







一些知识点:
1. Spark On Yarn的本质?
一句话:Spark程序运行在Yarn容器内部。
资源管理层面:
StandAlone中的Master角色由YARN的ResourceManager担任
StandAlone中的Woker角色由YARN的NodeManager 担任
任务运行层面:
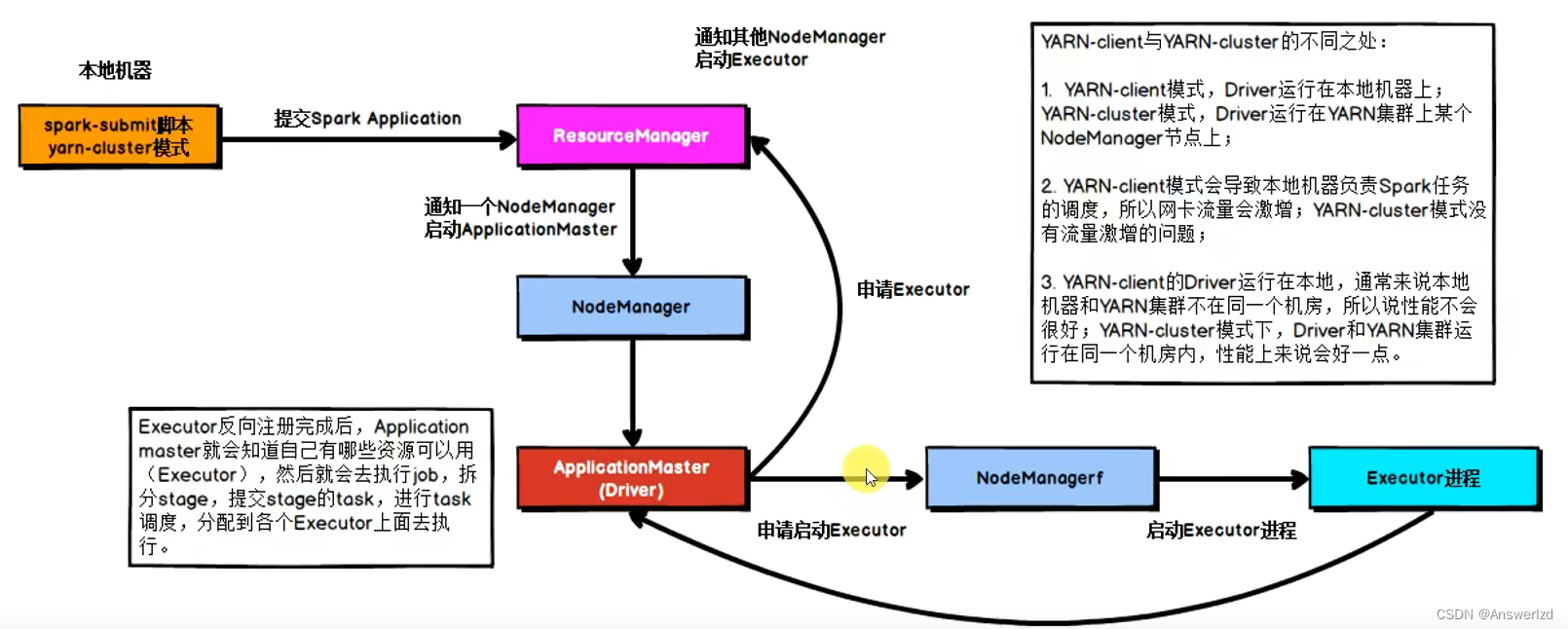
Driver角色运行在YARN容器内 或 提交任务的客户端进程中
Exectuor运行在YARN提供的容器内
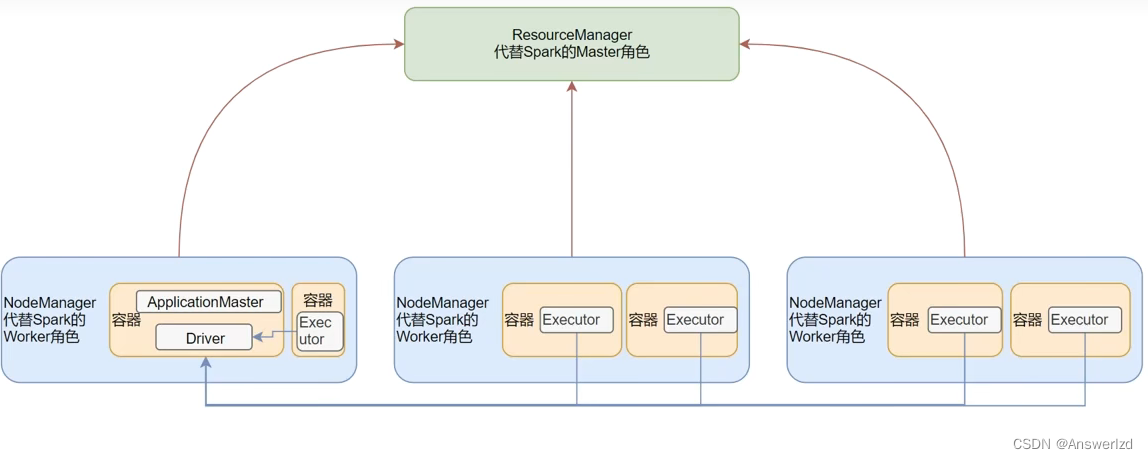
总之,Spark On Yarn就是让Spark运行在Yarn容器内部,资源管理交给Yarn的ResourceManager and NodeManager.
2. Sparn On Yarn的准备
- 安装好Yarn集群
- 有一台机器安装Spark客户端工具,比如spark-submit, this tool can submit jobs into YARN
- 被提交的代码程序,spark/example/src/main/python/pi.py
3. 部署时确保 HARDOOP_CONF_DIR 和 YARN_CONF_DIR在spark-env.sh以及 环境变量文件中
4. 连接到YARN中
bin/pyspark --master yarn
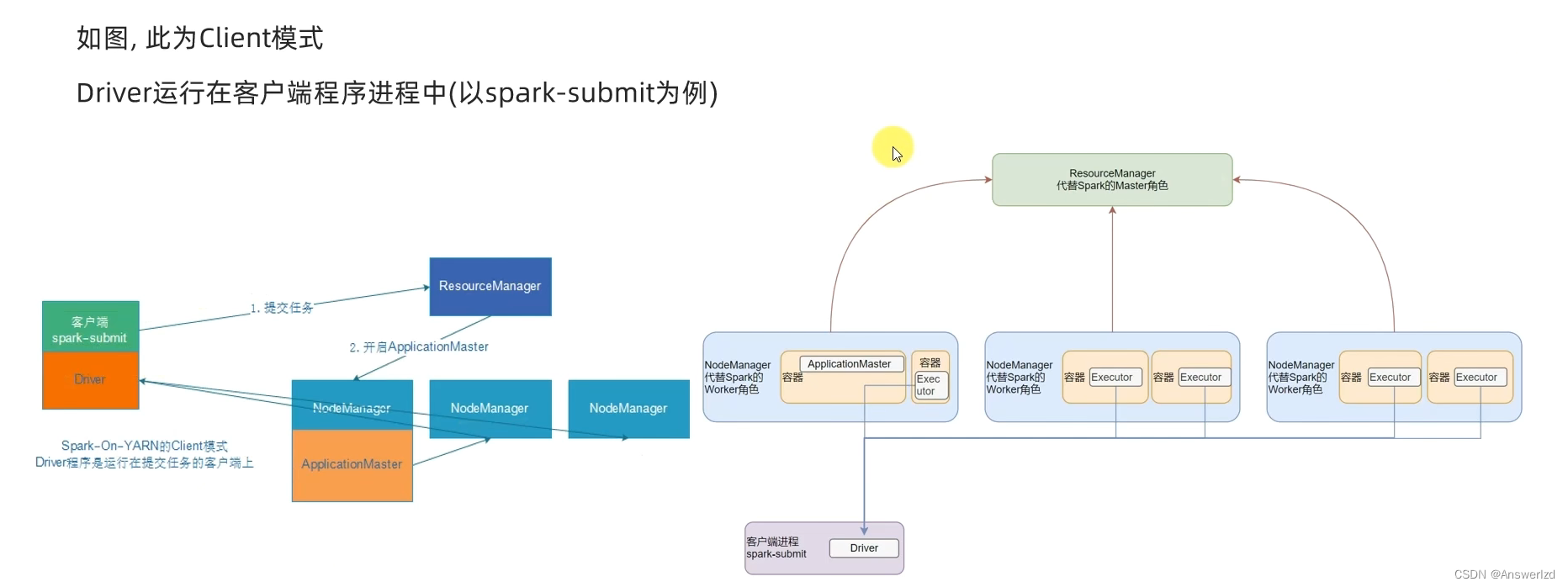
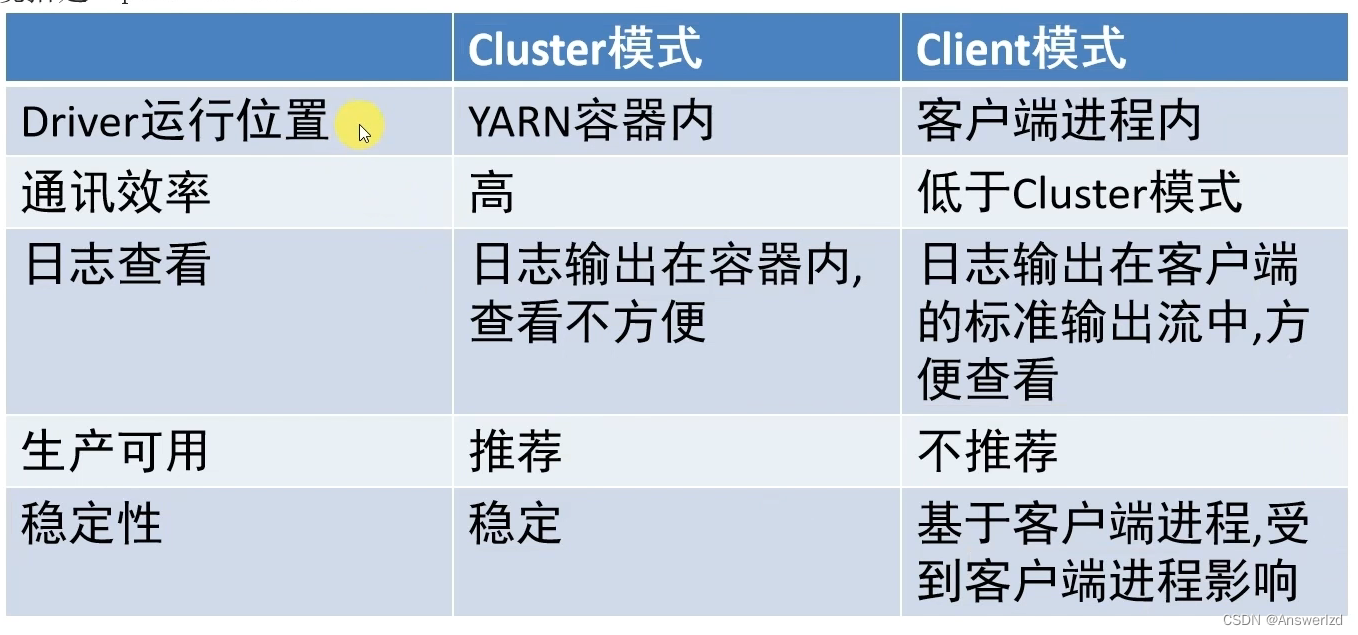
5. DeployMode
Spark On Yarn有两种运行模式,分别为Cluster and Client,区别在于Driver运行的位置
- Cluster: Driver运行在YARN容器内部,和ApplicationMaster在同一个容器内
- Client: Driver运行在客户端进程中,比如运行在spark-submit程序的进程中
bin/spark-submit --master yarn --deploy-mode client test.py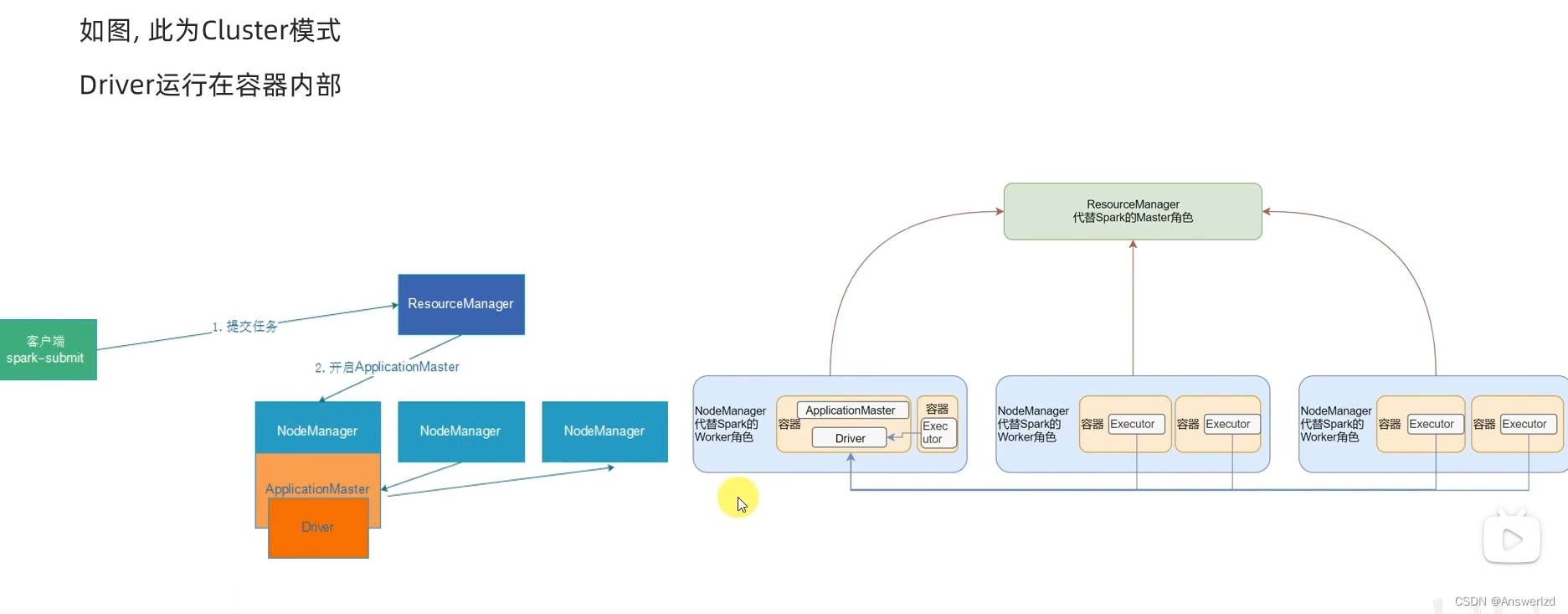
优缺点:
Cluster通讯成本低,因为Driver在YARN容器内部,不需要跨集群
Cluster模式看日志不太方便
客户端模式的提交流程: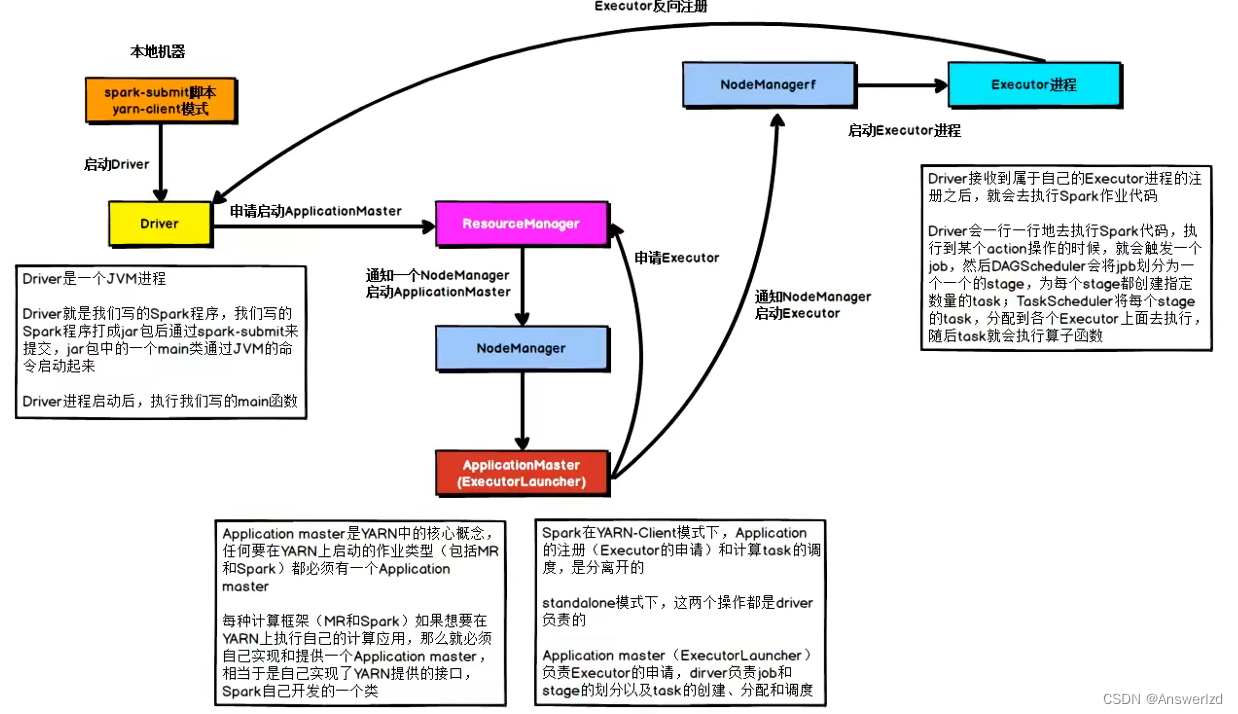
集群模式的提交流程:
REF:















 1014
1014











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









