







什么是数据倾斜
Hadoop能够进行对海量数据进行批处理的核心,在于它的分布式思想,通过多台服务器(节点)组成集群,共同完成任务,进行分布式的数据处理。
理想状态下,一个任务是由集群下所有机器共同承担执行任务,每个节点承担的任务应该相近,但实际上在并行处理过程中,分配到每台节点的数据量并不是均匀的,当大量的数据分配到某一个节点时(假设10个节点,5亿数据),那么原本只需要1小时完成的工作,变成了其中9个节点不到1小时就完成了工作,而分配到了大量数据的节点,花了5个小时才完成
从最终结果来看,就是这个处理10亿数据的任务,集群花了5个小时才最终得出结果。大量的数据集中到了一台或者几台机器上计算,这些数据的计算速度远远低于平均计算速度,导致整个计算过程过慢,这种情况就是发生了数据倾斜。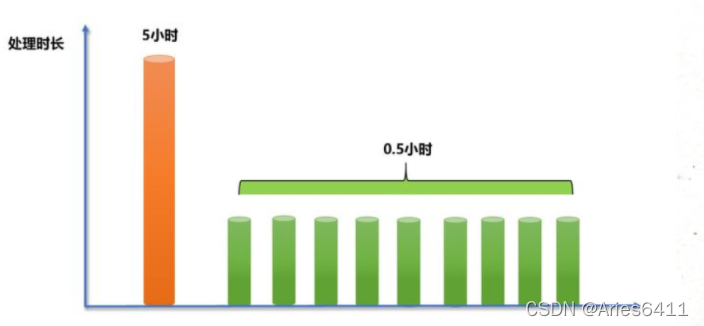
为什么会导致数据倾斜
数据倾斜发生的原因
1)、key分布不均匀
某些key的数量过于集中,存在大量相同值的数据
存在大量异常值或空值。
2)、业务数据本身的特性
例如某个分公司或某个城市订单量大幅提升几十倍甚至几百倍,对该城市的订单统计聚合时,容易发生数据倾斜。
3)、建表时考虑不周
4)、某些SQL语句本身就有数据倾斜
两个表中关联字段存在大量空值,或是关联字段的数据不统一,例如在A表中值是大写,B表中值是小写等情况。
发生数据倾斜的SQL操作

数据倾斜发生时的现象
MapReduce任务:
主要表现在ruduce阶段卡在99.99%,一直99.99%不能结束。
- 有一个多几个reduce卡住
- 各种container报错OOM
- 读写的数据量极大,至少远远超过其它正常的reduce伴随着数据倾斜,会出现任务被kill等各种诡异的表现。
Spark任务:
- 绝大多数task执行得都非常快,但个别task执行的极慢。
- 单个Executor执行时间特别久,整体任务卡在某个stage不能结束
- Executor lost,OOM,Shuffle过程出错。
- 正常运行的任务突然失败
- 用SparkStreaming做实时算法时候,一直会有executor出现OOM的错误,但是其余的executor内存使用率却很低。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 8835
8835











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









