






近日,一年一度的 CVPR 2025 公布论文录用结果!今年,共有 13008 份有效投稿并进入评审流程,其中 2878 篇被录用,最终录用率为22.1%。
蚂蚁技术研究院交互智能实验室共有 21 篇论文被录用,内容涵盖 视觉生成,视觉编辑,三维视觉,数字人等研究方向。
以下为交互智能实验室部分入选论文的介绍:
MagicQuill
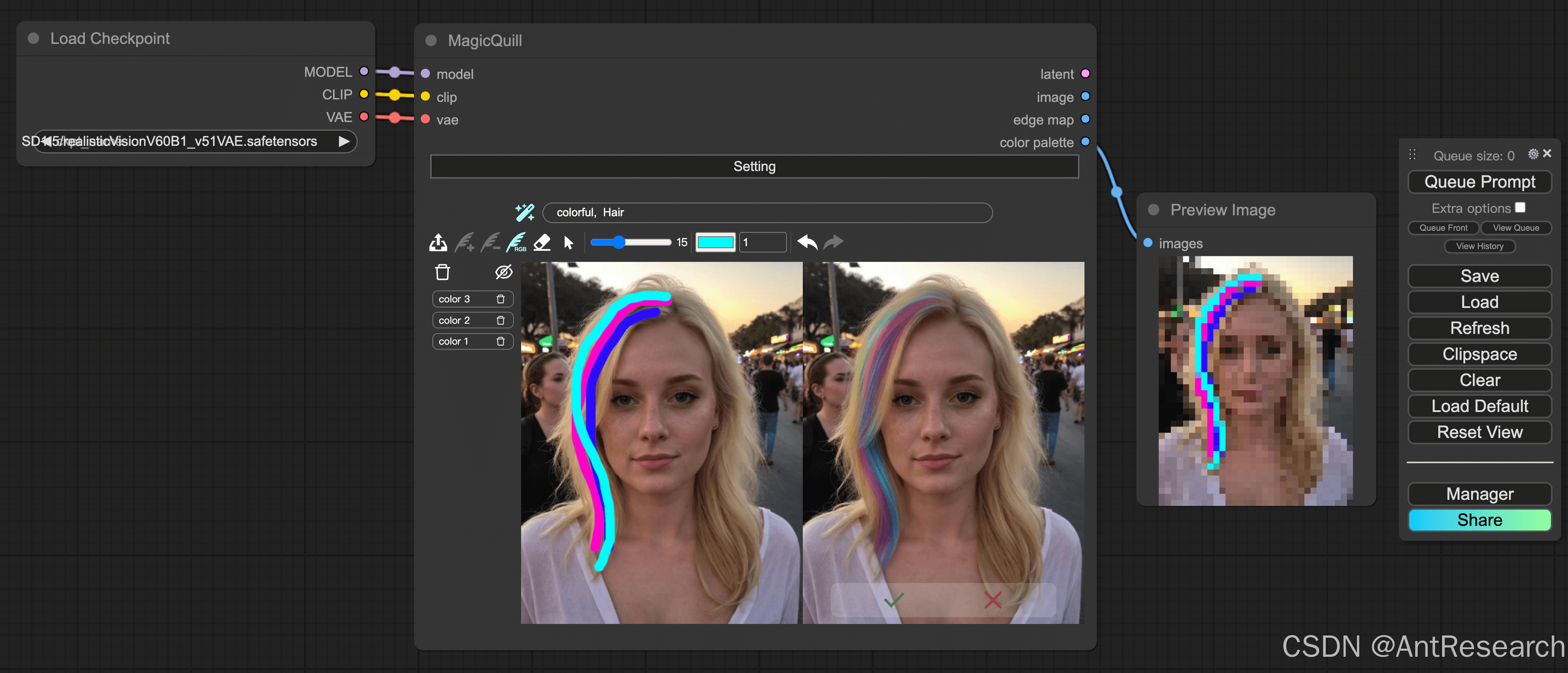
MagicQuill 是一个交互式的 AI 图片编辑工具,通过结合“编辑处理器”、“绘画助手”和“创意收集器”三大功能,成功解决了图片的精准、高效编辑的难题。用户只需要用三种简单直观的魔法画笔就能轻松编辑图片:添加、删除和上色。系统通过多模态大语言模型 (MLLM) 动态预测用户的操作意图,并提供相关的编辑建议。
论文地址:https://arxiv.org/abs/2411.09703
开源代码:https://github.com/ant-research/MagicQuill
HuggingFace Demo:https://huggingface.co/spaces/AI4Editing/MagicQuill
ModelScope Deml:https://modelscope.cn/studios/ant-research/MagicQuill_demo
Lumos
 尽管文本到图像(T2I)模型最近作为视觉生成先验得到了蓬勃发展,但它们对高质量文本-图像对的依赖使得扩展成本高昂。我们认为,对于一个稳健的视觉生成先验来说,掌握跨模态对齐并非必要,其重点应放在纹理建模上。这种理念启发我们研究图像到图像(I2I)生成,其中模型可以从野外图像中以自监督的方式学习。
尽管文本到图像(T2I)模型最近作为视觉生成先验得到了蓬勃发展,但它们对高质量文本-图像对的依赖使得扩展成本高昂。我们认为,对于一个稳健的视觉生成先验来说,掌握跨模态对齐并非必要,其重点应放在纹理建模上。这种理念启发我们研究图像到图像(I2I)生成,其中模型可以从野外图像中以自监督的方式学习。
首先,我们开发了一个纯粹基于视觉的训练框架Lumos,并确认了学习I2I模型的可行性和可扩展性。然后,我们发现,作为T2I的一个上游任务,我们的I2I模型提供了更为基础的视觉先验,并且仅使用1/10的文本-图像对进行微调,就能实现与现有T2I模型相当甚至更好的性能。进一步地,我们在一些与文本无关的视觉生成任务上展示了I2I先验优于T2I先验的优势,比如图像到3D和图像到视频的转换。
论文地址:https://arxiv.org/abs/2412.07767
开源代码:https://github.com/ant-research/lumos
Aurora

由于难以scaling up,生成对抗网络(GANs)在文本条件图像生成任务中似乎不再受欢迎。稀疏激活的专家混合(MoE)模型最近被证明是以有限资源训练大规模模型的有效解决方案。受到这一点的启发,我们提出了Aurora,这是一种基于GAN的文本到图像生成器,使用多个专家来学习特征处理,并结合一个稀疏路由器自适应选择最适合每个特征点的专家。我们采用两阶段的训练策略,首先在64x64分辨率下学习一个基础模型,然后通过一个上采样器生成512×512的图像。仅使用公共数据进行训练,我们的方法缩小了GANs与工业级扩散模型之间的性能差距,同时保持了快速的推理速度。我们将公布代码和权重,以便于社区对GANs进行更全面的研究。
论文地址:https://arxiv.org/abs/2309.03904
开源代码:https://github.com/ant-research/Aurora
FLARE

FLARE 是一个前向推理模型,旨在从未校准的稀疏视角图像(即最少只需2-8张输入图像)中推断出高质量的相机姿态和3D几何结构。这种设置在实际应用中既具有挑战性又非常实用。我们的解决方案采用了一种级联学习范式,把相机姿态作为关键桥梁。
具体来说,FLARE从相机姿态估计开始,其结果用于条件化后续的几何结构和外观学习,这些学习过程通过几何重建和新视角合成的目标进行优化。利用大规模公开数据集进行训练,我们的方法在姿态估计、几何重建和新视角合成任务中达到了最先进的性能,同时保持了高效的推理速度(即不到0.5秒)。
论文地址:https://arxiv.org/abs/2502.12138
开源代码:https://github.com/ant-research/FLARE
Levitor
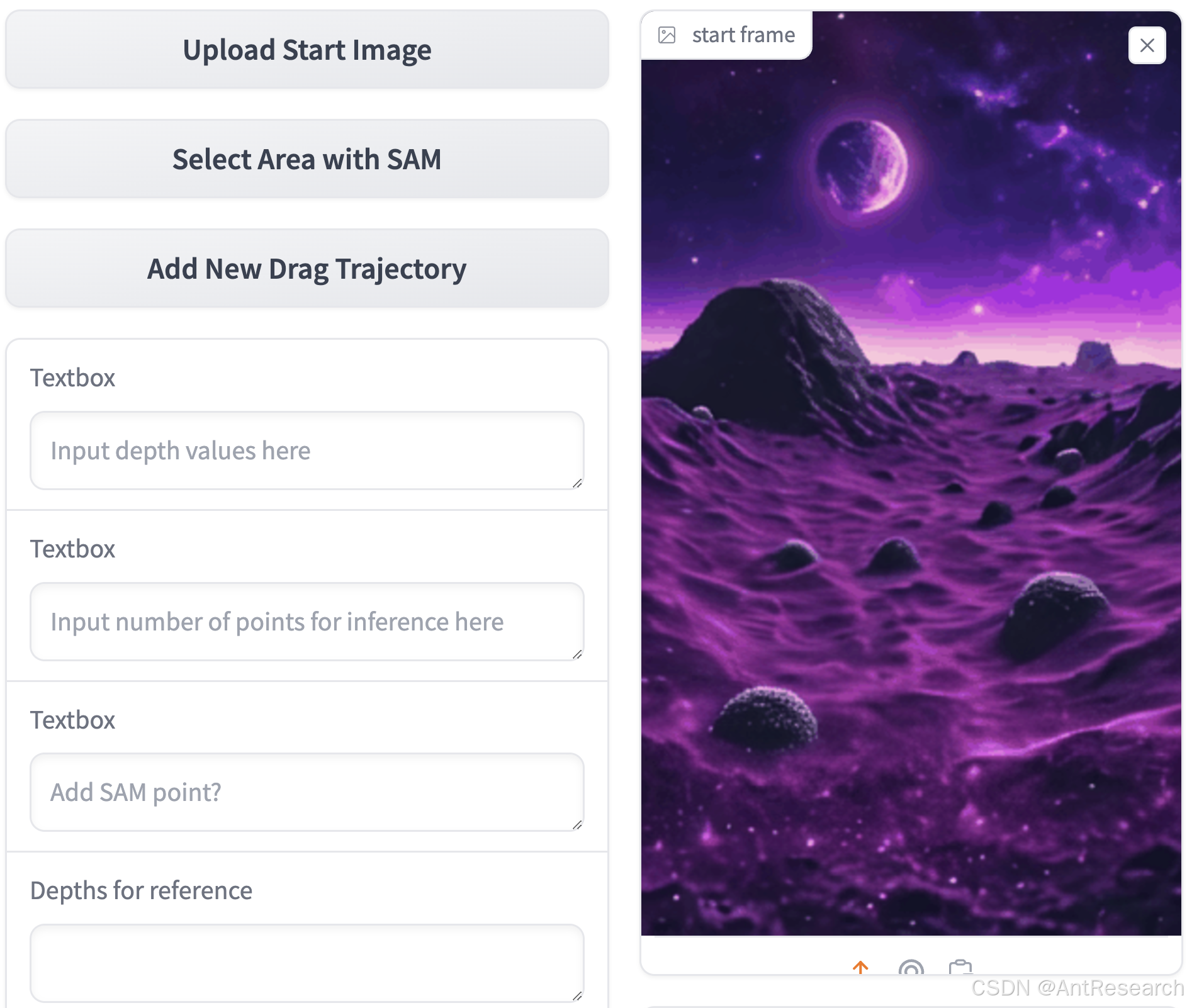
基于拖拽的交互直观特性使其在图像到视频合成中控制对象轨迹的应用越来越广泛。然而,现有在二维空间中执行拖拽的方法通常在处理非平面移动时会遇到模糊性问题。在这项工作中,我们通过引入一个新的维度——即深度维度——来增强这种交互方式,使得用户能够为轨迹上的每个点分配一个相对深度。这样一来,我们的新交互模式不仅继承了2D拖拽的便捷性,还便于在三维空间中进行轨迹控制,扩大了创造性的范围。我们提出了一种开创性的方法,在图像到视频合成中实现3D轨迹控制,该方法通过将对象蒙版抽象成几个聚类点来实现。这些点与深度信息和实例信息一起,最终作为控制信号输入到视频扩散模型中。广泛的实验验证了我们称之为LeviTor的方法的有效性,证明其在从静态图像生成逼真视频时能精确操控对象运动。
论文地址:https://arxiv.org/abs/2412.15214
开源代码:https://github.com/ant-research/LeviTor
MangaNinja

源自扩散模型的MangaNinjia专注于参考引导的线稿上色任务。为了确保角色细节的精确转录,我们融入了两个精心设计的功能:一个是补丁打乱模块,用于促进参考彩色图像与目标线稿之间的对应学习;另一个是点驱动控制方案,以实现细粒度的颜色匹配。
在我们自行收集的基准测试上的实验表明,我们的模型在精确上色方面超越了现有的解决方案。我们进一步展示了所提出的交互式点控制在处理挑战性案例、跨角色上色以及多参考协调方面的潜力,这些都是现有算法难以企及的。
具体来说,MangaNinjia不仅能够高效地将黑白线稿转换为色彩丰富且细节准确的图像,还通过其独特的技术解决了不同角色或多个参考图之间颜色协调的问题。这种创新方法使得用户可以更加灵活和精细地控制最终的上色效果,从而极大地提高了创作自由度和作品质量。
论文地址:https://arxiv.org/abs/2501.08332
开源代码:https://github.com/ali-vilab/MangaNinjia
Anidoc



2D动画的制作遵循行业标准的工作流程,涵盖了四个关键阶段:角色设计、关键帧动画、中间帧绘制以及上色。我们的研究专注于通过利用日益强大的生成式AI的潜力来降低上述过程中的劳动力成本。基于视频扩散模型,我们推出了AniDoc,这是一个视频线稿上色工具,它可以依据参考角色设定自动将草图序列转换为彩色动画。我们的模型利用了对应匹配作为明确指导,对参考角色与每个线稿帧之间的变化(如姿势)展现了强大的鲁棒性。此外,我们的模型甚至可以自动化中间帧绘制过程,使得用户仅需提供一个角色图像以及起始和结束草图,就能轻松创建时间上一致的动画。这大大简化了动画创作流程,并显著减少了手工劳动的需求。
论文地址:https://arxiv.org/pdf/2412.14173
开源代码:https://github.com/ant-research/AniDoc
Mimir

文本由于其叙述性质,成为视频生成中的关键控制信号。为了将文本描述渲染成视频片段,当前的视频扩散模型借用了来自文本编码器的特征,但在有限的文本理解方面仍面临挑战。近期大型语言模型(LLMs)的成功展示了Decoder-only Transformers的强大功能,为文本到视频(T2V)生成带来了三个明显的优势:由卓越的可扩展性带来的精确文本理解、通过下一个标记预测实现超越输入文本的想象力、以及通过指令调整优先考虑用户兴趣的灵活性。
然而,由于两种不同的文本建模范式之间存在特征分布差距,直接在已建立的T2V模型中使用LLMs变得困难。这项工作通过Mimir解决了这一挑战,Mimir是一个端到端的训练框架,具有精心设计的Token Fuser,以协调文本编码器和LLMs的输出。这种设计使得T2V模型能够充分利用学习到的视频先验,同时利用LLMs与文本相关的功能。
广泛的定量和定性结果表明,Mimir在生成高质量视频时表现出色,特别是在处理短字幕和管理移动变化方面展现了优秀的文本理解能力。这不仅提升了视频生成的质量,还展示了如何有效结合不同技术优势来克服现有方法的局限性。通过这种方式,Mimir为未来的T2V研究和应用提供了新的方向和技术支持。
论文地址:https://arxiv.org/abs/2412.03085
项目主页:https://lucaria-academy.github.io/Mimir/
AvatarArtist
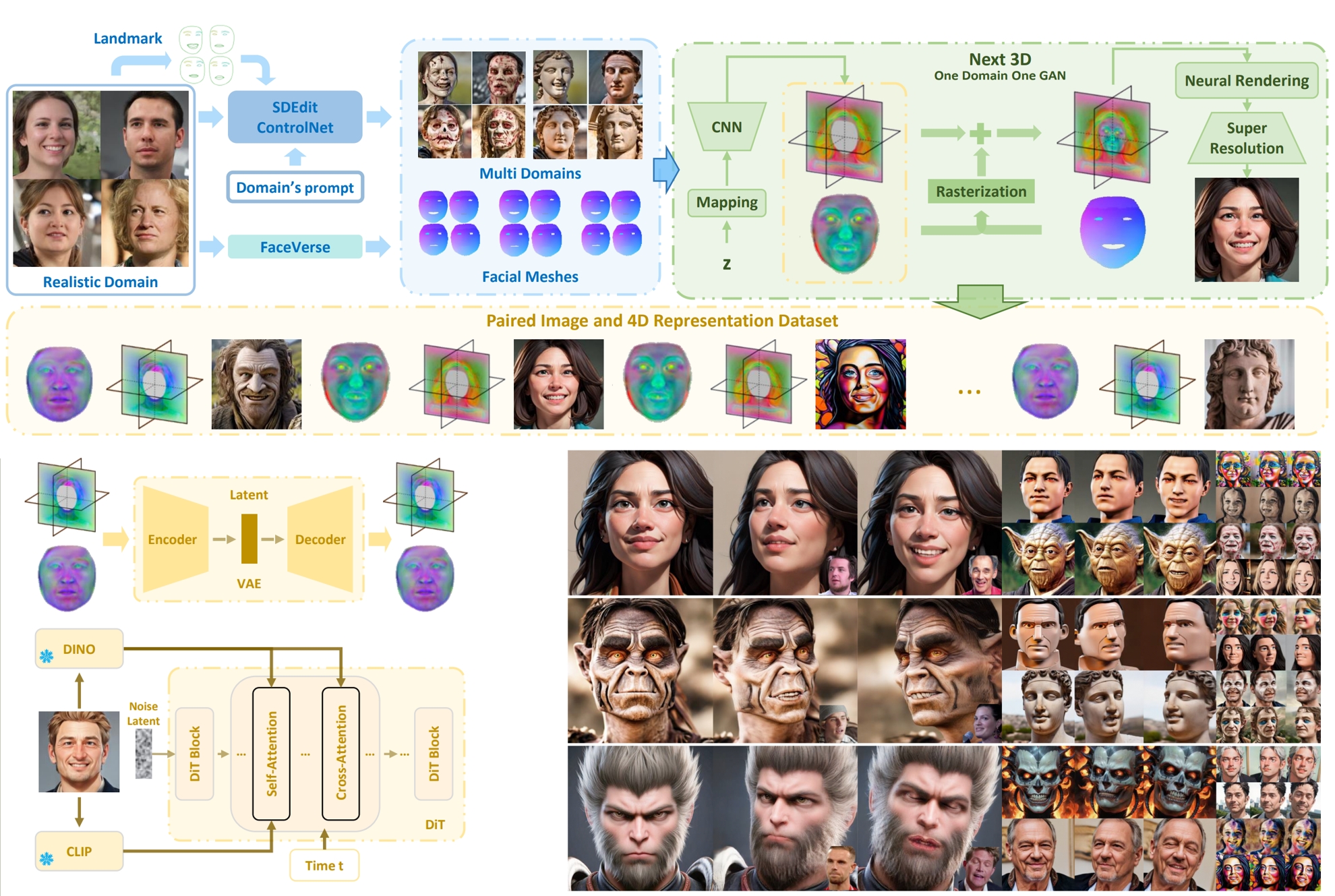
以往的 可动画 3D 头像(4D) 生成方法在处理 不同风格的输入 时存在较大挑战,尤其是在风格化图像等开放域场景下,容易出现 生成质量下降 或 身份不匹配 的问题。为此,本文提出了一种 从单张肖像图像生成可动画 3D 头像的方法,支持 任意风格,显著提升了 4D 头像生成的鲁棒性与泛化能力。
本方法通过融合 图像扩散模型先验 和 4D GAN 先验,采用 参数化三平面(parametric triplanes) 作为 4D 数据表征,从而合成风格多样的 4D 头像数据。在此基础上,我们采用 基于图像的 DiT 模型,从输入肖像图像预测 4D 头像的参数化三平面,并进一步引入 新型神经渲染器,以提升渲染质量,同时有效缓解身份泄漏问题,确保生成结果在不同风格下仍能保持高度的一致性与逼真度。
在实验部分,我们通过 定性分析、定量评估以及用户研究 对所提出的方法进行了系统验证。实验结果表明,本方法在 写实、卡通、素描等多种风格域 下均能生成高质量的 4D 头像,并在 动画流畅性、细节保真度以及身份一致性 方面显著超越现有方法。此外,用户研究进一步验证了本方法在视觉质量与风格迁移能力上的优越性,展现出极高的应用潜力。
DiffListener
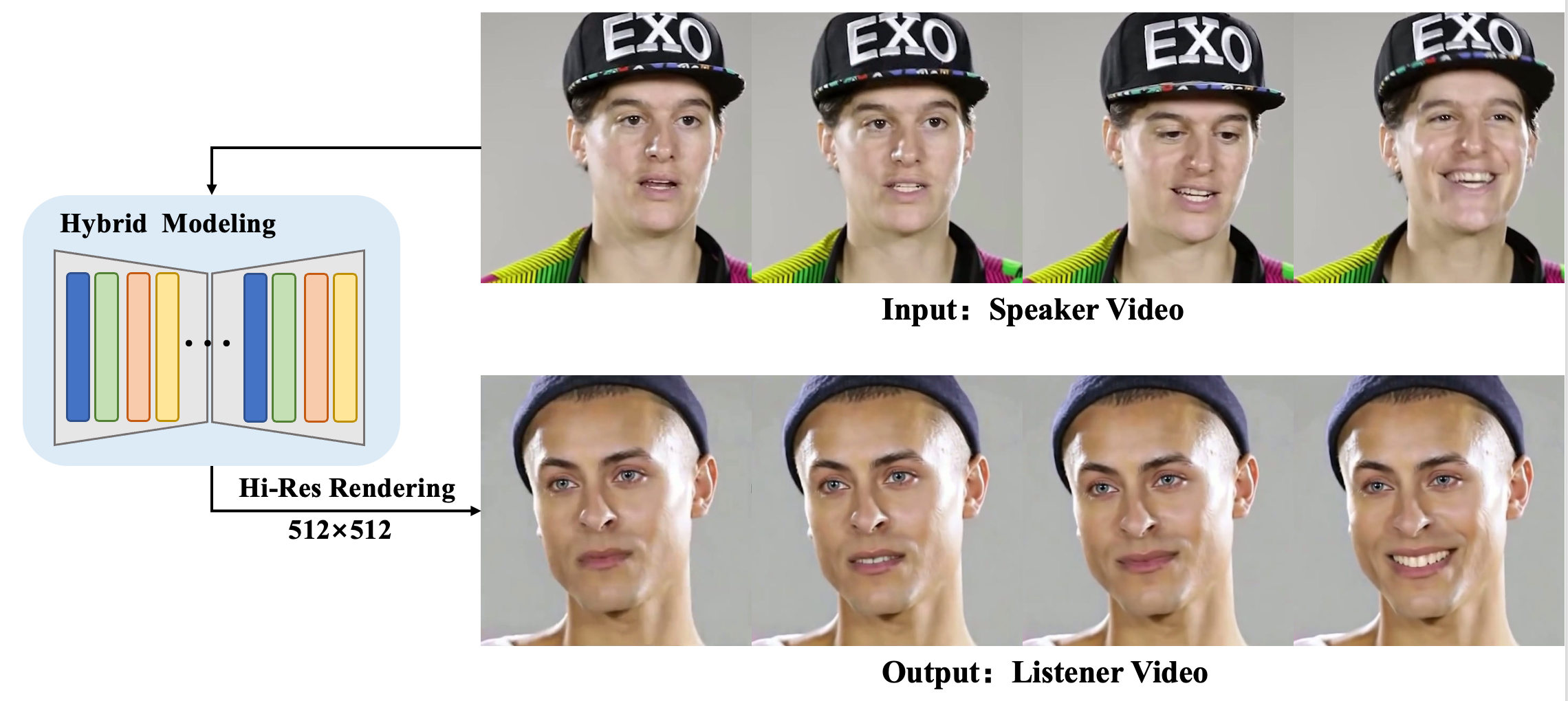
倾听者面部反馈动作生成旨在根据说话者语音和动作生成合理的的非语言面部反馈动作(如点头、皱眉等),以提高对话交互的自然度和沉浸感。现有的方法通常首先生成中间的3D运动信号,如3DMM系数,然后通过确定性渲染生成倾听者视频,但这受到 3DMM 运动表现力有限和渲染质量低(如256*256分辨率)的制约。
在本研究中,我们提出了一种新颖的倾听者面部动作生成方法,借助扩散模型的高清渲染能力实现512*512分辨率的动作生成。我们设计了一种有效的混合运动建模模块,解决了因倾听者训练数据稀缺而导致的扩散模型训练难题,同时设计隐式动作增强改善3DMM动作表达能力,设计姿态和表情特定的控制方法增强动作可控性。我们将公开代码和模型以促进社区研究。
Motionstone

图像到视频(I2V)生成依赖于静态图像,并且最近通过将运动强度作为额外的控制信号得到了增强。这些运动感知模型能够生成多种运动模式,但在大规模野外视频集上训练此类模型时,缺乏可靠的运动估计器。传统的度量标准,如SSIM或光流,难以推广到任意视频,同时人类标注者也很难为抽象的运动强度进行标注。此外,运动强度应当揭示局部对象运动和全局摄像机移动,而这在之前并未得到研究。
本文通过提出一种新的运动估计器来应对这一挑战,该估计器能够测量视频中物体和摄像机解耦后的运动强度。我们利用随机配对视频的对比学习方法,区分具有更大运动强度的视频。这种范式便于标注,并易于扩展以实现运动估计的稳定性能。
随后,我们介绍了一种使用解耦运动估计器开发的新I2V模型,命名为MotionStone。实验结果表明,所提出的运动估计器具有稳定性,而MotionStone在I2V生成方面达到了最先进的性能。这些优势使得解耦运动估计器可以作为一种通用插件增强器,既适用于数据处理,也适用于视频生成训练。
具体来说,MotionStone不仅能够准确捕捉和再现视频中的复杂运动模式,还通过其独特的解耦运动估计机制,提高了生成视频的质量和多样性。这种方法克服了现有技术的局限性,提供了一种更有效、更灵活的方式来处理图像到视频的转换任务。这对于需要高质量动态内容生成的应用场景尤为重要。
论文地址:https://arxiv.org/abs/2412.05848
TensorialGaussianAvatars
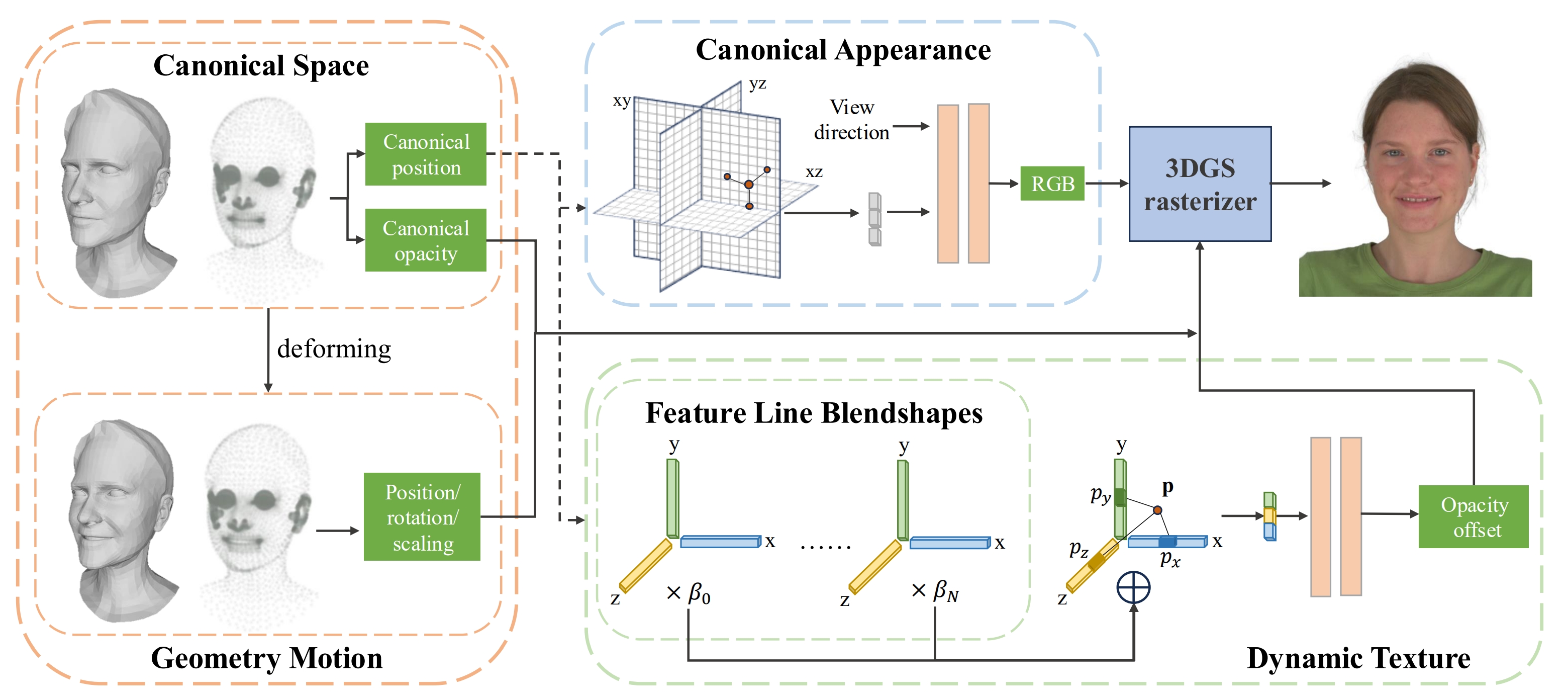
现有人头avatar重建方法为建模人脸随表情出现的动态细节需要极大的时间或空间开销。为了在确保实时性/低存储的前提下准确重建出人脸动态细节,我们引入了一种表达力强且紧凑的表示方法,将3D高斯的纹理相关属性编码为张量格式。
具体来说,我们将中性表情的外观存储在静态三平面中,并使用轻量级的1D特征线表示不同表情的动态纹理细节,这些特征线随后解码为相对于中性脸的透明度偏移。我们还提出了自适应截断透明度惩罚和类别平衡采样,以提高不同表情间的泛化能力。
实验表明,该设计能够准确捕捉面部动态细节,同时保持实时渲染并显著降低存储成本,从而拓宽了其应用场景。
DualTalk
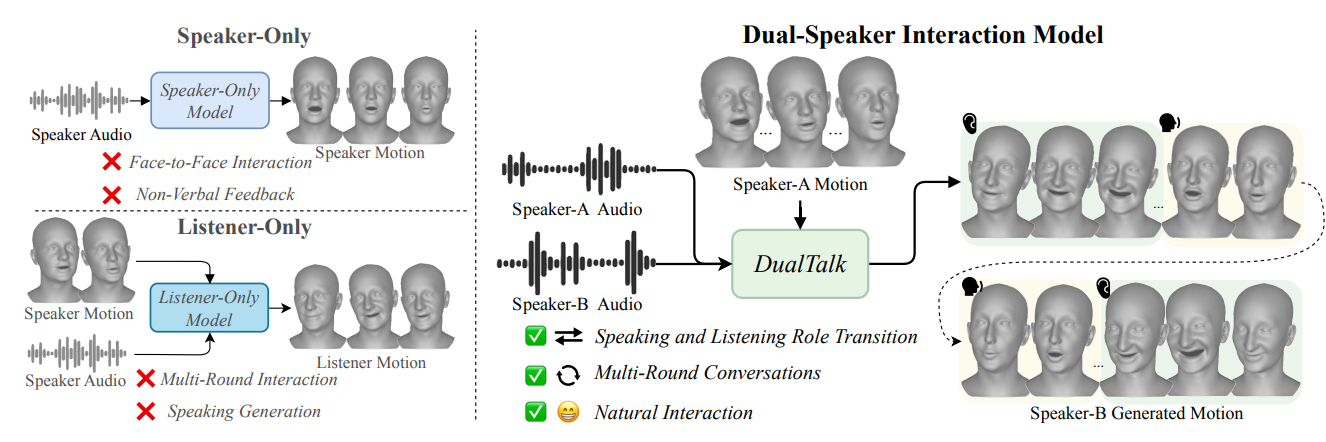
在面对面对话中,对话人需要在说话与倾听角色之间自然、连贯切换。现有的3D面部动作生成模型仅专注于单一说话或倾听行为,忽视了对话场景下的角色动态转换性,导致交互生硬且角色转换突兀。为解决这一局限,我们提出一项新任务——面向对话场景的3D面部动作生成,要求模型在连续对话中生成说话与倾听行为并保证状态切换的连贯性。为此,我们提出DualTalk框架,通过整合动态的说话者与倾听者行为,模拟真实连贯的对话交互。该框架不仅能在说话阶段生成逼真口型,还能在倾听阶段输出生动的非语言反馈(如点头、视线转移),有效捕捉角色间的互动关系。此外,我们构建了一个包含50小时多轮对话、涵盖1,000个ID的对话数据集。我们将公开代码与数据集以促进社区研究。
Comprecap
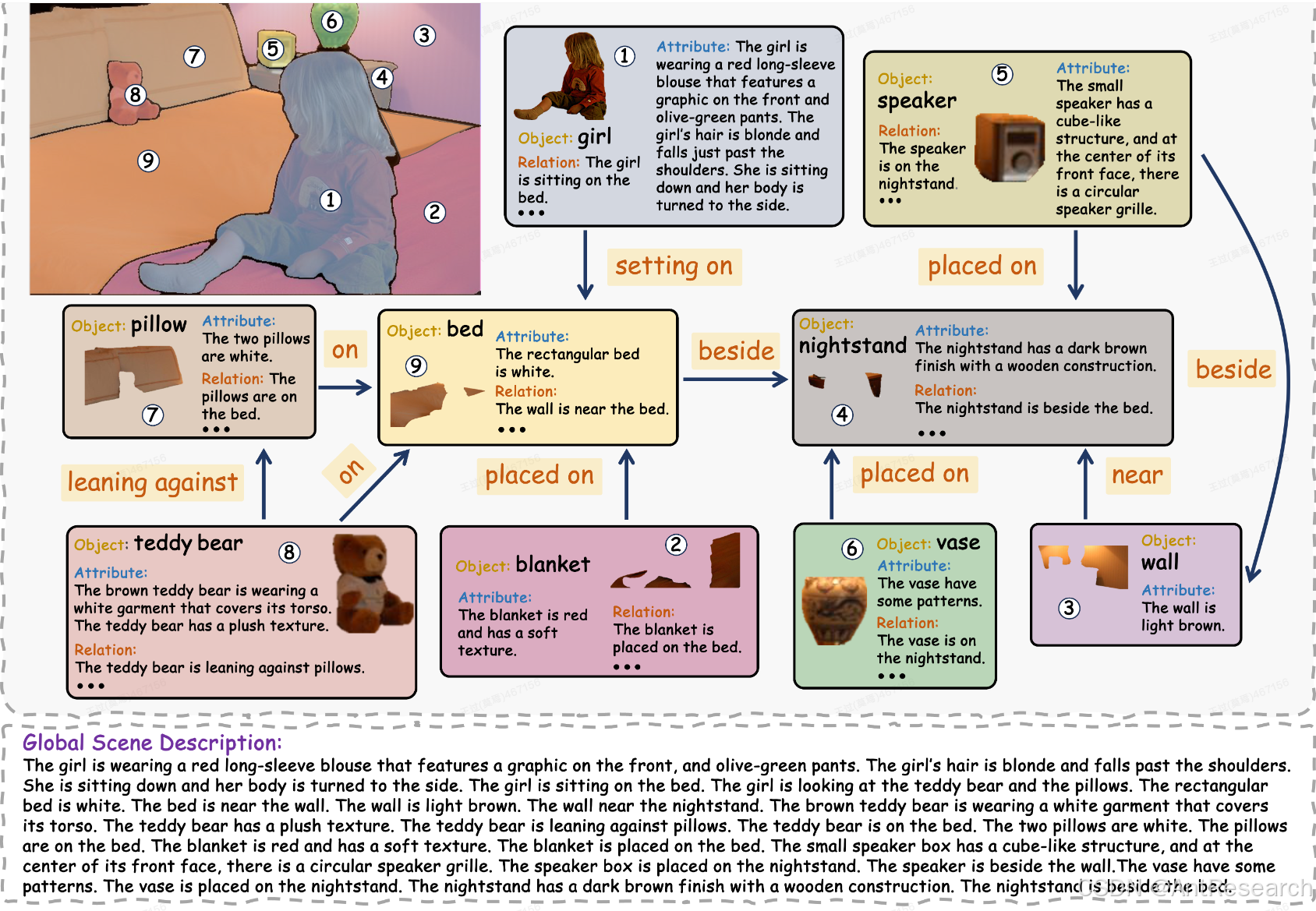
生成能够理解图像中丰富文本内容的详细字幕,已成为大型视觉-语言模型(LVLMs)研究中的一个热点。然而,目前鲜有研究开发专门针对详细字幕的基准来衡量其准确性和全面性。在本文中,我们介绍了一个名为CompreCap的详细字幕基准,用于从有向场景图视角评估视觉内容。
具体来说,我们首先根据常见的物体词汇表手动将图像分割成语义上有意义的区域(即语义分割掩码),同时区分这些区域内物体的属性。然后,我们对这些物体的方向关系进行标注,以组成一个能够很好地编码图像丰富组合信息的有向场景图。基于我们的有向场景图,我们开发了一个多层级的管道来评估LVLMs生成的详细字幕,包括对象级别的覆盖率、属性描述的准确性、关键关系得分等。
在CompreCap数据集上的实验结果证实,我们的评估方法与跨LVLMs的人类评估得分高度一致。这一成果不仅为LVLMs生成的详细字幕提供了一种有效的评估手段,还为进一步优化这些模型提供了重要的参考依据。通过这种方式,我们可以更准确地评估和提升LVLMs在理解和生成复杂视觉内容方面的性能。
论文地址:https://arxiv.org/abs/2412.08614
开源代码:https://github.com/LuFan31/CompreCap
Uni-AD
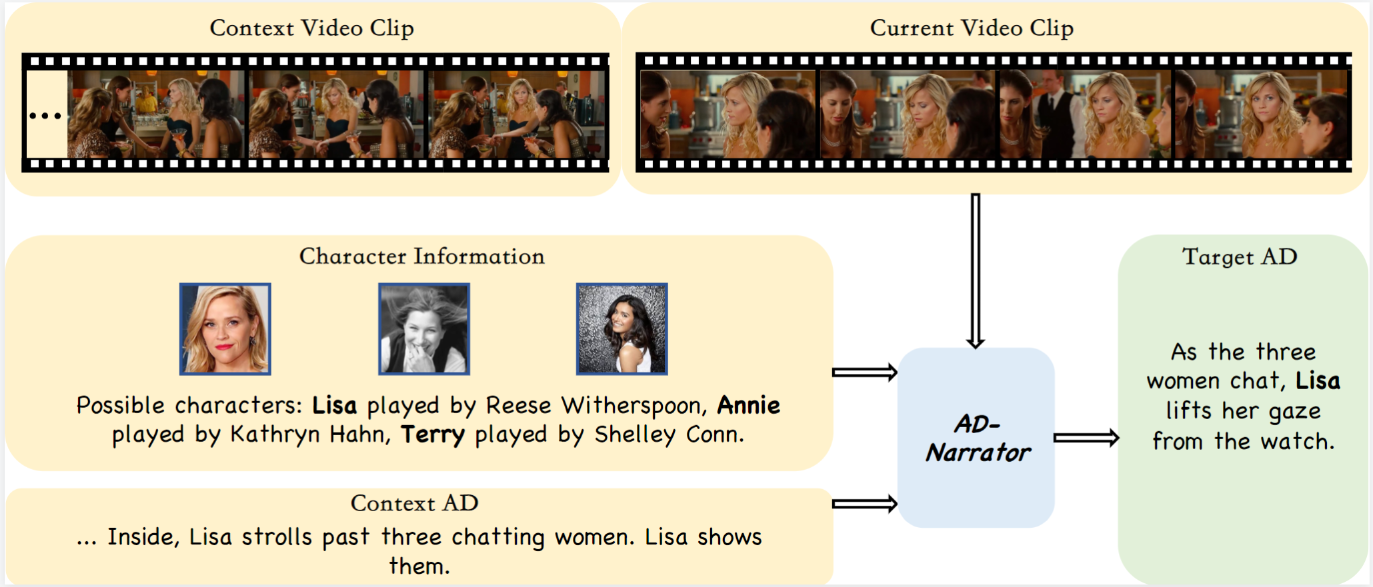
口述影像(Audio Description)任务旨在为视障人士生成视觉元素的描述,帮助他们理解电影等长视频内容。该方法以视频特征、文本、角色库及上下文信息为输入,通过生成角色名称关联的音频描述和符合语境的合理叙述,协助观众理解电影情节发展。为实现这一目标,我们提出基于预训练基础模型的统一框架Uni-AD,通过交错式多模态序列输入生成口述影像内容。我们设计了轻量级视频-文本特征映射模块来完成跨模态特征的细粒度对齐,同时也加入了角色优化模块来识别视频场景中的核心人物,从而提供精准信息支撑让模型关注主要角色来生成描述。进一步的,我们整合了上下文信息并引入对比损失函数,使生成的音频描述具备更好的流畅性和场景连贯性。
论文地址:https://arxiv.org/abs/2403.12922
关于蚂蚁技术研究院及交互智能实验室
2015年4月,蚂蚁技术研究院正式成立。面向数字化、智能化未来,瞄准世界科技前沿,推进关键核心技术攻关,促进“产学研用”深度融合,为做强、做大、做优数字技术贡献一份力量。作为蚂蚁集团未来科技创新发展的重要支撑,蚂蚁技术研究院致力做有用、有想象力的科研。
作为蚂蚁技术研究院首批落地建成的实验室,交互智能实验室聚焦视觉和 NLP 基础模型研究,开发通用人工智能算法架构,包括内容生成、多模态理解、数字人技术等人机交互关键技术。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









