







*
1. 什么是Storm
Storm是Twitter开源的一个分布式的实时计算系统。
2. Storm的设计思想
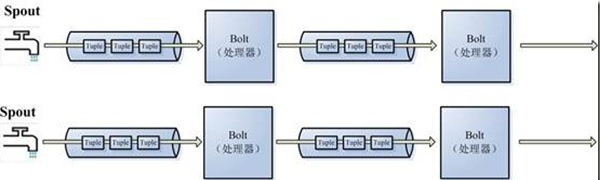
-
- Storm是对流Stream的抽象,流是一个不间断的无界的连续tuple,注意Storm在建模事件流时,把流中的事件抽象为tuple即元组。
- Storm将流中元素抽象为Tuple,一个tuple就是一个值列表value
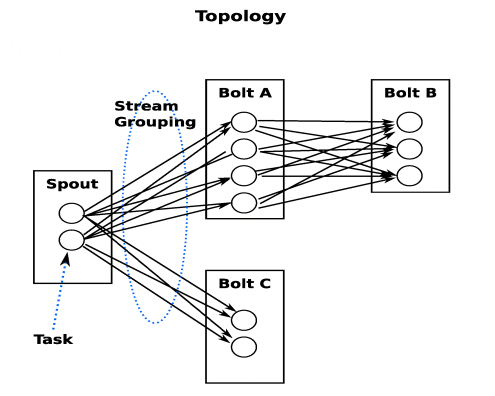
list,list中的每个value都有一个name,并且该value可以是基本类型,字符类型,字节数组等,当然也可以是其他可序列化的类型。 - Storm认为每个stream都有一个stream源,也就是原始元组的源头,所以它将这个源头称为Spout。
- 有了源头即spout也就是有了stream,那么该如何处理stream内的tuple呢。将流的状态转换称为Bolt,bolt可以消费任意数量的输入流,只要将流方向导向该bolt,同时它也可以发送新的流给其他bolt使用,这样一来,只要打开特定的spout(管口)再将spout中流出的tuple导向特定的bolt,又bolt对导入的流做处理后再导向其他bolt或者目的地。
- 以上处理过程统称为Topology即拓扑。拓扑是storm中最高层次的一个抽象概念,它可以被提交到storm集群执行,一个拓扑就是一个流转换图,图中每个节点是一个spout或者bolt,图中的边表示bolt订阅了哪些流,当spout或者bolt发送元组到流时,它就发送元组到每个订阅了该流的bolt(这就意味着不需要我们手工拉管道,只要预先订阅,spout就会将流发到适当bolt上)。
- 拓扑的每个节点都要说明它所发射出的元组的字段的name,其他节点只需要订阅该name就可以接收处理。
3.Storm集群结构
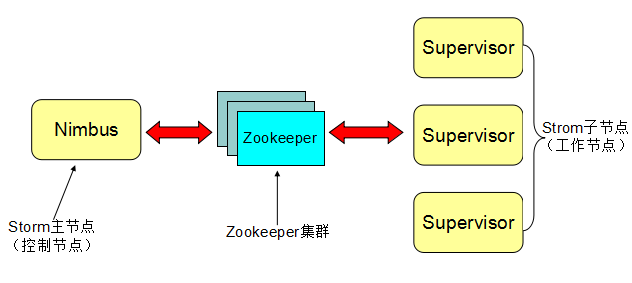
- Storm集群表面类似Hadoop集群。但在Hadoop上你运行是”MapReduce
jobs”,在Storm上你运行的是”topologies”。”Jobs”和”topologies”是大不同的,一个关键不同是一个MapReduce的Job最终会结束,而一个topology永远处理消息(或直到你kill它)。 - Storm集群有两种节点:控制(master)节点和工作者(worker)节点。
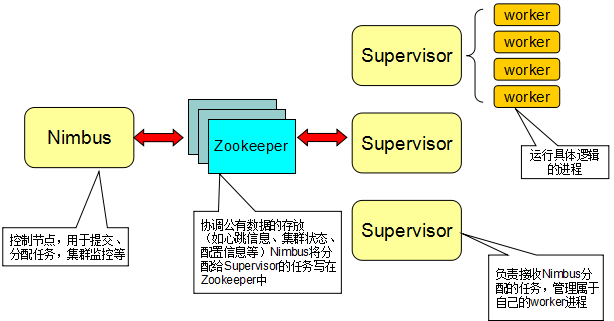
- 控制节点运行一个称之为”Nimbus”的后台程序,它类似于Haddop的”JobTracker”。Nimbus负责在集群范围内分发代码、为worker分配任务和故障监测。
- 每个工作者节点运行一个称之”Supervisor”的后台程序。Supervisor监听分配给它所在机器的工作,基于Nimbus分配给它的事情来决定启动或停止工作者进程。每个工作者进程执行一个topology的子集(也就是一个子拓扑结构);一个运行中的topology由许多跨多个机器的工作者进程组成。
- 一个Zookeeper集群负责Nimbus和多个Supervisor之间的所有协调工作(一个完整的拓扑可能被分为多个子拓扑并由多个supervisor完成)。
- 此外,Nimbus后台程序和Supervisor后台程序都是快速失败(fail-fast)和无状态的;所有状态维持在Zookeeper或本地磁盘。这意味着你可以kill -9杀掉nimbus进程和supervisor进程,然后重启,它们将恢复状态并继续工作,就像什么也没发生。这种设计使storm极其稳定。这种设计中Master并没有直接和worker通信,而是借助一个中介Zookeeper,这样一来可以分离master和worker的依赖,将状态信息存放在zookeeper集群内以快速回复任何失败的一方。
4.Storm的重要概念
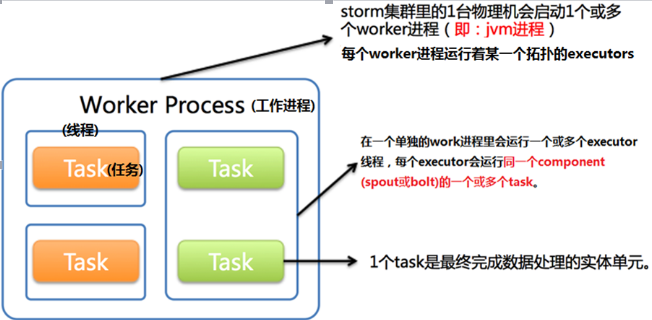
- worker:
Supervisor会监听分配给它那台机器的工作,根据需要启动/关闭工作进程,这个工作进程就是worker
每一个worker都会占用工作节点的一个端口,这个端口可以在storm.yarm中配置。
一个topology可能会在一个或者多个工作进程里面执行,每个工作进程执行整个topology的一部分,所以一个运行的topology由运行在很多机器上的很多工作进程组成。 - Task:
每一个Spout和Bolt会被当作很多task在整个集群里面执行。默认情况下每一个task对应到一个线程(Executor),这个线程用来执行这个task,而stream grouping则是定义怎么从一堆task发射tuple到另外一堆task。 - 每台supervisor运行着若干个Worker进程,每个Worker进程运行着若干个Executor线程,每个Executor线程运行着同一个component(Spout或Bolt)的一个或多个task。
- Config(配置):
storm里面有一堆参数可以配置来调整nimbus, supervisor以及正在运行的topology的行为, 一些配置是系统级别的, 一些配置是topology级别的。所有有默认值的配置的默认配置是配置在default.xml里面的。你可以通过定义个storm.xml在你的classpath厘米来覆盖这些默认配置。并且你也可以在代码里面设置一些topology相关的配置信息 – 使用StormSubmitter。当然,这些配置的优先级是: default.xml < storm.xml < TOPOLOGY-SPECIFIC配置。 - Stream Grouping(消息分发策略):
Shuffle Grouping:随机分组,随机派发stream里面的tuple,保证每个bolt接收到的tuple数目相同。
FieldsGrouping:按字段分组,比如按userid来分组,具有同样userid的tuple会被分到相同的Bolts,而不同的userid则会被分配到不同的Bolts。
All Grouping:广播发送,对于每一个tuple,所有的Bolts都会收到。
Global Grouping:全局分组,这个tuple被分配到storm中的一个bolt的其中一个task。再具体一点就是分配给id值最低的那个task。
NonGrouping:不分组,这个分组的意思是说stream不关心到底谁会收到它的tuple。目前这种分组和Shuffle grouping是一样的效果,有一点不同的是storm会把这个bolt放到这个bolt的订阅者同一个线程里面去执行。
- Direct Grouping:直接分组,
这是一种比较特别的分组方法,用这种分组意味着消息的发送者指定由消息接收者的哪个task处理这个消息。只有被声明为Direct Stream的消息流可以声明这种分组方法。而且这种消息tuple必须使用emitDirect方法来发射。消息处理者可以通过TopologyContext来获取处理它的消息的taskid
(OutputCollector.emit方法也会返回taskid)。
5.Storm可靠性:
1、worker进程挂掉
storm会重新再启动一个worker
2、supervisor进程挂掉
不会影响之前已经提交的topology,只是后期不会再向这个节点分配任务了。
3、nimbus进程挂掉
不会影响之前已经提交的topology,只是后期不能再向集群提交topology了。
4、ack/fail消息确认机制(确保一个tuple被完全处理)
在spout中发射tuple的时候需要同时发送messageid,这样才相当于开启了消息确认机制
如果你的topology里面的tuple比较多的话, 那么把acker的数量设置多一点,效率会高一点。
通过config.setNumAckers(num)来设置一个topology里面的acker的数量,默认值是1。
注意: acker用了特殊的算法,使得对于追踪每个spout tuple的状态所需要的内存量是恒定的(20 bytes)
注意:如果一个tuple在指定的timeout(Config.TOPOLOGY_MESSAGE_TIMEOUT_SECS默认值为30秒)时间内没有被成功处理,那么这个tuple会被认为处理失败了。















 849
849

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









