







写在前面:教程参考自HOW2J.CN,感谢站主的辛苦付出。
异常处理
定义:导致程序的正常流程被中断的事件,叫做异常
处理方法
try catch finally throws
1.将可能抛出FileNotFoundException 文件不存在异常的代码放在try里
2.如果文件存在,就会顺序往下执行,并且不执行catch块中的代码
3. 如果文件不存在,try 里的代码会立即终止,程序流程会运行到对应的catch块中
4. e.printStackTrace(); 会打印出方法的调用痕迹,如此例,会打印出异常开始于TestException的第16行,这样就便于定位和分析到底哪里出了异常
使用异常的父类进行catch
FileNotFoundException是Exception的子类,使用Exception也可以catch住FileNotFoundException
finally
无论是否出现异常,finally中的代码都会被执行
throws

throw和throws
throws与throw这两个关键字接近,不过意义不一样,有如下区别:
1. throws 出现在方法声明上,而throw通常都出现在方法体内。
2. throws 表示出现异常的一种可能性,并不一定会发生这些异常;throw则是抛出了异常,执行throw则一定抛出了某个异常对象。
1、throw 在方法体内使用;throws 在方法声明上使用,需要由方法的调用者进行异常处理;
2、throw 后面接的是异常对象,只能接一个。throws 后面接的是异常类型,可以接多个,多个异常类型用逗号隔开;
3、throw 是在方法中出现不正确情况时,手动来抛出异常,结束方法的,执行了 throw 语句一定会出现异常。而 throws 是用来声明当前方法有可能会出现某种异常的,如果出现了相应的异常,将由调用者来处理,声明了异常不一定会出现异常。
多异常捕捉方法
1. 分别进行catch

2. 把多个异常放在同一个catch内统一捕捉

异常中的return
练习:假设有一个方法 public int method(), 会返回一个整数
在这个方法中有try catch 和 finally.
try 里返回 1
catch 里 返回 2
finally 里 返回3
那么,这个方法到底返回多少?
返回3。结论:哪怕在try和catch中有return依然会执行finally中的代码 若finally有返回值,那么将会覆盖try或是catch中返回的代码
异常分类
可查异常、运行时异常、错误(后两个称为非可查异常)
- 可查异常 CheckedException:必须处理的异常,比如FileNotFoundException,不处理编译无法通过
- 运行时异常 RuntimeException:不是必须try catch的异常,比如:除数不能为0异常:ArithmeticException 下标越界异常:ArrayIndexOutOfBoundsException 空指针异常:NullPointerException
- 错误 Error:系统级别的异常,通常是内存耗尽,不要求强制捕捉

常见面试问题:运行时异常与非运行时异常的区别
运行时异常表示虚拟机的通常操作中可能遇到的异常,是一种常见运行错误。java编译器要求方法必须声明抛出可能发生的非运行时异常,但是并不要求必须声明抛出未被捕获的运行时异常。
运行时异常的特点是Java编译器不会检查它,也就是说,当程序中可能出现这类异常,即使没有用try-catch语句捕获它,也没有用throws子句声明抛出它,也会编译通过。 非运行时异常 (编译异常): 是RuntimeException以外的异常,类型上都属于Exception类及其子类。从程序语法角度讲是必须进行处理的异常,如果不处理,程序就不能编译通过。如IOException、SQLException等以及用户自定义的Exception异常,一般情况下不自定义检查异常。
Throwable类
异常分为Error和Exception,Error和Exception都继承了Throwable类。因此在捕捉异常时,也可以通过Throwable来捕捉,也可以抛出这个类。
自定义异常
创建自定义异常
一个英雄攻击另一个英雄的时候,如果发现另一个英雄已经挂了,就会抛出EnemyHeroIsDeadException
创建一个类EnemyHeroIsDeadException,并继承Exception
提供两个构造方法
- 无参的构造方法
- 带参的构造方法,并调用父类的对应的构造方法

抛出自定义异常
在Hero的attack方法中,当发现敌方英雄的血量为0的时候,抛出该异常
- 创建一个EnemyHeroIsDeadException实例
- 通过throw 抛出该异常
- 当前方法通过 throws 抛出该异常
在外部调用attack方法的时候,就需要进行捕捉,并且捕捉的时候,可以通过e.getMessage() 获取当时出错的具体原因。
三个重要的方法:

package charactor;
public class Hero {
public String name;
protected float hp;
public void attackHero(Hero h) throws EnemyHeroIsDeadException{
if(h.hp == 0){
throw new EnemyHeroIsDeadException(h.name + " 已经挂了,不需要施放技能" );
}
}
public String toString(){
return name;
}
class EnemyHeroIsDeadException extends Exception{
public EnemyHeroIsDeadException(){
}
public EnemyHeroIsDeadException(String msg){
super(msg);
}
}
public static void main(String[] args) {
Hero garen = new Hero();
garen.name = "盖伦";
garen.hp = 616;
Hero teemo = new Hero();
teemo.name = "提莫";
teemo.hp = 0;
try {
garen.attackHero(teemo);
} catch (EnemyHeroIsDeadException e) {
// TODO Auto-generated catch block
System.out.println("异常的具体原因:"+e.getMessage());
e.printStackTrace();
}
}
}I/O
文件的常用方法
package file;
import java.io.File;
import java.util.Date;
public class TestFile {
public static void main(String[] args) {
File f = new File("d:/LOLFolder/LOL.exe");
System.out.println("当前文件是:" +f);
//文件是否存在
System.out.println("判断是否存在:"+f.exists());
//是否是文件夹
System.out.println("判断是否是文件夹:"+f.isDirectory());
//是否是文件(非文件夹)
System.out.println("判断是否是文件:"+f.isFile());
//文件长度
System.out.println("获取文件的长度:"+f.length());
//文件最后修改时间
long time = f.lastModified();
Date d = new Date(time);
System.out.println("获取文件的最后修改时间:"+d);
//设置文件修改时间为1970.1.1 08:00:00
f.setLastModified(0);
//文件重命名
File f2 =new File("d:/LOLFolder/DOTA.exe");
f.renameTo(f2);
System.out.println("把LOL.exe改名成了DOTA.exe");
System.out.println("注意: 需要在D:\\LOLFolder确实存在一个LOL.exe,\r\n才可以看到对应的文件长度、修改时间等信息");
}
}package file;
import java.io.File;
import java.io.IOException;
public class TestFile {
public static void main(String[] args) throws IOException {
File f = new File("d:/LOLFolder/skin/garen.ski");
// 以字符串数组的形式,返回当前文件夹下的所有文件(不包含子文件及子文件夹)
f.list();
// 以文件数组的形式,返回当前文件夹下的所有文件(不包含子文件及子文件夹)
File[]fs= f.listFiles();
// 以字符串形式返回获取所在文件夹
f.getParent();
// 以文件形式返回获取所在文件夹
f.getParentFile();
// 创建文件夹,如果父文件夹skin不存在,创建就无效
f.mkdir();
// 创建文件夹,如果父文件夹skin不存在,就会创建父文件夹
f.mkdirs();
// 创建一个空文件,如果父文件夹skin不存在,就会抛出异常
f.createNewFile();
// 所以创建一个空文件之前,通常都会创建父目录
f.getParentFile().mkdirs();
// 列出所有的盘符c: d: e: 等等
f.listRoots();
// 刪除文件
f.delete();
// JVM结束的时候,刪除文件,常用于临时文件的删除
f.deleteOnExit();
}
}流 Stream
流就是一系列的数据,当不同的介质之间有数据交互的时候,JAVA就使用流来实现。数据源可以是文件,还可以是数据库,网络甚至是其他的程序。
文件流
package stream;
import java.io.File;
import java.io.FileInputStream;
import java.io.IOException;
public class TestStream {
public static void main(String[] args) {
try {
File f = new File("d:/lol.txt");
// 创建基于文件的输入流
FileInputStream fis = new FileInputStream(f);
// 通过这个输入流,就可以把数据从硬盘,读取到Java的虚拟机中来,也就是读取到内存中
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
}字节流
InputStream是字节输入流,同时也是抽象类,只提供方法声明,不提供方法的具体实现。
FileInputStream 是InputStream子类,以FileInputStream 为例进行文件读取。
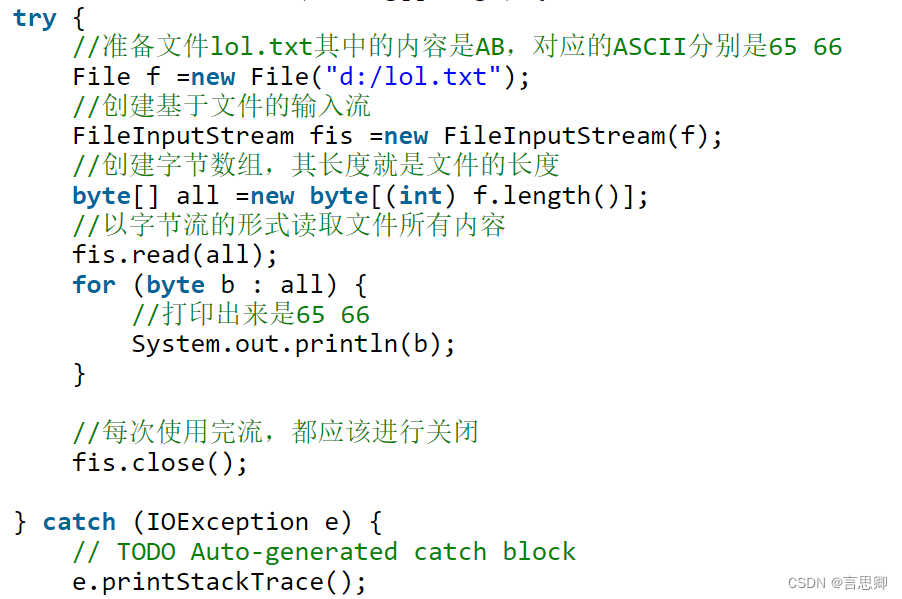
FileOutputStream 是OutputStream子类,以FileOutputStream 为例向文件写出数据。

flush():(30条消息) JAVA中的flush()方法_呼卓宇的博客-CSDN博客_flush()
关闭流
在try的作用域关闭
在try的作用域里关闭文件输入流,在前面的示例中都是使用这种方式,这样做有一个弊端:如果文件不存在,或者读取的时候出现问题而抛出异常,那么就不会执行这一行关闭流的代码,存在巨大的资源占用隐患。 不推荐使用。
在finally中关闭
这是标准的关闭流的方式
- 首先把流的引用声明在try的外面,如果声明在try里面,其作用域无法抵达finally.
- 在finally关闭之前,要先判断该引用是否为空
- 关闭的时候,需要再一次进行try catch处理
这是标准的严谨的关闭流的方式,但是看上去很繁琐,所以写不重要的或者测试代码的时候,都会采用上面的有隐患try的方式,因为不麻烦。
package stream;
import java.io.File;
import java.io.FileInputStream;
import java.io.IOException;
public class TestStream {
public static void main(String[] args) {
File f = new File("d:/lol.txt");
FileInputStream fis = null;
try {
fis = new FileInputStream(f);
byte[] all = new byte[(int) f.length()];
fis.read(all);
for (byte b : all) {
System.out.println(b);
}
} catch (IOException e) {
e.printStackTrace();
} finally {
// 在finally 里关闭流
if (null != fis)
try {
fis.close();
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
}
}使用try()的方式
把流定义在try()里,try,catch或者finally结束的时候,会自动关闭
这种编写代码的方式叫做 try-with-resources, 这是从JDK7开始支持的技术
所有的流,都实现了一个接口叫做 AutoCloseable,任何类实现了这个接口,都可以在try()中进行实例化。 并且在try, catch, finally结束的时候自动关闭,回收相关资源。
public class TestStream {
public static void main(String[] args) {
File f = new File("d:/lol.txt");
//把流定义在try()里,try,catch或者finally结束的时候,会自动关闭
try (FileInputStream fis = new FileInputStream(f)) {
byte[] all = new byte[(int) f.length()];
fis.read(all);
for (byte b : all) {
System.out.println(b);
}
} catch (IOException e) {
e.printStackTrace();
}
}
}字符流
读取文件

写入文件
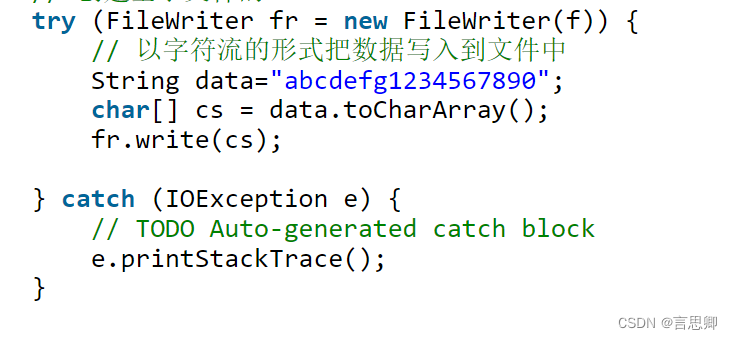
Java中文编码
计算机存放数据只能存放数字,所有的字符都会被转换为不同的数字。
工作中常见的编码方式
- SO-8859-1 ASCII 数字和西欧字母
- GBK GB2312 BIG5 中文
- UNICODE (统一码,万国码)
其中
- ISO-8859-1 包含 ASCII
- GB2312 是简体中文,BIG5是繁体中文,GBK同时包含简体和繁体以及日文。
- UNICODE 包括了所有的文字,无论中文,英文,藏文,法文,世界所有的文字都包含其中
如果所有都用UNICODE方式来存储数据的话,会造成很大的浪费。在这种情况下,就出现了UNICODE的各种减肥子编码, 比如UTF-8对数字和字母就使用一个字节,而对汉字就使用3个字节,从而达到了减肥还能保证健康的效果。UTF-8,UTF-16和UTF-32 针对不同类型的数据有不同的减肥效果,一般说来UTF-8是比较常用的方式。Java中采用的是UNICODE编码。
文件的编码方式——记事本
用记事本打开任意文本文件,并且另存为,就能够在编码这里看到一个下拉。
- ANSI 这个不是ASCII的意思,而是采用本地编码的意思。如果你是中文的操作系统,就会使GBK,如果是英文的就会是ISO-8859-1
- Unicode UNICODE原生的编码方式
- Unicode big endian 另一个 UNICODE编码方式
- UTF-8 最常见的UTF-8编码方式,数字和字母用一个字节, 汉字用3个字节。
用FileInputStream字节流正确读取中文
- 首先要知道文本是用什么方式编码的
- 使用字节流读取了文本后,再使用对应的编码方式去识别这些数字,得到正确的字符

用FileReader字符流正确读取中文
FileReader得到的是字符,所以一定是已经把字节根据某种编码识别成了字符了。而FileReader使用的编码方式是Charset.defaultCharset()的返回值,如果是中文的操作系统,就是GBK
FileReader是不能手动设置编码方式的,为了使用其他的编码方式,只能使用InputStreamReader来代替,像这样:
new InputStreamReader(new FileInputStream(f),Charset.forName("UTF-8")); Java缓存流
当读写介质是硬盘时,字节流和字符流存在弊端:每一次读写都会访问硬盘而导致性能不佳。
缓存流在读取的时候,会一次性读较多的数据到缓存中,以后每一次的读取,都是在缓存中访问,直到缓存中的数据读取完毕,再到硬盘中读取。
缓存流在写入数据的时候,会先把数据写入到缓存区,直到缓存区达到一定的量,才把这些数据,一起写入到硬盘中去。按照这种操作模式,就不会像字节流,字符流那样每写一个字节都访问硬盘,从而减少了IO操作。
缓存流必须建立在一个流的基础上
FileReader fr = new FileReader(f);
BufferedReader br = new BufferedReader(fr);缓存字符输入流 BufferedReader 可以一次读取一行数据
while (true) {
// 一次读一行
String line = br.readLine();
if (null == line)
break;
System.out.println(line);
}PrintWriter 缓存字符输出流, 可以一次写出一行数据
借助flush可以不等缓存区满,立即写入硬盘。
public class TestStream {
public static void main(String[] args) {
//向文件lol2.txt中写入三行语句
File f =new File("d:/lol2.txt");
//创建文件字符流
//缓存流必须建立在一个存在的流的基础上
try(FileWriter fr = new FileWriter(f);PrintWriter pw = new PrintWriter(fr);) {
pw.println("garen kill teemo");
//强制把缓存中的数据写入硬盘,无论缓存是否已满
pw.flush();
pw.println("teemo revive after 1 minutes");
pw.flush();
pw.println("teemo try to garen, but killed again");
pw.flush();
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
}数据流
- DataInputStream 数据输入流
- DataOutputStream 数据输出流
使用数据流的 writeUTF() 和 readUTF() 可以进行数据的格式化顺序读写。
注: 要用DataInputStream 读取一个文件,这个文件必须是由DataOutputStream 写出的,否则会出现EOFException,因为DataOutputStream 在写出的时候会做一些特殊标记,只有DataInputStream 才能成功的读取。
对象流
对象流指的是可以直接把一个对象以流的形式传输给其他的介质,比如硬盘。一个对象以流的形式进行传输,叫做序列化。 该对象所对应的类,必须是实现Serializable接口。
public class TestStream {
public static void main(String[] args) {
//创建一个Hero garen
//要把Hero对象直接保存在文件上,务必让Hero类实现Serializable接口
Hero h = new Hero();
h.name = "garen";
h.hp = 616;
//准备一个文件用于保存该对象
File f =new File("d:/garen.lol");
try(
//创建对象输出流
FileOutputStream fos = new FileOutputStream(f);
ObjectOutputStream oos =new ObjectOutputStream(fos);
//创建对象输入流
FileInputStream fis = new FileInputStream(f);
ObjectInputStream ois =new ObjectInputStream(fis);
) {
oos.writeObject(h);
Hero h2 = (Hero) ois.readObject();
System.out.println(h2.name);
System.out.println(h2.hp);
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (ClassNotFoundException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
}public class Hero implements Serializable {
//表示这个类当前的版本,如果有了变化,比如新设计了属性,就应该修改这个版本号
private static final long serialVersionUID = 1L;
public String name;
public float hp;
}System.in和Scanner
System.out 是常用的在控制台输出数据的
System.in 可以从控制台输入数据
package stream;
import java.io.IOException;
import java.io.InputStream;
public class TestStream {
public static void main(String[] args) {
// 控制台输入
try (InputStream is = System.in;) {
while (true) {
int i = is.read();
System.out.println(i);
}
} catch (IOException e) {
e.printStackTrace();
}
}
}使用Scanner可以按逐行读取
Scanner s = new Scanner(System.in);
while(true){
String line = s.nextLine();
System.out.println(line);
}集合框架
集合框架:ArrayList
为了解决数组的局限性,引入容器类的概念。 最常见的容器类是ArrayList。常用方法如下:

toArray可以把一个ArrayList对象转换为数组。需要注意的是,如果要转换为一个Hero数组,那么需要传递一个Hero数组类型的对象给toArray(),这样toArray方法才知道,你希望转换为哪种类型的数组,否则只能转换为Object数组。例如:
Hero hs[] = (Hero[])heros.toArray(new Hero[]{});ArrayList实现了List接口,而且一般常用写法是将ArrayList的引用声明为接口List类型:
List heros = new ArrayList();
heros.add( new Hero("盖伦"));泛型 Generic
不指定泛型的容器,可以存放任何类型的元素
指定了泛型的容器,只能存放指定类型的元素以及其子类

泛型的简写

遍历
- for循环遍历,结合size()和get()
- 迭代器遍历
- for: 增强for循环遍历
//迭代器while写法
Iterator<Hero> it= heros.iterator();
//从最开始的位置判断"下一个"位置是否有数据
//如果有就通过next取出来,并且把指针向下移动
//直到"下一个"位置没有数据
while(it.hasNext()){
Hero h = it.next();
System.out.println(h);
}
//迭代器的for写法
System.out.println("--------使用for的iterator-------");
for (Iterator<Hero> iterator = heros.iterator(); iterator.hasNext();) {
Hero hero = (Hero) iterator.next();
System.out.println(hero);
}集合框架:LinkedList
FIFO FILO
先进先出序列:FIFO(Java中叫做Queue队列),先进后出序列FILO(Java中叫做Stack栈)
实现List接口
LinkedList和ArrayList一样,也实现了List接口,诸如add,remove等方法。
实现Deque
LinkedList实现了双向链表Deque:
方法:addFirst() addLast() getFirst() getLast() removeFirst() removeLast()
实现Queue
LinkedList实现了队列Queue:
offer():在最后添加元素 poll():取出第一个元素 peek():查看第一个元素
面试常问点:Arraylist和LinkedList的区别
tip:可以通过LinkedList手动实现Stack栈 ~
集合框架:二叉树
二叉树排序-插入数据
package collection;
public class Node {
// 左子节点
public Node leftNode;
// 右子节点
public Node rightNode;
// 值
public Object value;
// 插入 数据
public void add(Object v) {
// 如果当前节点没有值,就把数据放在当前节点上
if (null == value)
value = v;
// 如果当前节点有值,就进行判断,新增的值与当前值的大小关系
else {
// 新增的值,比当前值小或者相同
if ((Integer) v -((Integer)value) <= 0) {
if (null == leftNode)
leftNode = new Node();
leftNode.add(v);
}
// 新增的值,比当前值大
else {
if (null == rightNode)
rightNode = new Node();
rightNode.add(v);
}
}
}
public static void main(String[] args) {
int randoms[] = new int[] { 67, 7, 30, 73, 10, 0, 78, 81, 10, 74 };
Node roots = new Node();
for (int number : randoms) {
roots.add(number);
}
}
}二叉树排序-遍历(前序、中序、后序)
// 中序遍历所有的节点
public List<Object> values() {
List<Object> values = new ArrayList<>();
// 左节点的遍历结果
if (null != leftNode)
values.addAll(leftNode.values());
// 当前节点
values.add(value);
// 右节点的遍历结果
if (null != rightNode)
values.addAll(rightNode.values());
return values;
}集合框架:HashMap
通过键值对的方式存储数据,键不能重复,值可以重复。当get一个不存在key时,返回null。
import java.util.HashMap;
public class TestCollection {
public static void main(String[] args) {
HashMap<String,String> dictionary = new HashMap<>();
dictionary.put("adc", "物理英雄");
dictionary.put("apc", "魔法英雄");
dictionary.put("t", "坦克");
System.out.println(dictionary.get("t"));
}
}集合框架:HashSet
- set中的元素不能重复,add时容器中只会保留一个
- set中的元素没有顺序
- set不提供get()来获取指定位置的元素,只能用迭代器或者增强型for循环来遍历
for (Iterator<Integer> iterator = numbers.iterator(); iterator.hasNext();) {
Integer i = (Integer) iterator.next();
System.out.println(i);
}HashMap和HashSet的关系
HashSet原本没有独立的实现,而是在里面封装了一个Map,HashSet时作为Map的key而存在的。

Collections工具类
Collections是一个类,容器的工具类,就如同Arrays是数组的工具类。

ArrayList和LinkedList的区别
- ArrayList 插入,删除数据慢。LinkedList, 插入,删除数据快
- ArrayList是顺序结构,所以定位很快,一下就找到位置了。
- LinkedList 是链表结构,必须得一个一个的数过去,所以定位慢。
HashMap和HashTable的区别
- HashMap和Hashtable都实现了Map接口,都是键值对保存数据的方式
- 区别1:HashMap可以存放 null;Hashtable不能存放null
- 区别2:HashMap不是线程安全的类;Hashtable是线程安全的类
keySet()可以获取所有的key, values()可以获取所有的value。
HashSet LinkedHashSet TreeSet
HashSet 插入元素无序
LinkedHashSet 按照插入顺序
TreeSet 从小到大排序
练习:利用LinkedHashSet的既不重复,又有顺序的特性,把Math.PI中的数字,按照出现顺序打印出来,相同数字,只出现一次。
Set<Integer> lh=new LinkedHashSet<>();
String s=String.valueOf(Math.PI);
s= s.replace(".","");
char [] cs=s.toCharArray();
for(char cc:cs){
int num=Integer.parseInt(String.valueOf(cc));
lh.add(num);
}
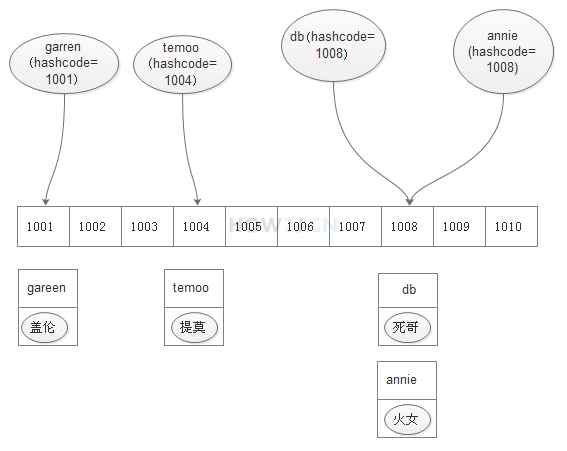
System.out.println(lh);hashcode原理
空间换时间的思维方式:HashMap查找性能卓越的原因。所有的对象都有一个对应的hashcode。
比较器
当调用Collections.sort()对集合中的对象比大小时,需要提供一个比较器来指明按照对象的什么属性进行比较。
Comparator
//引入Comparator,指定比较的算法
Comparator<Hero> c = new Comparator<Hero>() {
@Override
public int compare(Hero h1, Hero h2) {
//按照hp进行排序
if(h1.hp>=h2.hp)
return 1; //正数表示h1比h2要大
else
return -1;
}
};
Collections.sort(heros,c);Comparable
package charactor;
public class Hero implements Comparable<Hero>{
public String name;
public float hp;
@Override
public int compareTo(Hero anotherHero) {
if(damage<anotherHero.damage)
return 1;
else
return -1;
}
}
练习:实现自定义排序的treeSet(treeSet的构造方法支持传入一个comapator比较器)
Comparator<Integer> c=new Comparator<Integer>() {
@Override
public int compare(Integer o1, Integer o2) {
return o2-o1;
}
};
Set<Integer> treeset=new TreeSet<>(c);
for(int i=0;i<10;i++){
treeset.add(i);
}
System.out.println(treeset);














 145
145











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









