







原文链接:LogBERT: Log Anomaly Detection via BERT | IEEE Conference Publication | IEEE Xplore
LogBERT:基于BERT的日志异常检测
摘要——在在线计算机系统中,检测异常事件对于保护系统免受恶意攻击或故障至关重要。系统日志记录了计算事件的详细信息,被广泛地用于系统状态分析。本文提出了用于日志异常检测的LogBERT,是一种基于双向编码器表示(BERT)的自监督框架。LogBERT通过两种新颖的自监督训练任务——掩码日志消息预测和超球体体积最小化——学习正常日志序列的模式。经过训练后,LogBERT能够捕捉正常日志序列的模式,并进一步检测出潜在模式偏离预期模式的异常事件。通过在三个日志数据集上进行实验的结果表明,LogBERT在异常检测任务中优于现有的最新方法。
I.引言
在线计算机系统容易受到网络空间中各种恶意攻击的威胁。及时检测在线计算机系统中的异常事件是保护系统免受攻击或故障的基本步骤。系统日志记录了计算机系统生成的计算事件的详细信息,如今在异常检测中发挥着重要作用。
目前,为了从日志消息中识别异常事件,许多传统的机器学习模型被提出。这些方法从日志消息中提取有用的特征,并采用机器学习算法分析日志数据[1]。由于数据不平衡问题,在监督学习环境下训练一个二分类器来检测异常日志序列变得非常困难。因此,许多无监督学习模型被用于检测异常,如主成分分析(PCA)[2],或单类分类模型,如单类支持向量机[3][4]。然而,基于手工(hand-craft)特征的传统机器学习模型难以捕捉离散日志消息的时间信息。
近年来,深度学习模型尤其是循环神经网络(RNN),由于能够捕捉序列数据中的时间信息,已被广泛应用于日志异常检测[5][6][7]。然而,使用RNN建模日志数据仍然存在一些限制。首先,传统的RNN无法编码同时来自左右上下文的日志序列的上下文信息。然而,在基于日志消息检测恶意攻击时,观察完整的上下文信息(而不仅仅是来自前一步的内容)至关重要。尽管如今常用双向RNN来捕捉上下文信息,该网络由两个隐藏层组成,能够在正向和反向传递信息,但它仍然面临梯度消失或爆炸的问题,这意味着模型难以捕捉长期依赖关系。由于日志序列通常包含大量日志消息,因此捕捉长期依赖关系对于检测异常至关重要。其次,当前基于RNN的异常检测模型通过预测给定前一条日志消息的下一条日志消息来训练模型以捕捉正常序列的模式。这种训练的目标主要集中于捕捉正常序列中日志消息之间的相关性。当日志序列中的这种相关性被破坏时,RNN模型无法基于前面的消息正确预测下一条日志消息,从而将该序列标记为异常。然而,仅使用下一条日志消息的预测作为目标函数,无法明确地编码所有正常序列共享的通用模式。
为了解决现有基于RNN模型的局限性,本文提出了LogBERT,一种基于双向编码器表示(BERT)进行日志异常检测的自监督框架。受启发于BERT在建模顺序文本数据方面取得的巨大成功[8],我们利用BERT来捕捉正常日志序列的模式。通过使用BERT框架,我们期望每条日志条目的上下文嵌入都能够捕捉到各种长度的完整日志序列的信息。为了训练LogBERT进行异常序列检测,并考虑到异常数据的匮乏,我们提出了两个自监督训练任务:1)掩码日志消息预测,旨在正确预测正常日志序列中被随机遮挡的日志消息;2)超球体体积最小化,旨在使正常日志序列在嵌入空间中彼此接近。通过训练以预测随机遮挡的日志消息,我们期望BERT能够捕捉日志消息之间的关联,从而检测到违反这种关联的异常日志序列。此外,通过最小化超球体体积,我们可以强迫BERT模型从各种正常日志序列中捕捉一些通用模式,因为该模型被训练为将日志序列映射到超球体的中心。然后,那些没有通用模式的异常日志序列将远离超球体的中心。训练完成后,我们期望LogBERT能够编码正常日志序列的信息,并基于此推导出检测异常日志序列的标准。三种日志数据集上的实验结果表明,LogBERT在与各种最先进的基线方法的比较中,取得了最佳的日志异常检测性能。
II相关工作
系统日志被广泛应用于大型在线计算机系统的故障排除。其中,每条日志消息通常是一个半结构化的文本字符串。传统方法通过直接使用关键词(如“fail”)或正则表达式来检测异常日志记录。然而,这些方法无法基于一系列操作来检测恶意攻击,因为即使每条日志记录看起来是正常,但整个序列却可能是异常的。为了解决这个问题,提出了许多基于规则的方法来识别异常事件[9],[10]。尽管基于规则的方法可以达到较高的准确性,但它们只能识别预定义的异常场景,并且需要大量的人工工程。当攻击者发起新类型的攻击时,基于规则的方法就无法提供良好的性能。
随着恶意攻击变得愈发复杂,多种基于学习的方法被提出。此类方法的典型流程包括以下三个步骤 [11]。首先,采用日志解析器将日志消息转换为日志键。接着,使用特征提取方法(如 TF-IDF)构建特征向量,以在一个滑动窗口中表示一系列日志键。基于提取的特征向量,再通过一些监督学习方法(如决策树或 SVM)来检测异常序列 [11]。然而,由于异常序列稀缺,手动收集和标注大量异常数据在实际操作中并不可行。因此,在大多数情况下,通常采用无监督的方法来检测异常序列 [12],[13]。传统机器学习方法的主要局限在于无法从序列数据中捕捉到时间信息。
近年来,许多基于深度学习的日志异常检测方法被提出 [14],[5],[15],[6],[16],[7]。目前,大多数方法采用递归神经网络(RNN),尤其是长短期记忆网络(LSTM)或门控循环单元(GRU),对正常的日志键序列进行建模,并通过计算异常分数来检测异常日志序列 [5],[6],[7]。这些方法的主要思路是使用 RNN 基于序列中的前几条日志消息预测下一条可能的日志消息,如果实际消息超出了预期正常日志消息的候选集,则将该序列被判定为异常。最近的一项研究构建了一个基于日志序列的图结构,并利用图嵌入技术进行异常检测 [16]。在本研究中,我们探索了先进的 BERT 模型来捕捉日志序列信息,并提出了两种新颖的自监督任务来训练该模型。
III. LOGBERT
在本节中,我们介绍了用于日志序列异常检测的框架 LogBERT。受到 BERT [8] 的启发,LogBERT 利用 Transformer 编码器对日志序列进行建模,并通过新颖的自监督任务进行训练,以捕捉正常序列的模式。图 1 展示了 LogBERT 的整体框架。
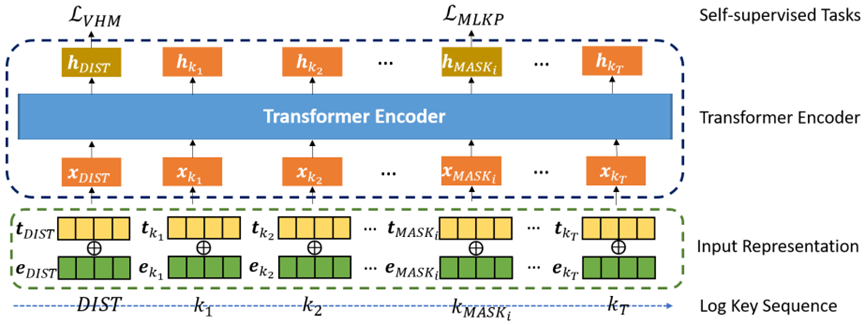
图1:LogBERT概述
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









