







淘宝详情数据采集涉及多个环节,包括商品上货、数据分析、属性详情以及价格监控等。在采集这些数据时,尤其是面对海量数据时,需要采取有效的方法和技术来确保数据的准确性和完整性。以下是一些关于淘宝详情数据采集的建议:
请求示例,API接口接入Anzexi58
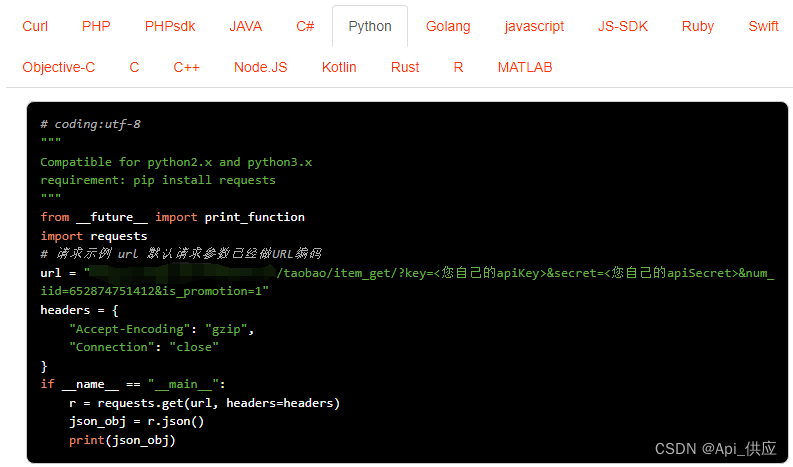
- 商品上货数据采集:
- 手动采集:通过打开淘宝商品页面,手动复制粘贴商品信息。这种方法虽然可行,但效率低下,容易出错,适合小规模采集任务。
- 自动采集:利用网络爬虫技术,编写爬虫程序模拟浏览器行为、解析HTML代码以获取商品信息。这种方法效率高,但需要注意淘宝对详情页数据采集的限制,避免过于频繁的采集导致IP被封禁。
- 数据分析:
- 数据清洗:对于采集到的原始数据,需要进行清洗和处理,去除重复、无效或错误的数据,确保数据质量。
- 数据可视化:利用图表、报表等形式将数据可视化,便于分析商品销售趋势、用户行为等。
- 属性详情采集:
- 属性提取:从商品详情页中提取商品属性,如品
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









