







linux进程前后台切换
将后台进程放入前台
fg pid
将前台进程放在后台
bg pid提取json数据
cat data.json
{
"name": "xixi",
"age": 35,
"student": [
{"name": "xiaolin", "age": 20},
{"name": "anan", "age": 18}
]
}
提取以上json文件中name的值
jq '.name' data.json![]()
输出字符串格式
jq -r '.name' data.json ![]()
提取以上json文件student中name的值
jq '.student|map(.name)' data.json
提取以上json文件student中第一个name的值
jq '.student[0].name' data.json![]()
提取以上json文件student中xiaolin的age
jq '.student[]|select(.name=="xiaolin")|.age' data.json![]()
排序
sort
-b, --ignore-leading-blanks
忽略每一行前面的空白。例如,
sort -b file忽略行首空白进行排序-d, --dictionary-order
按照字典顺序排序,只考虑字母、数字和空格。例如,
sort -d file以字典顺序排序-f, --ignore-case
忽略大小写。例如,
sort -f file忽略大小写进行排序-g, --general-numeric-sort
按照一般数值顺序排序。例如,
sort -g file将数值顺序排序-i, --ignore-nonprinting
忽略非打印字符。例如,
sort -i file忽略非打印字符进行排序-M, --month-sort
按照月份排序(JAN, FEB, MAR, ...)。例如,
sort -M file按月份排序-n, --numeric-sort
按照数值顺序排序。例如,
sort -n file将数值按从小到大排序-h, --human-numeric-sort
按照人类可读的数值顺序排序,例如,1K、1M、1G。例如,
sort -h file将人类可读数值顺序排序-r, --reverse
反向排序。例如,
sort -r file反向排序输出-k, --key=POS1[,POS2]
以指定的字段排序。字段从 1 开始。例如,
sort -k 2 file以第二个字段排序-t, --field-separator=SEP
指定字段分隔符。默认是空白。例如,
sort -t, -k 2 file以逗号为分隔符,按第二个字段排序-o, --output=FILE
将排序结果输出到指定文件。例如,
sort -o sorted_file file将排序结果保存到sorted_file-u, --unique
输出唯一的行(去重)。例如,
sort -u file去除重复行-c, --check
检查输入是否已经排序。
sort -c file如果文件已经排序,则无输出;否则报错-C, --check=quiet
同
-c,但不输出错误信息。例如,sort -C file静默检查是否排序-m, --merge
合并已经排序的文件。例如,
sort -m sorted1 sorted2合并sorted1和sorted2-z, --zero-terminated
使用空字符(而不是新行)分隔输入。例如,
sort -z file处理用空字符分隔的输入行
用例
ps -ef |awk 'FR!=1 {print $2}'|sort -n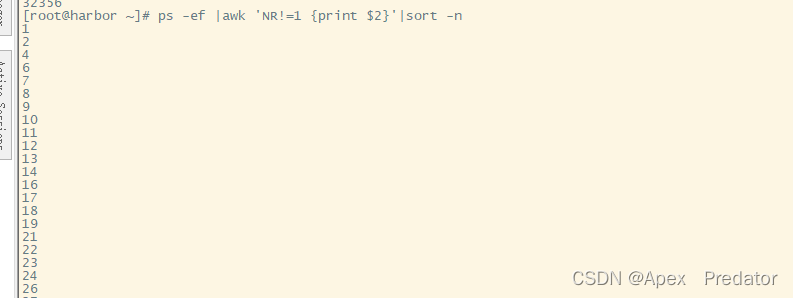
ps -ef |awk 'NR!=1 {print $2}'|sort -nr 
去除重复值
uniq
通常与 sort 命令结合使用,因为 uniq 只会处理相邻的重复行,而 sort 会将文件中的所有重复行排在一起
-c, --count
计算并显示每行出现的次数。例如,
uniq -c file会在每行前显示出现的次数-d, --repeated
仅显示重复出现的行。例如,
uniq -d file只输出重复的行-D, --all-repeated[=delimit-method]
显示所有重复的行,可以选择使用不同的分隔方法(例如,空行)。例如,
uniq -D file会输出所有重复行-i, --ignore-case
忽略大小写。例如,
uniq -i file忽略大小写比较行-f N, --skip-fields=N
跳过前 N 个字段。例如,
uniq -f 2 file忽略前两个字段进行比较-s N, --skip-chars=N
跳过每行前 N 个字符。例如,
uniq -s 3 file忽略前 3 个字符进行比较-w N, --check-chars=N
仅比较每行的前 N 个字符。例如,
uniq -w 5 file只比较每行的前 5 个字符
用例
sort cs.txt|unqi 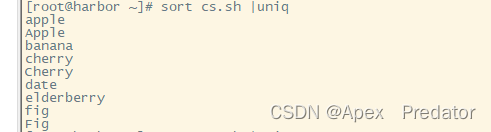
sort cs.txt|unqi -c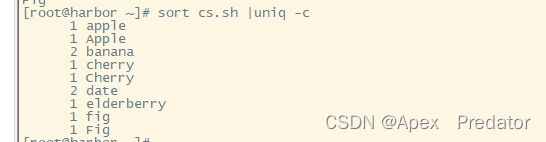
sort cs.sh |uniq -ci
传递值
xargs
用例
grep rl "data"|xargs rm -rf #查询包含data内容的文件,并删除取行列值
awk
常用参数
-F fs
指定字段分隔符。例如,
awk -F, '{ print $1 }' file将逗号作为分隔符-v var=value
定义一个变量。例如,
awk -v var=10 '{ print $1 + var }' file内置变量
$0
当前记录(整行文本)
$n
第 n 个字段,例如,$1 是第一个字段
NF
当前记录中的字段数
NR
已读的记录数(行号)
内置函数
length(string)
返回字符串的长度
substr(string, start, length)
返回子字符串
toupper(string)
将字符串转换为大写
tolower(string)
将字符串转换为小写
输出文本
用例
文本内容
apple,fruit,1.2
banana,fruit,0.5
carrot,vegetable,0.7
date,fruit,1.5
elderberry,fruit,2.0
fig,fruit,1.8awk -F, '{ print $1 }' file.txt
awk -F, '{print $1,$2}' file.txt 
awk -F, 'NR==1 {print $1,$2}' file.txt![]()
awk -F, '$2 == "fruit" { print toupper($1) }' file.txt
筛选取值
grep
-i, --ignore-case
忽略大小写。例如,
grep -i "pattern" file会匹配 "Pattern", "PATTERN", 等-v, --invert-match
反转匹配,显示不匹配的行。例如,
grep -v "pattern" file会显示不包含 "pattern" 的行-c, --count
仅显示匹配的行数。例如,
grep -c "pattern" file会输出匹配 "pattern" 的行数-l, --files-with-matches
仅显示包含匹配的文件名。例如,
grep -l "pattern" *会显示所有包含 "pattern" 的文件名-L, --files-without-match
仅显示不包含匹配的文件名。例如,
grep -L "pattern" *会显示所有不包含 "pattern" 的文件名-n, --line-number
显示匹配的行号。例如,
grep -n "pattern" file会显示匹配行及其行号-H, --with-filename
显示匹配行所在的文件名(默认在多个文件时启用)。例如,
grep -H "pattern" file1 file2-h, --no-filename
在多文件搜索时不显示文件名。例如,
grep -h "pattern" file1 file2-r, --recursive
递归搜索目录及其子目录中的文件。例如,
grep -r "pattern" /path/to/directory-R, --dereference-recursive
递归搜索目录及其子目录中的文件,跟随符号链接。例如,
grep -R "pattern" /path/to/directory-w, --word-regexp
仅匹配整个单词。例如,
grep -w "pattern" file只会匹配独立的 "pattern",而不会匹配 "patterned" 或 "spatterns"-x, --line-regexp
仅匹配整个行。例如,
grep -x "pattern" file只会匹配完全等于 "pattern" 的行-A NUM, --after-context=NUM
显示匹配行以及之后的 NUM 行。例如,
grep -A 3 "pattern" file会显示匹配行及其后 3 行-B NUM, --before-context=NUM
显示匹配行以及之前的 NUM 行。例如,
grep -B 3 "pattern" file会显示匹配行及其前 3 行-C NUM, --context=NUM
显示匹配行以及前后各 NUM 行。例如,
grep -C 3 "pattern" file会显示匹配行及其前后各 3 行-o, --only-matching
仅显示匹配部分。例如,
grep -o "pattern" file只会显示匹配到的 "pattern" 部分,而不是整行-q, --quiet, --silent
安静模式,不输出任何内容,只返回状态码。例如,
grep -q "pattern" file用于脚本中检查是否有匹配-E, --extended-regexp
使用扩展正则表达式。例如,
grep -E "pattern1|pattern2" file可以匹配 "pattern1" 或 "pattern2"-F, --fixed-strings
使用固定字符串(而不是正则表达式)进行匹配。例如,
grep -F "pattern" file会将 "pattern" 视为固定字符串-P, --perl-regexp
使用 Perl 兼容正则表达式。例如,
grep -P "\bpattern\b" file使用 Perl 风格的正则表达式语法--exclude=GLOB
排除匹配的文件,例如,
grep --exclude=*.log "pattern" *排除所有.log文件--include=GLOB
仅包含匹配的文件,例如,
grep --include=*.txt "pattern" *仅搜索.txt文件--exclude-dir=DIR
排除匹配的目录,例如,
grep --exclude-dir=logs "pattern" *排除logs目录
用例
grep -r --include=*.sh "data"
grep -rl --include=*.sh "data"
grep -q "data" 1.sh #匹配到的情况下状态码为0
grep -q "123456" 1.sh ##匹配不到的情况下状态码为1
查找替换
sed
-e script
指定要执行的
sed脚本-i[SUFFIX], --in-place[=SUFFIX]
直接编辑文件内容(即修改原文件),可选的
SUFFIX参数用于备份文件-n, --quiet, --silent
取消默认输出,仅显示脚本处理结果
s/pattern/replacement/flags
查找并替换。例如,
s/old/new/g将所有old替换为newd
删除匹配的行
p
打印匹配的行
a\text
在当前行后追加文本
i\text
在当前行前插入文本
c\text
用文本替换当前行
用例
示例文件file.txt
apple
banana
carrot
date
elderberry
fig
grapesed '/apple/s/^/#/' file.txt #在匹配内容的行首添加# 
sed 's/e/E/g' file.txt
sed '2s/banana/mango/' file.txt #仅将第二行的 banana 替换为 mango 
sed '/carrot/d' file.txt #删除包含 carrot 的行
sed '2a\cherry' file.txt #在第二行后插入 cherry 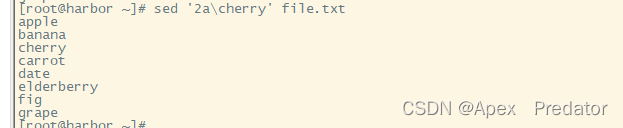
sed -e 's/apple/kiwi/' -e '/fig/d' file.txt #将 apple 替换为 kiwi,然后删除包含 fig 的行 
查网络连接信息
ss
-a, --all
显示所有连接,包括监听和非监听连接
-t, --tcp
仅显示 TCP 连接
-u, --udp
仅显示 UDP 连接
-l, --listening
显示监听的套接字
-p, --processes
显示使用套接字的进程
-n, --numeric
以数字形式显示端口和地址(不进行名称解析)
-r, --resolve
尝试解析网络地址
-s, --summary
显示简要摘要信息
-i, --info
显示详细的 TCP 连接信息
-m, --memory
显示套接字使用的内存信息
列出当前系统中打开的文件
lsof
-c [command]
列出由特定命令打开的文件
-u [username]
列出特定用户打开的文件
-p [pid]
列出特定进程 ID 打开的文件
-d [file descriptor]
列出使用特定文件描述符的文件
-i [protocol]
列出符合条件的网络连接。例如,
-i TCP或-i UDP-n
不进行 DNS 解析,以数字格式显示地址
-t
仅列出进程 ID(简洁模式)
lsof -u username #列出由特定用户打开的文件
lsof -p pid #列出特定进程 ID 打开的文件
lsof -c command #列出特定命令打开的文件
lsof -i :port #列出使用特定端口的网络连接
lsof -i UDP #列出所有 UDP 网络连接
lsof -i @IP #列出与特定 IP 地址相关的网络连接
查找并显示给定命令的可执行文件路径
which
which nginx
显示当前系统中运行的进程信息
ps
a:显示所有与终端相关的进程,包括其他用户的进程。
u:以用户为中心显示进程信息,包括用户名和启动时间。
x:显示没有控制终端的进程。
e:显示所有进程。
f:显示进程的完整格式,包括父进程信息。
l:显示长格式的进程信息。
m:带线程的查询
o:自定义输出格式。
p [pid]:显示特定进程 ID 的信息。
-C [command]:显示特定命令的进程信息。
-U [user]:显示特定用户的进程信息
ps -aux #查询所有进程并包含用户信息
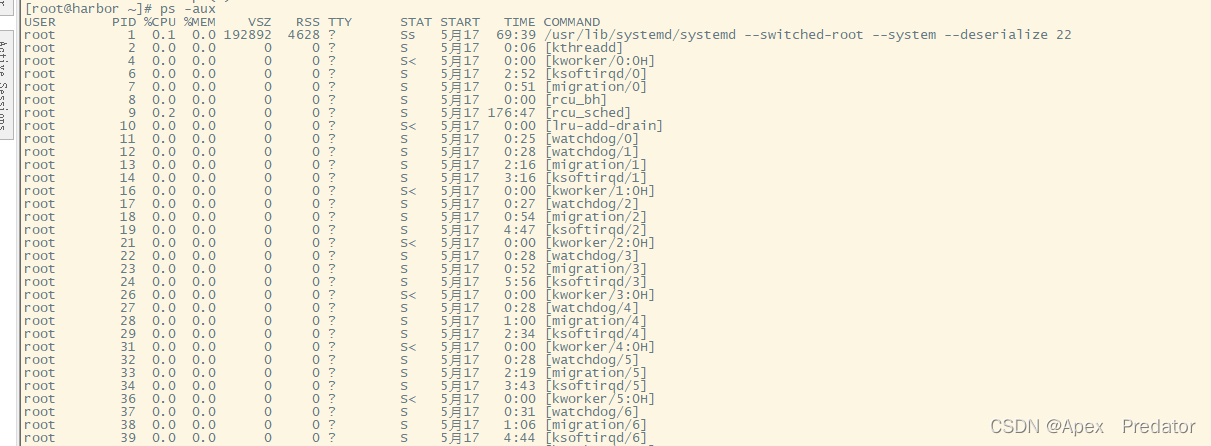
ps -ef # 显示所有进程的完整格式信息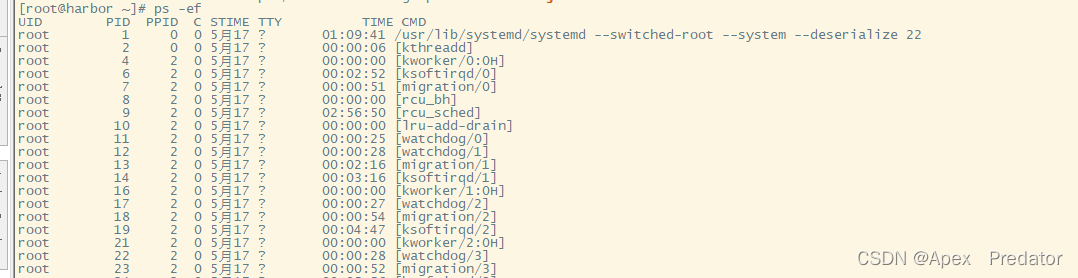
ps -eo pid,ppid,cmd,%mem,%cpu #自定义输出格式 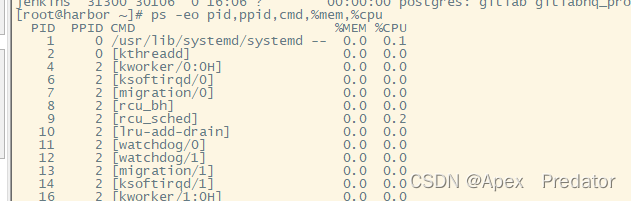
ps -mp 1603 -o tid,%cpu #结合自定义查询,查询某程序下的所有线程 
显示已加载的内核模块
lsmod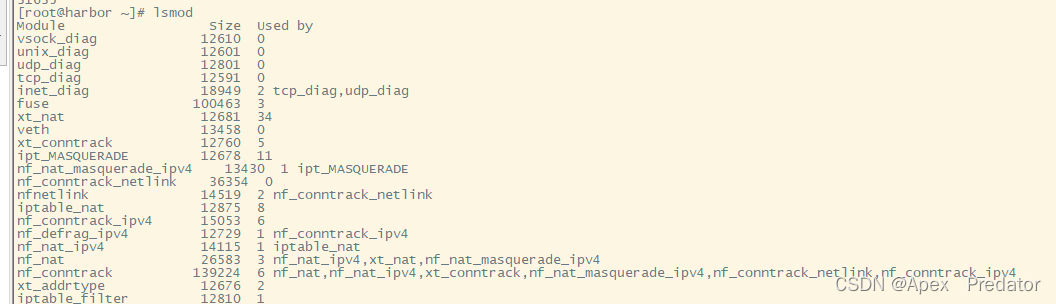
控制输出格式
printf
%s 将参数输出为字符串
%f 将参数输出为浮点数
%o 将参数输出为八进制
%d 将参数输出为十进制
%x 将参数输出为十六进制
用例
printf "教师:%s\n年龄:%x\n性别:%s\n" "linlin" "16" "boy"
#编写匹配语句,每个符号代表匹配一个值,其余的字符串,换行符可以随意添加
















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









