







Hadoop的 hdfs 和 mapreduce 子框架主要是针对大数据文件设计的,在小文件的处理上不但效率低下,而且十分消耗磁盘空间(每一个小文件占用一个Block , hdfs默认block大小为128M)。因此,hadoop提供给我们SequenceFile和MapFile两种容器处理小文件,将这些小文件组织起来统一存储。
【SequenceFile】
1、SequenceFile概述
(1)SequenceFile文件是Hadoop用来存储二进制形式的 <key, value> 而设计的一种平面文件(Flat File)
(2)SequenceFile是一种容器,把所有文件打包到SequenceFile类中可以高效的对小文件进行存储和处理
(3)SequenceFile文件不按照其存储的Key进行排序,其提供的内部类Writer提供了append功能
(4)SequenceFile中的Key 和 Value 可以使任意类型的Writable或自定义Writable
(5)在存储结构上,SequenceFile由一个Header 后跟多条Record组成,Header主要包含Key classname,value classname,存储压缩算法,用户自定义元数据等信息,此外,还包含一些同步标识,用于快速定位到记录的边界。每条Record以键值对的方式进行存储,用来表示它的字符数组可以一次解析成:记录的长度、Key的长度、Key值和value值,并且Value值的结构取决于该记录是否被压缩。
2、SequenceFile压缩
(1)SequenceFIle的内部格式取决于是否启用压缩,如果是压缩,则又可以分为记录压缩和块压缩。
(2)三种类型的压缩:
a.无压缩类型:如果没有启用压缩(默认设置)那么每个记录就由它的记录长度(字节数)、键的长度,键和值组成。长度字段为4字节。
b.记录压缩类型:记录压缩格式与无压缩格式基本相同,不同的是值字节是用定义在头部的编码器来压缩。注意:键是不压缩的。下图为记录压缩:
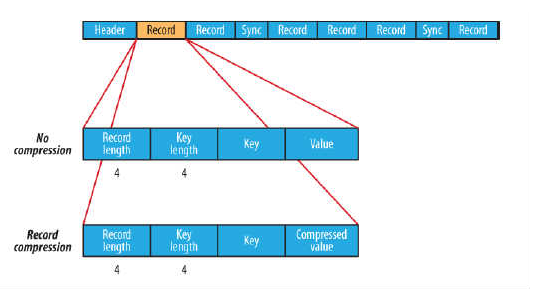
c.块压缩类型:块压缩一次压缩多个记录,因此它比记录压缩更紧凑,而且一般优先选择。当记录的字节数达到最小大小,才会添加到块。该最小值由io.seqfile.compress.blocksize中的属性定义。默认值是1000000字节。格式为记录数、键长度、键、值长度、值。下图为块压缩:
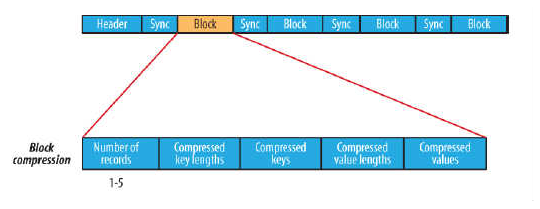
3、SequenceFile实例
工具类:
package com.yc.hadoop42_003_mapreduce;
import java.io.IOException;
import java.net.URI;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IOUtils;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.SequenceFile;
import org.apache.hadoop.io.SequenceFile.Reader;
import org.apache.hadoop.io.SequenceFile.Writer;
import org.apache.hadoop.io.Text;
public class SequenceFileUtil {
private static Configuration conf = new Configuration();//创建配置文件
private static URI uri = URI.create("hdfs://master:9000/");
public static void doWrite(String[] texts, String strPath) {
try {
Writer writer = SequenceFile.createWriter(conf, Writer.file(new Path(strPath)),
Writer.keyClass(IntWritable.class), Writer.valueClass(Text.class));
StringBuffer str = new StringBuffer();
for (String text : texts) {
writer.append(new IntWritable(str.length()), new Text(text));
str.append(text);
}
IOUtils.closeStream(writer); //关闭流
} catch (IllegalArgumentException | IOException e) {
e.printStackTrace();
}
}
public static void doRead(String strPath) {
try {
Reader reader = new Reader(conf, Reader.file(new Path(strPath)));
IntWritable key = new IntWritable();
Text value = new Text();
while (reader.next(key, value)) {
System.out.println("key:" + key);
System.out.println("value:" + value);
System.out.println("position:" + reader.getPosition()); //返回输入文件中的当前字节位置
}
IOUtils.closeStream(reader);
} catch (IllegalArgumentException | IOException e) {
e.printStackTrace();
}
}
}
测试类:
package com.yc.hadoop42_003_mapreduce;
import org.junit.Test;
public class SequenceFileUtilTest {
@Test
public void testDoWrite() {
String[] texts = {"人生若只如初见", "何事秋风悲画扇",
"等闲变却故人心", "却道故人心易变",
"骊山语罢清宵半", "泪雨零铃终不怨",
"何如薄幸锦衣郎", "比翼连枝当日愿"};
SequenceFileUtil.doWrite(texts, "hdfs://master:9000/data/test.txt");
}
@Test
public void testDoRead() {
SequenceFileUtil.doRead("hdfs://master:9000/data/test.txt");
}
}
key:0
value:人生若只如初见
position:173
key:7
value:何事秋风悲画扇
position:218
key:14
value:等闲变却故人心
position:263
key:21
value:却道故人心易变
position:308
key:28
value:骊山语罢清宵半
position:353
key:35
value:泪雨零铃终不怨
position:398
key:42
value:何如薄幸锦衣郎
position:443
key:49
value:比翼连枝当日愿
position:488
4、SequenceFile总结
【优点】
a、支持基于记录(Record)或块(Block)的数据压缩。
b、支持splitable,能够作为MapReduce的输入分片。
c、修改简单:主要负责修改相应的业务逻辑,而不用考虑具体的存储格式。
【缺点】
a、需要一个合并文件的过程,且合并后的文件不方便查看。
【MapFile】
1、MapFile概述
(1)MapFile是排序后的SequenceFile,通过观察其目录结构可以看到MapFile由两部分组成分别是data和index。
(2)index作为文件的数据索引,主要记录了每个Record的Key值,以及该Record在文件中的偏移位置。在MapFile被访问的时候,索引文件会被加载到内存,通过索引映射关系可以迅速定位到指定Record所在文件位置,因此,相对SequenceFile而言,MapFile的检索效率是最高的,缺点是会消耗一部分内存来存储index数据。
(3)需要注意的是,MapFile并不不会把所有的Record都记录到index中去,默认情况下每隔128条记录会存储一个索引映射。当然,记录间隔可认为修改,通过MapFile.Writer的setIndexInterval()方法,或修改io.map.index.interval属性。
(4)与SequenceFile不同的是,MapFile的KeyClass一定要实现WritableComparable接口,即Key值是可比较的。
2、MapFile实例
工具类:
package com.yc.hadoop42_003_mapreduce;
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IOUtils;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.MapFile;
import org.apache.hadoop.io.Text;
public class MapFileUtil {
private static Configuration conf = new Configuration();
public static void doWriter(String[] texts, String dirPath) {
try {
MapFile.Writer writer = new MapFile.Writer(conf, new Path(dirPath),
MapFile.Writer.keyClass(LongWritable.class), MapFile.Writer.valueClass(Text.class));
LongWritable key = new LongWritable();
for (String text : texts) {
writer.append(key, new Text(text));
key.set(key.get()+text.getBytes().length);
}
IOUtils.closeStream(writer);
} catch (IllegalArgumentException | IOException e) {
e.printStackTrace();
}
}
public static void doReader(String dirPath) {
try {
MapFile.Reader reader = new MapFile.Reader(new Path(dirPath), conf);
LongWritable key = new LongWritable();
Text value = new Text();
while (reader.next(key, value)) {
System.out.println("key:" + key + ", value:" + value);
}
IOUtils.closeStream(reader);
} catch (IllegalArgumentException | IOException e) {
e.printStackTrace();
}
}
}
测试类:
package com.yc.hadoop42_003_mapreduce;
import org.junit.Test;
public class MapFileUtilTest {
@Test
public void testDoWriter() {
String[] texts = { "人生若只如初见", "何事秋风悲画扇", "等闲变却故人心", "却道故人心易变", "骊山语罢清宵半", "泪雨零铃终不怨", "何如薄幸锦衣郎", "比翼连枝当日愿" };
MapFileUtil.doWriter(texts, "hdfs://master:9000/data/test01.txt");
}
@Test
public void testDoReader() {
MapFileUtil.doReader("hdfs://master:9000/data/test01.txt");
}
}
测试结果:
key:0, value:人生若只如初见
key:21, value:何事秋风悲画扇
key:42, value:等闲变却故人心
key:63, value:却道故人心易变
key:84, value:骊山语罢清宵半
key:105, value:泪雨零铃终不怨
key:126, value:何如薄幸锦衣郎
key:147, value:比翼连枝当日愿















 99
99

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









