







场景:我有一大堆url,而且每个url都是一个图片的请求地址,比如,谷歌的18级别的郑州地图切片的资源请求地址如下
http://www.google.cn/maps/vt?lyrs=s@781&gl=cn&&x=214237&y=104408&z=18
http://www.google.cn/maps/vt?lyrs=s@781&gl=cn&&x=214237&y=104407&z=18
http://www.google.cn/maps/vt?lyrs=s@781&gl=cn&&x=214237&y=104406&z=18
http://www.google.cn/maps/vt?lyrs=s@781&gl=cn&&x=214236&y=104406&z=18
如果地址打不开,说明Google的切片服务器换了,哈哈
至于,地址是哪来的,两种方式,第一种就是去谷歌地图打开F12(开发者模式)查看所有ALL请求,第二种就是,根据范围求切片在某一z级别下的的x + y(本篇讲多线程任务的执行,这个可以忽略掉)
以上只是一个场景,当然也有可能是其他的场景,比如,你要爬某个图库网站上的图片,你是不是要想办法拿到资源的url,拿到url,当然就是下载了,怎么下载呢?
1.拿到一个url,下载一个 -- 单线程模式
2.一次性拿到所有的url,放入容器中先存下来(容器可以是Java集合类型,也可以是某一类型的数据库,比如redis或者mongodb),然后循环从容器中读取url进行下载 -- 依然单线程模式
3.同上,不同的是,最后不是循环取出依次进行url处理,而是开N个线程,共享容器中的资源,进行阻塞式的并发url处理 -- 多线程
4.边存储url边下载url,也就是一个线程负责生产url,N个线程负责消费url -- 多线程
分析:首先第一种方式和第二种方式都是单线程模式,如果下载的url不是很多的话,单线程完全足够了,如果要下载的url资源很庞大,下载下来的文件至少都是GB级别的,那么,单线程的模式势必会造成效率很低,这时候就要用多线程了。
再来看下第三种方式和第四种方式虽然都是多线程模式,但是,明显第四种方式更占优势,原因还是在于如果下载的url资源很庞大的话,第三种先存再处理的方式显然会让内存(假设存放url是在内存中操作的)非常吃不消,可能还没等到多线程执行那一步,生产者线程就已经把整个程序搞垮了(博主试过,上亿条资源先存后处理,16G的内存直接撑爆,无奈只好关机),所以,最好的方式就是边存边处理,构建url资源的时候,同时有N个消费者线程进行url的下载。
好了,不多说了,我们先来看一个url下载工具demo
UrlSpiderUtils.java
package com.appleyk.utils;
import java.io.ByteArrayOutputStream;
import java.io.File;
import java.io.FileOutputStream;
import java.io.IOException;
import java.io.InputStream;
import java.net.HttpURLConnection;
import java.net.URL;
public class UrlSpiderUtils {
/**
* 根据url获取输入流,并写入文件保存
*
* @param urlStr
* @param fileName
* @param savePath
* @throws IOException
*/
public static void downLoadFromUrl(String urlStr, String fileName, String savePath) {
try {
URL url = new URL(urlStr);
HttpURLConnection conn = (HttpURLConnection) url.openConnection();
// 设置超时间为3秒
conn.setConnectTimeout(3 * 1000);
// 防止屏蔽程序抓取而返回403错误
conn.setRequestProperty("User-Agent", "Mozilla/4.0 (compatible; MSIE 5.0; Windows NT; DigExt)");
// 得到输入流
InputStream inputStream = conn.getInputStream();
// 获取自己数组
byte[] getData = readInputStream(inputStream);
// 文件保存位置
File saveDir = new File(savePath);
if (!saveDir.exists()) {
saveDir.mkdirs();
}
File file = new File(saveDir + File.separator + fileName);
if (!file.exists()) {
file.createNewFile();
}
FileOutputStream fos = new FileOutputStream(file);
fos.write(getData);
if (fos != null) {
fos.close();
}
if (inputStream != null) {
inputStream.close();
}
System.out.println("info:" + url + "--download success");
} catch (Exception ex) {
}
}
/**
* 根据url获得输入流,不保存到文件,保存到数据库
*
* @param urlStr
* @return
* @throws Exception
* @throws IOException
*/
public static byte[] downLoadFromUrl(String urlStr) throws Exception, IOException {
URL url = new URL(urlStr);
HttpURLConnection conn = (HttpURLConnection) url.openConnection();
// 设置超时间为3秒
conn.setConnectTimeout(3 * 1000);
// 防止屏蔽程序抓取而返回403错误
conn.setRequestProperty("User-Agent", "Mozilla/4.0 (compatible; MSIE 5.0; Windows NT; DigExt)");
// 得到输入流
InputStream inputStream = conn.getInputStream();
// 获取自己数组
byte[] data = readInputStream(inputStream);
return data;
}
/**
* 从输入流中获取字节数组
*
* @param inputStream
* @return
* @throws IOException
*/
public static byte[] readInputStream(InputStream inputStream) throws IOException {
byte[] buffer = new byte[1024];
int len = 0;
ByteArrayOutputStream bos = new ByteArrayOutputStream();
while ((len = inputStream.read(buffer)) != -1) {
bos.write(buffer, 0, len);
}
bos.close();
return bos.toByteArray();
}
}本篇用不到上面那个工具,但是知道给一个url如何进行资源的下载,是一件很重要的前提工作
继续,我们有了url后,用什么来存放呢?
List<String>? Stack<String>? Queue<String>? 还是什么 HashMap 、 HashSet、HashTable啊(哈哈,扯远了)
存放url的容器必须是先进来的url先出去,因此我们想到了用队列(栈是先进后出),而且,这个队列还不能是普通的队列,因为我们要用到多线程,试想一下,如果普通的queue被多个线程共享,假设,队列空的时候,N个线程需要从队列里消费url,此时会怎么样? 如果队列满了,生产者(可以是单线程也可以是多线程)往里放url的时候,又会怎么样?
当然,上面的情况是有很大几率发生的,至于队列满了这个可能性不是太大,因为我们可以设置队列的容量为最大
于是我们在想,Java有没有一种队列,有这种功能
一、如果队列满了的话,生产者线程会等待,等待其他消费者线程先消费队列,随后,生产者线程检测到队列没有满,于是就又开始了生产(put)
二、如果队列空了的话,消费者线程会等待,等待其他生产者线程先生产队列,随后,消费者线程检测到队列不等于空,于是就有开始了消费(take)
还真有,就是 这个
BlockingQueue

关于什么是BlockingQueue,可以参考这篇博文:【Java并发之】BlockingQueue
好了,我们继续,我打算构建一个任务队列管理器,来统一管理url资源,如下
TaskQueueManager.java
package com.appleyk.store;
import java.util.concurrent.BlockingQueue;
import java.util.concurrent.LinkedBlockingQueue;
/**
* 单例模式 -- 任务队列管理器 -- 实例在多线程下启用同步块synchronized保护实例有效的被创建
*
* @author yukun24@126.com
* @blob http://blog.csdn.net/appleyk
* @date 2018年4月3日-上午10:49:24
*/
public class TaskQueueManager {
/**
* BlockingQueue -- 阻塞队列 -- 存放url字符串 队列的特点先进先出 -- 对应先进来的url,先进行下载处理
* 不指定容器大小,默认Integer.MAX_VALUE
*/
public static BlockingQueue<String> queue;
private TaskQueueManager() {
/**
* 由于LinkedBlockingQueue实现是线程安全的,实现了先进先出等特性,是作为生产者消费者的首选
* LinkedBlockingQueue 可以指定容量,也可以不指定,不指定的话,默认最大是Integer.MAX_VALUE
* 其中主要用到put和take方法 put方法在队列满的时候会阻塞直到有队列成员被消费
* take方法在队列空的时候会阻塞,直到有队列成员被放进来
*/
queue = new LinkedBlockingQueue<String>();
}
/**
* Java 语言提供了 volatile 和 synchronized 两个关键字来保证线程之间操作的有序性
*/
private static volatile TaskQueueManager instance;
public static TaskQueueManager getIstance() {
if (instance == null) {
synchronized (TaskQueueManager.class) {
if (instance == null) {
instance = new TaskQueueManager();
}
}
}
return instance;
}
/**
* put -- 模拟任务生产 -- (场景应用在单线程下,put进有效的url地址)
*
* @param url
* @throws InterruptedException
*/
public static void produce(String url) throws InterruptedException {
queue.put(url);
}
/**
* take -- 模拟任务消费 -- (场景应用在多线程下,take取出有效的url并进行后期处理)
*
* @return
* @throws InterruptedException
*/
public static String consume() throws InterruptedException {
return queue.take();
}
/**
* 获取队列的url数量 -- (如果这个值在10s内,等于0的话,将会终止所有任务 -- 生成线程 和 消费线程)
*
* @return
*/
public Integer size() {
return queue.size();
}
}说明都在注释上了,不懂的可以留言
有了url任务队列管理器,下面就是要配套线程了
穿插一张项目演示的目录结构树

我们先来看一下生产者线程的构建
Producer.java
package com.appleyk.runnable;
import com.appleyk.store.TaskQueueManager;
/**
* 生成者线程 -- 生成url
*
* @author yukun24@126.com
* @blob http://blog.csdn.net/appleyk
* @date 2018年4月3日-上午11:35:30
*/
public class Producer implements Runnable {
private String name;
private String url;
private TaskQueueManager taskQueueManager;
public Producer(String name, String url, TaskQueueManager taskQueueManager) {
this.name = name;
this.url = url;
this.taskQueueManager = taskQueueManager;
}
public Producer(String name, TaskQueueManager taskQueueManager) {
this.name = name;
this.taskQueueManager = taskQueueManager;
}
public void setUrl(String url) {
this.url = url;
}
public void run() {
try {
while (true) {
// 生产url
System.err.println("生产者[" + name + "]:生产url --" + url);
taskQueueManager.produce(url);
// 休眠300ms -- 观看效果
Thread.sleep(300);
}
} catch (InterruptedException ex) {
System.err.println("Producer Interrupted:" + ex.getMessage());
}
}
}
我们再来看一下消费者线程的构建
Consumer.java
package com.appleyk.runnable;
import com.appleyk.store.TaskQueueManager;
/**
* 消费者线程 -- 处理url
*
* @author yukun24@126.com
* @blob http://blog.csdn.net/appleyk
* @date 2018年4月3日-上午11:35:11
*/
public class Consumer implements Runnable {
private String name;
private TaskQueueManager taskQueueManager;
public Consumer(String name, TaskQueueManager taskQueueManager) {
this.name = name;
this.taskQueueManager = taskQueueManager;
}
public void run() {
try {
while (true) {
// 消费url
System.err.println("消费者[" + name + "]:消费url --" +taskQueueManager.consume()+"--剩余url容量:"+taskQueueManager.size());
// 休眠1000ms -- 假设生产的快,消费的慢
// Thread.sleep(100);
}
} catch (InterruptedException ex) {
System.err.println("Consumer Interrupted :" + ex.getMessage());
}
}
}
万事俱备,只欠东风,来来来,我们来演示一下上文提到过的第三种方式和第四种方式
先来,第三种方式:先存在处理
备注:main方法写在

main.java
public static void main(String[] args) throws Exception, InterruptedException {
/**
* 来一个任务队列管理器
*/
TaskQueueManager mamager = TaskQueueManager.getIstance();
/**
* 来一个Java的线程池 CachedThreadPool会创建一个缓存区,将初始化的线程缓存起来 如果线程有可用的,就使用之前创建好的线程
* 如果没有可用的,就新创建线程 终止并且从缓存中移除已有60秒未被使用的线程
*/
ExecutorService service = Executors.newCachedThreadPool();
/**
* 来一个生成者 --模拟url构建并放入队列管理器中,初始放入100个
*/
long start = System.currentTimeMillis();
for (int i = 0; i < 200; i++) {
mamager.produce("http://www.baidu.com" + Integer.valueOf(i));
}
/**
* 来10打消费者 -- 模拟从队列管理器中取出url并进行资源下载
*/
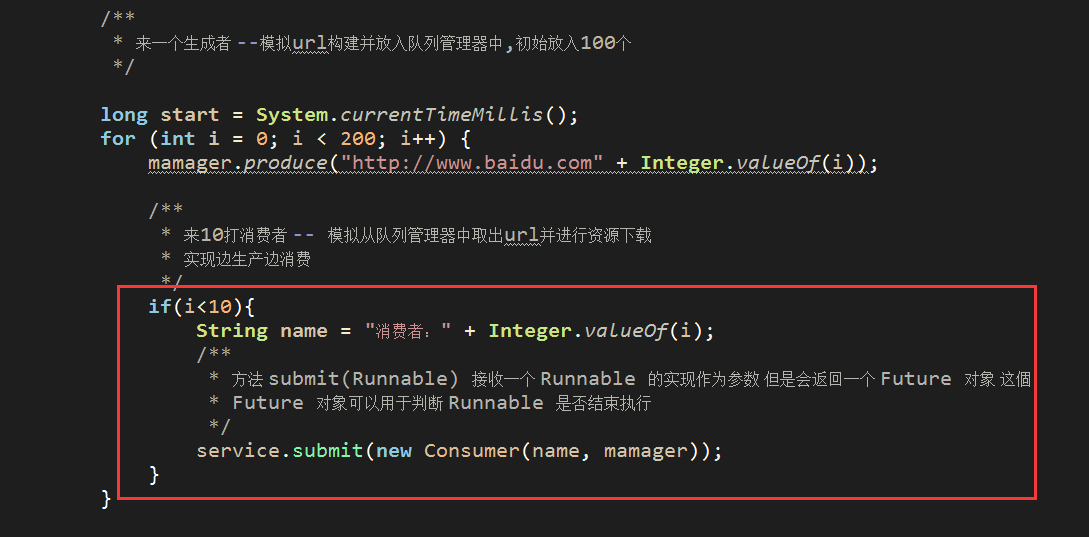
for (int i = 0; i < 10; i++) {
String name = "消费者:" + Integer.valueOf(i);
/**
* 方法 submit(Runnable) 接收一个 Runnable 的实现作为参数 但是会返回一个 Future 对象 这個
* Future 对象可以用于判断 Runnable 是否结束执行
*/
service.submit(new Consumer(name, mamager));
}
while (true) {
Thread.sleep(1000 * 10);
//主线程 每10秒检测一次,如果检测到任务队列里长时间没有内如put,就终止整个任务service
if (mamager.size() == 0) {
service.shutdown();
break;
}
}
long end = System.currentTimeMillis();
System.err.println("下载任务完成!耗时:"+(end-start)+"");
}
}
200个url,实验一把,走一波控制台输出(部分截图)
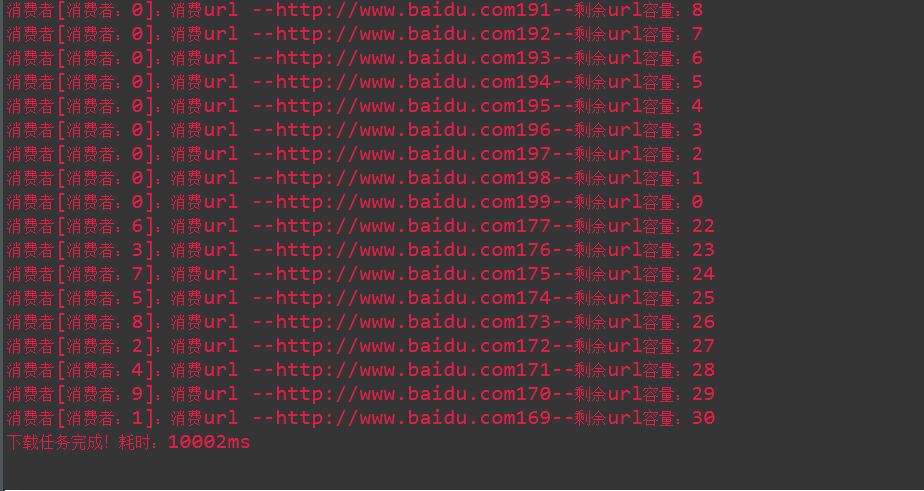
边生产边消费,只需要改一个地方就行
多生产者,多消费者模拟
public static void main(String[] args) throws Exception, InterruptedException {
/**
* 来一个任务队列管理器
*/
TaskQueueManager manager = TaskQueueManager.getIstance();
/**
* 来一个Java的线程池 CachedThreadPool会创建一个缓存区,将初始化的线程缓存起来 如果线程有可用的,就使用之前创建好的线程
* 如果没有可用的,就新创建线程 终止并且从缓存中移除已有60秒未被使用的线程
*/
ExecutorService service = Executors.newCachedThreadPool();
Producer producer1 = new Producer("生产者A","http://www.baidu.com1", manager);
Producer producer2 = new Producer("生产者B","http://www.baidu.com2", manager);
Consumer consumer1 = new Consumer("消费者1", manager);
Consumer consumer2 = new Consumer("消费者2", manager);
Consumer consumer3 = new Consumer("消费者3", manager);
Consumer consumer4 = new Consumer("消费者4", manager);
/**
* 来两个生成者 --模拟url构建并放入队列管理器中 -- 交替put
*/
service.submit(producer1);
service.submit(producer2);
/**
* 来四个消费者
*/
service.submit(consumer1);
service.submit(consumer2);
service.submit(consumer3);
service.submit(consumer4);
}效果(部分)
















 4179
4179











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









