData缓存限制?
- 再次查看ES文档对于_id 字段的的解释和排序相关文档,找到了第一个问题的答案。
The _id field is restricted from use in aggregations, sorting, and scripting. In case sorting or aggregating on the _id field is required, it is advised to duplicate the content of the _id field into another field that has doc_values enabled.
文档中赫然的写着 ‘不能用_id 字段排序’。
果然看文档要仔细...
3. 修复
找到问题原因后,修复还是比较简单的,根据ES文档中的建议,将代码中排序字段修改为 _doc。
_doc has no real use-case besides being the most efficient sort order. So if you don’t care about the order in which documents are returned, then you should sort by _doc. This especially helps when scrolling.
4. 深入了解
代码问题虽然解决了,但是疑问还是没有得到答案,经过查文档、资料之后找到了答案。
- 为什么不能用_id 排序?
_id字段是唯一标识文档的元数据字段,对应Lucene中的_uid,_uid只存储在倒排索引和文档原文中,并不存储在DocVlues中。这意味着它不会像其他字段那样预先排序,因此在_id字段上执行排序操作会比在预先排序和索引化的字段上效率低得多。
- 满足查询条件的文档数为0,为什么会超出FieldData缓存限制?
由于_id并不在DocValues中,排序时就需要使用大量的计算资源,因此ES会将所有文档中的_id字段加载到FieldData缓存中构建类似DocValues的结构,下次使用_id字段排序时可以直接使用缓存中的结果。并不是先根据查询条件找到符合条件的文档,然后再加载符合条件的文档中的排序字段。
使用_id查询后,可以在FieldData缓存中看到已经有了对应缓存。如:
GET /_cat/fielddata?v&h=id,field,size

5. 总结
- _id 是文档的唯一索引,可以直接在查询中使用ids/term/terms/match进行匹配,但是不能直接用于排序、聚合。
- 如果查询结果返回的顺序不影响业务,建议使用_doc 字段进行排序,效率最高。
6. 拓展
6.1.1. 存储结构
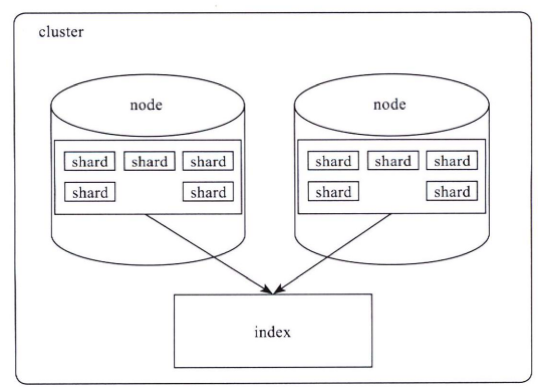
- ElasticSearch中每个index由若干个shard组成,shard是Elasticsearch数据存储的最小单位,index的存储容量为所有shard的存储容量之和。
- Elasticsearch中的一个shard对应Lucene中的索引,而Lucene索引又被分解为多个Segments
6.1.2. Lucene索引结构
Each segment index maintains the following:
- Segment info. This contains metadata about a segment, such as the number of documents, what files it uses, and information about how the segment is sorted
- Field names. This contains metadata about the set of named fields used in the index.
- Stored Field values. This contains, for each document, a list of attribute-value pairs, where the attributes are field names. These are used to store auxiliary information about the document, such as its title, url, or an identifier to access a database. The set of stored fields are what is returned for each hit when searching. This is keyed by document number.
- Term dictionary. A dictionary containing all of the terms used in all of the indexed fields of all of the documents. The dictionary also contains the number of documents which contain the term, and pointers to the term's frequency and proximity data.
- Term Frequency data. For each term in the dictionary, the numbers of all the documents that contain that term, and the frequency of the term in that document, unless frequencies are omitted (IndexOptions.DOCS)
- Term Proximity data. For each term in the dictionary, the positions that the term occurs in each document. Note that this will not exist if all fields in all documents omit position data.
- Normalization factors. For each field in each document, a value is stored that is multiplied into the score for hits on that field.
- Term Vectors. For each field in each document, the term vector (sometimes called document vector) may be stored. A term vector consists of term text and term frequency. To add Term Vectors to your index see the Field constructors
- Per-document values. Like stored values, these are also keyed by document number, but are generally intended to be loaded into main memory for fast access. Whereas stored values are generally intended for summary results from searches, per-document values are useful for things like scoring factors.
- Live documents. An optional file indicating which documents are live.
- Point values. Optional pair of files, recording dimensionally indexed fields, to enable fast numeric range filtering and large numeric values like BigInteger and BigDecimal (1D) and geographic shape intersection (2D, 3D).
- Vector values. The vector format stores numeric vectors in a format optimized for random access and computation, supporting high-dimensional nearest-neighbor search.
6.1.3. Lucene文件类型
| Name | Extension | Brief Description |
| segments_N | Stores information about a commit point | |
| write.lock | The Write lock prevents multiple IndexWriters from writing to the same file. | |
| .si | Stores metadata about a segment | |
| .cfs, .cfe | An optional "virtual" file consisting of all the other index files for systems that frequently run out of file handles. | |
| .fnm | Stores information about the fields | |
| .fdx | Contains pointers to field data | |
| .fdt | The stored fields for documents | |
| .tim | The term dictionary, stores term info | |
| .tip | The index into the Term Dictionary | |
| .doc | Contains the list of docs which contain each term along with frequency | |
| .pos | Stores position information about where a term occurs in the index | |
| .pay | Stores additional per-position metadata information such as character offsets and user payloads | |
| .nvd, .nvm | Encodes length and boost factors for docs and fields | |
| .dvd, .dvm | Encodes additional scoring factors or other per-document information. | |
| .tvx | Stores offset into the document data file | |
| .tvd | Contains term vector data. | |
| .liv | Info about what documents are live | |
| .dii, .dim | Holds indexed points | |
| .vec, .vem, .veq, vex | Holds indexed vectors; .vec files contain the raw vector data, .vem the vector metadata, .veq the quantized vector data, and .vex the hnsw graph data. |
6.1.4. 倒排索引
是一种索引方法,被用来存储在全文搜索下某个单词在一个文档或者一组文档中的存储位置的映射。它是文档检索系统中最常用的数据结构。















 1824
1824











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









