







目录
1.Lena.yuv 原始图片大小为96KB,分辨率为256*256
2.Birds.yuv 原始图像大小为576KB,分辨率为768*512
一、实验目的
掌握DPCM编解码系统的基本原理。初步掌握实验用C/C++/Python等语言编程实现DPCM编码器,并分析其压缩效率。
二、实验原理
1.DPCM编解码原理
DPCM是差分预测编码调制的缩写,是比较典型的预测编码系统。在DPCM系统中, 预测器的输入是已经解码以后的样本。之所以不用原始样本来做预测,是因为在解码端无法得到原始样本,只能得到存在误差的样本。因此,在DPCM编码器中实际内嵌了一个解码器,如编码器中虚线框中所示。
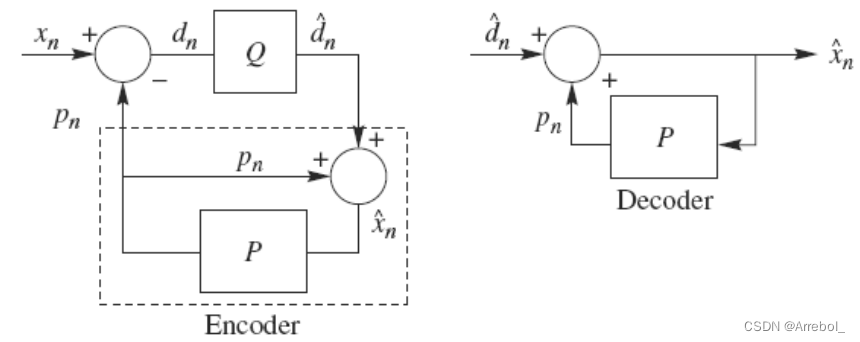
在一个DPCM系统中,有两个因素需要设计:预测器和量化器。理想情况下,预测器和量化器应进行联合优化。实际中,采用一种次优的设计方法:分别进行线性预测器和量化器的优化设计。
次优化方法的解释:在这种方法中,前提条件是量化电平数必须足够大,在该条件下,重建样本和原始样本近似相等,可以将量化器与预测器分开设计,使它们各自最优,从而达到整体最优。
2.DPCM编码系统的设计
在本次实验中,采用固定预测器和均匀量化器。预测器采用左方预测。对预测误差分别进行8bit、4bit、2bit均匀量化。在DPCM编码器实现的过程中同时输出预测误差图像和重建图像,将原始图像和预测误差图像输入Huffman编码器得到输出码流、给出概率分布并计算压缩比。最后比较两种系统之间的编码效率。
三、实验步骤
1.将bmp文件转换为yuv文件作为输入
2.根据给定的量化比特数进行量化和预测
3.输出预测误差图像和重建图像
4.计算PSNR
5.对原始图像和预测误差图像进行Huffman编码
6.根据输出码流画概率分布图、计算压缩比
四、代码实现
/***
* ori_buf:原始图像
* pred_buf:预测误差图像
* rec_buf:重建图像
* n:量化比特数
*/
void quantify(unsigned char* ori_buf, unsigned char* pred_buf, unsigned char* rec_buf,int n) {
int count = 0;
for (int i = 0; i < height; i++) {
for (int j = 0; j < width; j++) {
count = i * width + j;
if (count == i * width) {//第一列 参考值为128
pred_buf[count] = (ori_buf[count] - 128) / pow(2, (9 - n)) + 128;
rec_buf[count] = (pred_buf[count] - 128) * pow(2, (9 - n)) + 128;
}
else {//量化后上抬128便于观察 重建值=反量化后的误差+上一个重建值
pred_buf[count] = (ori_buf[count] - rec_buf[count - 1]) / pow(2, (9 - n)) + 128;
rec_buf[count] = (pred_buf[count] - 128) * pow(2, (9 - n)) + rec_buf[count - 1];
}
}
}
}五、实验结果及分析
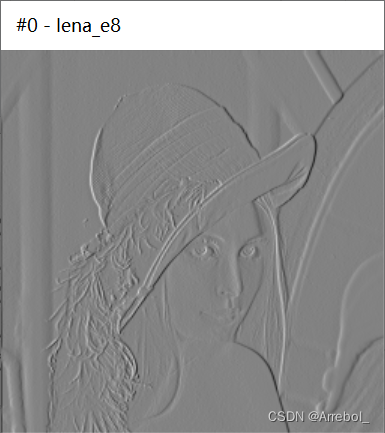
1.Lena.yuv 原始图片大小为96KB,分辨率为256*256
| 原图 | 预测误差 | 重建图 |
|---|---|---|
 |  |  |
|  |  |
|  |  |
| 处理 | 概率分布 | 平均码长 | 压缩比 | PSNR |
|---|---|---|---|---|
| 原图+熵编码 | 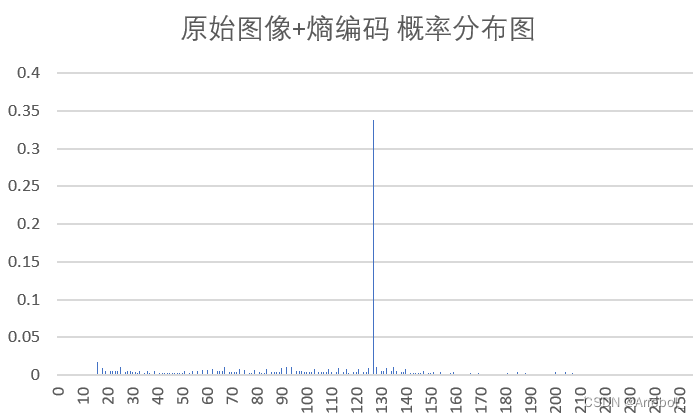 | 8.385 | 1.391 | -- |
| 8bit量化+熵编码 | 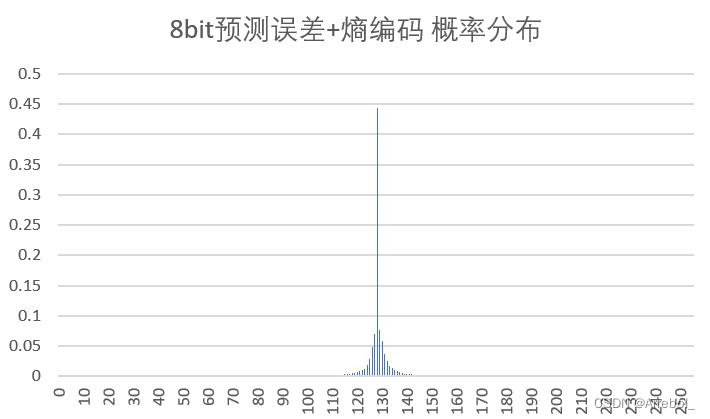 | 11.587 | 2.133 | 51.264 |
| 4bit量化+熵编码 | 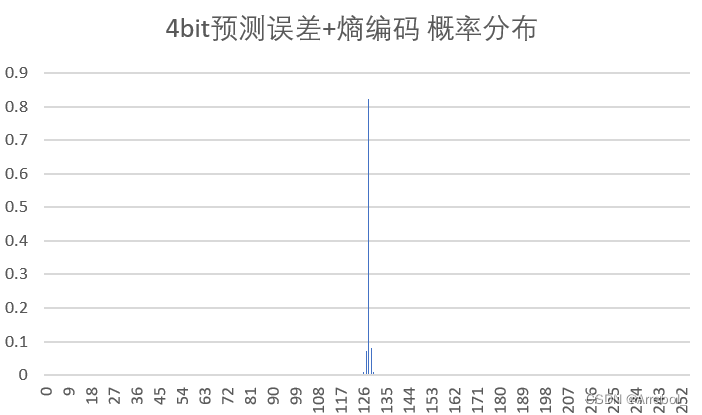 | 6.417 | 5.647 | 22.929 |
| 2bit量化+熵编码 | 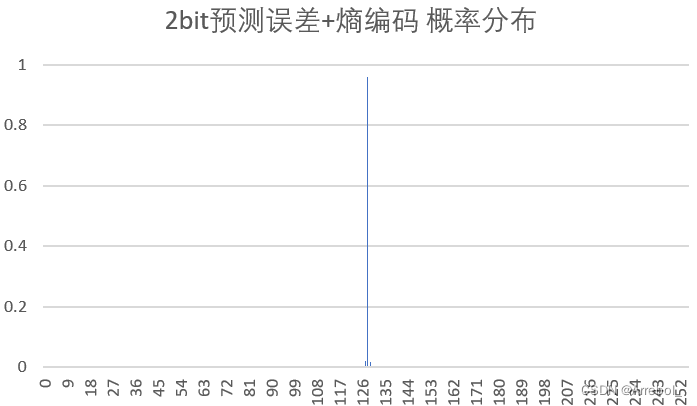 | 1.667 | 7.384 | 11.224 |
2.Birds.yuv 原始图像大小为576KB,分辨率为768*512
| 原图 | 预测误差图 | 重建图 |
|---|---|---|
 |  |  |
 |  |  |
 |  |  |
| 处理 | 概率分布 | 平均码长 | 压缩比 | PSNR |
|---|---|---|---|---|
| 原图+熵编码 | 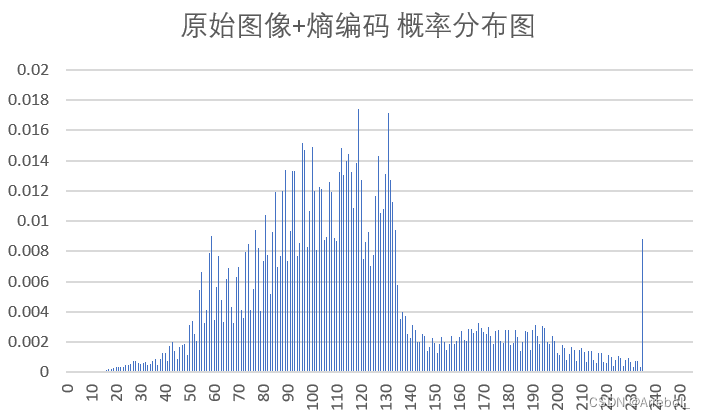 | 8.623 | 1.108 | -- |
| 8bit量化+熵编码 | 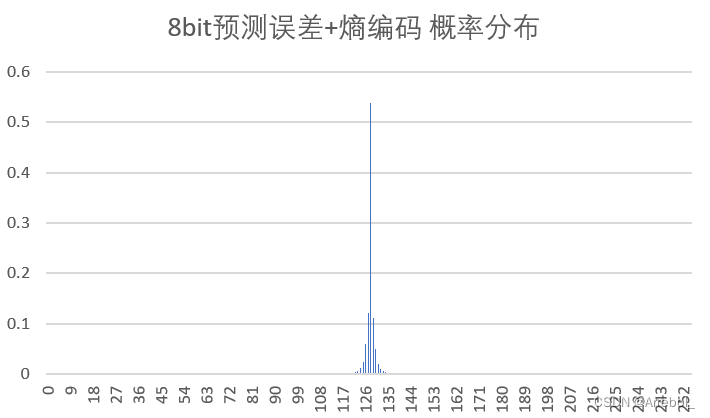 | 13.774 | 3.097 | 51.052 |
| 4bit量化+熵编码 | 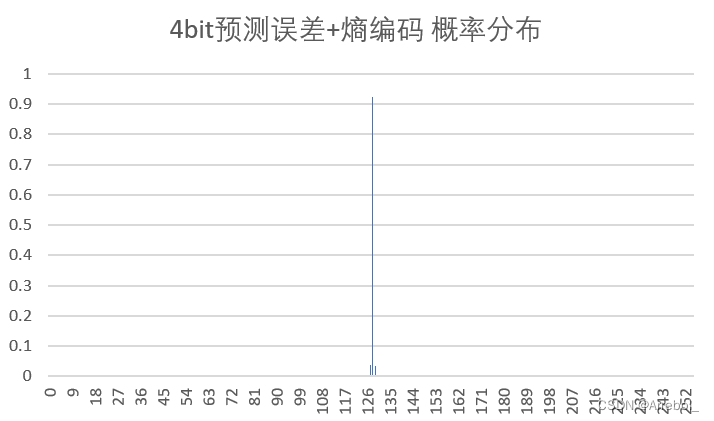 | 5.909 | 7.111 | 22.829 |
| 2bit量化+熵编码 | 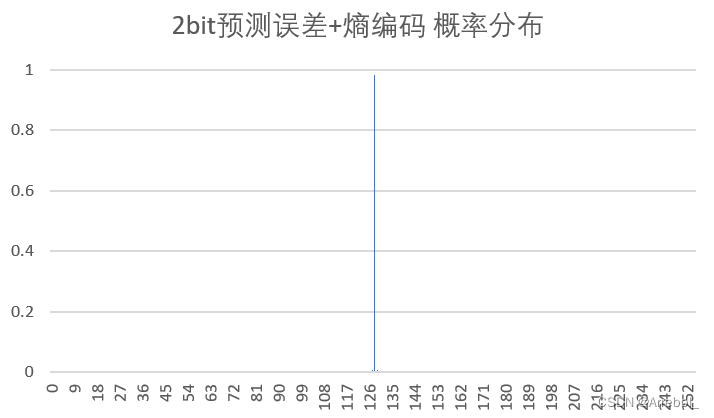 | 1.667 | 7.784 | 9.831 |
3.结果分析
(1)DPCM+熵编码 和 仅熵编码 编码效率的比较
PSNR反映了图像的质量,PSNR越高,说明图像质量越好。从以上数据中可以看出,DPCM+熵编码系统的压缩比较高,PSNR比仅进行熵编码的图像要低。但在8bit量化的重建图像中,PSNR已经超过50dB,肉眼难以观察到明显的失真。
(2)量化比特数对结果的影响
从以上数据可以看出,量化比特数越少,平均码长越低,压缩比越高,图像质量越差。从量化后重建图像也可以看出,除了8bit量化的情况,其他情况的重建图像都有明显失真(边缘忙乱、颗粒噪声等)。这是因为随着量化比特数减少,量化区间减少,量化误差会增大,图像的失真就会越明显。
在实际应用中应结合实际情况,对压缩比和图像质量有所取舍,采用折中的方案达到最优化结果。
(3)概率分布
原始图像在0~255内都有分布,而由于相邻像素之间的相关性,误差图像的分布集中在0附近(为了使结果便于观察,实验中上抬了128,因此概率分布集中在128附近),近似为拉普拉斯分布,很适合用Huffman编码。
从结果中亦可以看出,预测误差总是具有比原始密度更小的熵,预测的过程是把样值间的大部分冗余去掉。















 397
397











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









