













由此观之,基本上我知道的错误率就会很小。像基本的数据结构与算法。
但是不知道的错误率接近100%了,比如操作系统、数据库、Linux、设计模式的题。但是这些题其实也是很基础的,与考研题类似,甚至还没有达到考研题的难度。
但是现在主要是攻破C++语言和数据结构与算法的堡垒,其他类型的题目只能等后期“建设”了!因为其实操作系统、数据库、网络、设计模式等这些,都是比较板块化的,但是也是挺费时间的。还有就是我的策略倾向于各个击破!^_^
所以,对于这些题,先收集他们的考点,总结。
—————————————————————————————————————————————————————————————————————————————
操作系统:磁盘、进程、存储管理、Linux权限
数据库:索引、关系模型范式、
网络:IP段
数据结构与算法也要总结:
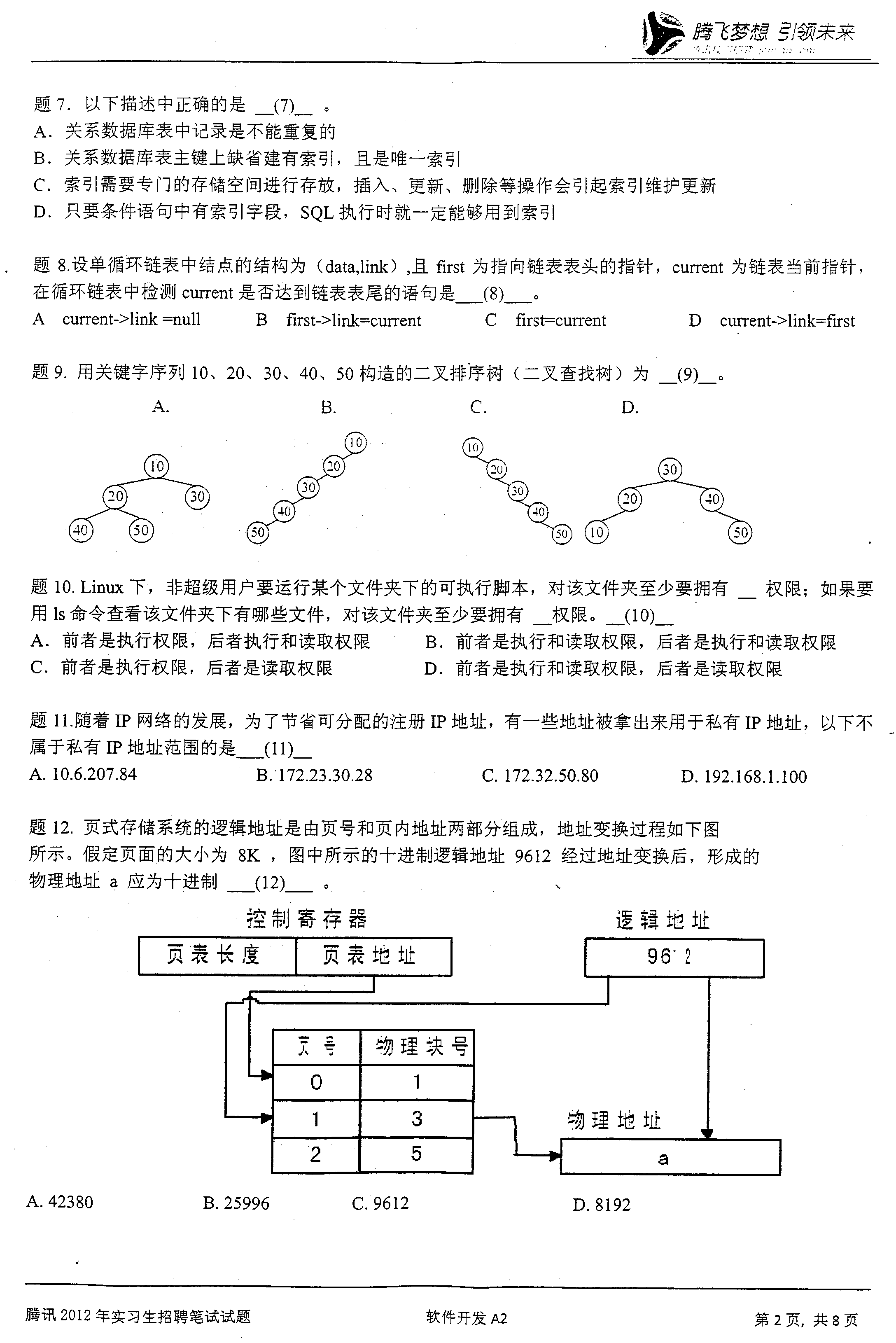
数组的循环队列,计算队列元素个数
构造哈弗曼树,求带权路径长度
单循环链表,判断是否到达表尾
二叉排序树建树
散列函数+用线性探测法解决冲突,求平均查找长度
特定场合的排序
求数组连续子序列之和最大
答案说明:
选择题2:
数据存储在磁盘上的排列方式会影响I/O服务的总时间。假设每磁道划分成10个物理块,每块存放1个逻辑记录。逻辑记录R1,R2,…,R10存放在同一个磁道上,记录的安排顺序如下表所示:
| 物理块 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 |
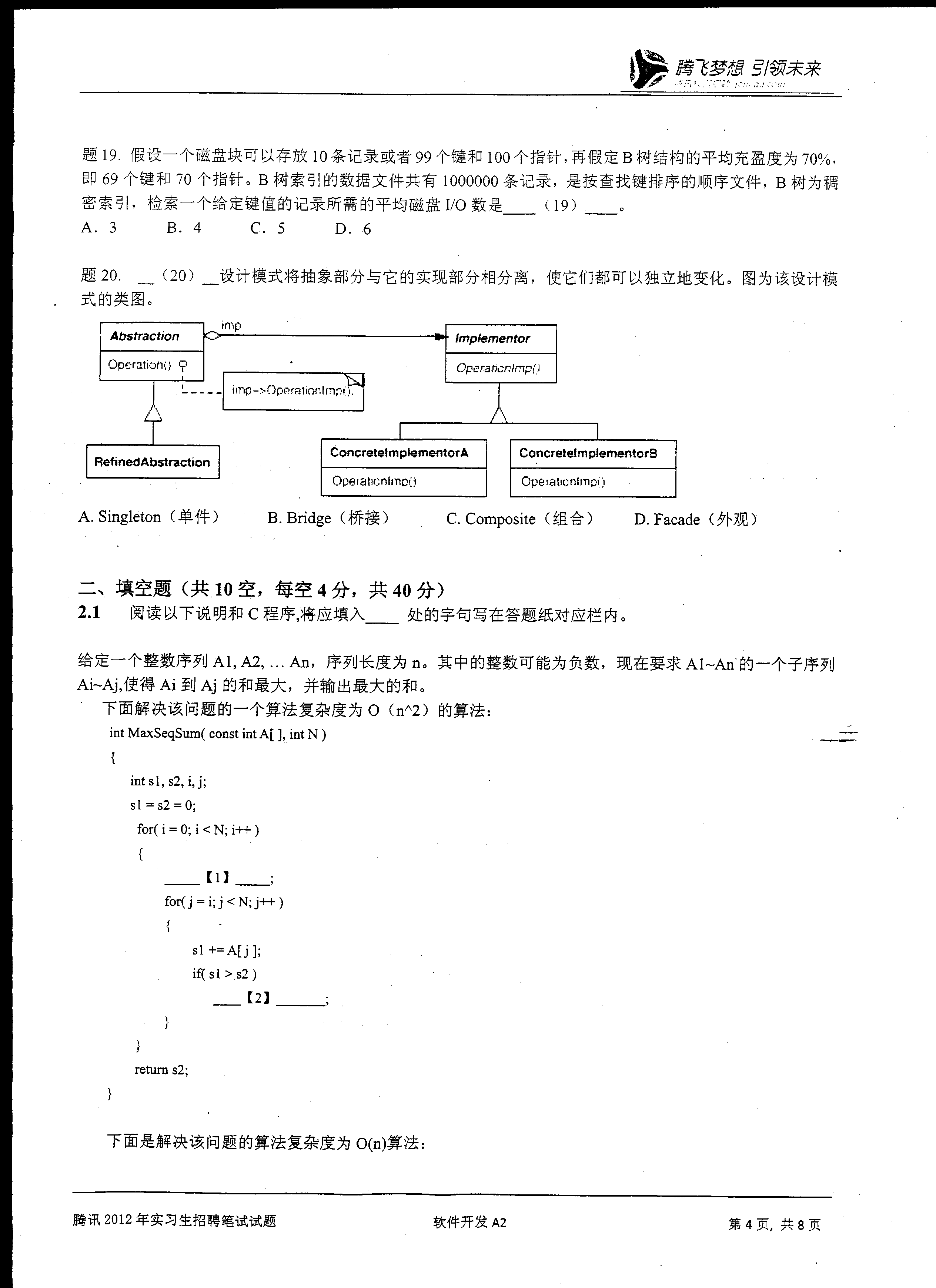
| 逻辑记录 | R1 | R2 | R3 | R4 | R5 | R6 | R7 | R8 | R9 | R10 |
假定磁盘的旋转速度为20ms/周,磁头当前处在R1的开始处。若系统顺序处理这些记录,使用单缓冲区,每个记录处理时间为4ms,则处理这10个记录的最长时间为(15);若对信息存储进行优化分布后,处理10个记录的最少时间为 (16)。
(15)A.180msB.200msC.204msD.220ms
(16)A.40msB.60msC.100msD.160ms
试题分析
系统读记录的时间为20/10=2ms。对第一种情况:系统读出并处理记录R1之后,将转到记录R4的开始处,所以为了读出记录R2,磁盘必须再转一圈,需要2ms(读记录)加20ms(转一圈)的时间。这样,处理10个记录的总时间应为处理前9个记录(即R1,R2,…,R9)的总时间再加上读R10和处理时间(9×22ms+6ms=204ms)。
对于第二种情况,若对信息进行分布优化的结果如下表所示:
| 物理块 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 逻辑记录 | R1 | R8 | R5 | R2 | R9 | R6 | R3 | R10 | R7 | R4 |
从上表可以看出,当读出记录R1并处理结束后,磁头刚好转至R2记录的开始处,立即就可以读出并处理,因此处理10个记录的总时间为:
10×(2ms(读记录)+4ms(处理记录))=10×6ms=60ms
参考答案 (15)C(16)B
选择题4:
R2的使用时间 = 70ms
关键是所有进程完成需要的时间。其中要注意考虑1.可剥夺 2.优先级
列出CPU时间分布:
0 - 20 P3
20 - 30 p2
30 - 40 p1
40 - 60 p2 + R2 40MS = 100MS p2进程结束
60 - 70 p3
70 - 80 p1 p1进程结束
80 - 90 p3 + R1 10ms = 100ms p3进程结束
所以,进程完成总时间为100MS
利用率 = 70 / 100 = 70%
选择题10:
A。进入目录都要x权限(执行权限),查看目录下的文件需要r权限(读权限)和x权限,因为相当于进入了目录。执行目录下某个可执行文件,需要进入目录的x权限,以及对该执行文件的x权限。
选择题12:
B。物理地址(即实际存储地址)=基址+偏移。逻辑地址=偏移,3*8*1024+9612%8192
答案另参考:http://www.cnblogs.com/jerry19880126/archive/2012/08/04/2623309.html















 1949
1949











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









