






MySQL数据库/表基础(初阶)
文章目录
前言
存储数据用文件就可以了,为什么还要弄个数据库?
文件保存数据有以下几个缺点:
文件的安全性问题
文件不利于数据查询和管理
文件不利于存储海量数据
文件在程序中控制不方便
数据库存储介质:
磁盘
内存
为了解决上述问题,专家们设计出更加利于管理数据的软件——数据库,它能更有效的管理数据。数据库可以提供远程服务,即通过远程连接来使用数据库,因此也称为数据库服务器。
数据库是一个客户端—服务器的一个程序
一、数据库的操作
1.创建数据库
首先,我们要创建出一个数据库。
语法:
create database if not exists 数据库名 character set utf8mb4;

- 其实我们最简单的创建数据库的SQL语句只有
create database 数据库名;
-
但是如果当我们要创建的数据库已经存在时就会报错,为了整个SQL语句的畅通性,要加上一个约束条件,这样即使存在了也不会出现报错。如果系统没有名为 student 的数据库,则创建一个,如果有则不创建。

-
在数据库名后还需添加上指定的字符集,创建一个使用 utf8mb4 字符集的 student 数据库。当我们创建数据库没有指定字符集和校验规则时,系统使用默认字符集:utf8
-
MySQL的utf8编码不是真正的utf8,没有包含某些复杂的中文字符。MySQL 真正的utf8 是使用 utf8mb4。
2.使用数据库
语法:
use 数据库名;
- 这一步非常关键,在操作表之前一定要先使用数据库才能进行后续的表操作.
3.删除数据库
语法:
drop database 数据库名;
- 数据库删除以后,里面的表和数据全部都会被删除。所以这是一部非常危险的操作,在进行删库操作前一定要再三检查,否则后果自负。
4.显示当前的数据库
show databases;
- 可以显示当前所有的数据库。
二、常用数据类型
INT:整型
DECIMAL(M, D):浮点数类型
VARCHAR(SIZE):字符串类型
TIMESTAMP:日期类型
- 上面是常用的数据类型,在往表中插入数据时要指定数据的数据类型。
三、表的操作
1、创建表
语法:
create table 表名(
field1 datatype,
field2 datatype,
field3 datatype
);
示例:
create table student (
id int,
name varchar(20),
age int,
sex varchar(1)
);

2、查看表结构
语法:
desc 表名;

- 这里的字段名字和字段类型是必须要在创建表时说明好的。索引类型和默认值会在后续介绍。
3、删除表
语法:
drop table 表名;
- 同样,这里的删表和删库都是很危险的一个动作,稍有不慎万劫不复。
四、CRUD(增删改查—重点)
增删改查是在数据库操作中主要的操作,同样也是重要的操作。
1、新增
新增就是在创建好的表中插入数据,这里要注意插入的数据和创建表时的列的数量和顺序都要匹配一致。
(1)、单行数据+全列插入
示例:上面我们已经创建好了一张表,里面有 id、name、age、sex 这四列。
insert into student values (8,‘唐三藏’,18,'男');
insert into student values(14,'孙悟空',21,'男');

- 需要注意的是插入的数据和定义表时的要一一对应。
(2)、多行数据+指定列插入
示例:
insert into student (id,name,age) values(18,'曹孟德',29),(21,'孙仲谋',20);

- 这里就是指定了三列进行插入,那么还有一列的数据是啥呢?当然就是默认值了(一般为null)
2、查询
(1)、全列查询
示例:
select * from student;

使用 * 来进行全列查询。
- 通常情况下不建议使用 * 进行全列查询
查询的列越多,意味着需要传输的数据量越大;
可能会影响到索引的使用。
(2)、指定列查询
示例:
select name,age from student;

- 指定列查询就是查询我们想知道的在表中的列的数据。
(3)、表达式查询
就是将表中数据的列进行简单的运算,再将运算后的数据单独成列查询出来。
示例:
select id,name,chinese+math+english from exam_result;

- 注意:虽然我们将这三列数据进行相加运算出来后,但是原来表中的数据并没有发生任何的变化,也就是说这里知识暂时的操作数据。
1.别名
基于上面表达式查询的操作,为了让展示出来的列更加让人理解,我们可以采取取别名的方式来作为该列的名称。
示例:
select id ,name,chinese + math + english as sum from exam_result;
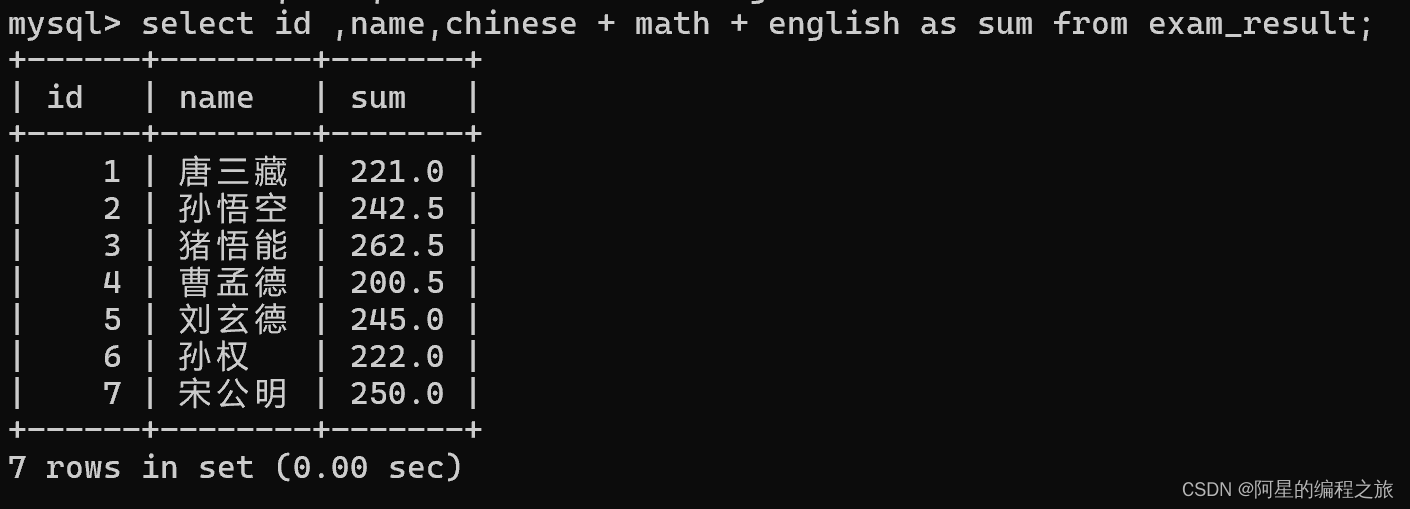
同样,这里的取别名操作也是一个暂时的操作,并不会对数据库中原有的数据发生改变。
2.去重
使用 distinct 关键字对某列数据进行去重。
示例:
select distinct chinese from exam_result;

可以观察上面发现,chinese 列中有两个88.0,当进行去重操作后就会把重复的数值给去掉。当然,这也不会对原有数据产生影响。
3.排序
select name,math from exam_result order by math desc;
select name ,math from exam_result order by math asc;
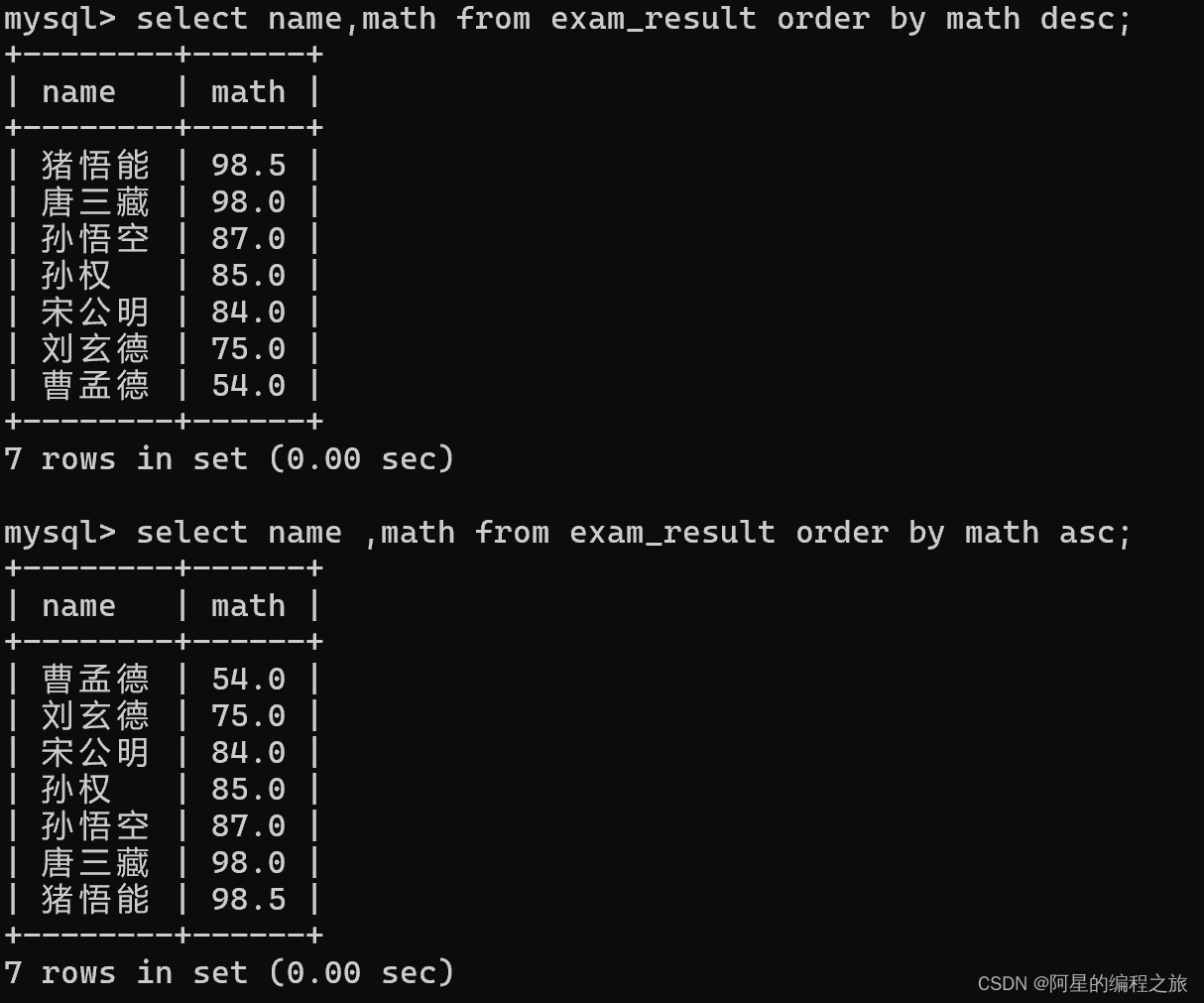
- asc 为升序排序,desc 为降序排序。(如果没有说明则默认按照 asc)
- 没有 order by 子句的查询,返回的顺序是未定义的,永远不要依赖这个顺序。
- null 数据排序,视为比任何值都小,升序时出现在最上面,降序时出现在最下面。
(4)、条件查询 where(重点)
比较运算符:
| 运算符 | 说明 |
|---|---|
| >, >=, <, <= | 大于,大于等于,小于,小于等于 |
| = | 等于,NULL 不安全,例如 NULL = NULL 的结果是 NULL |
| <=> | 等于,NULL 安全,例如 NULL <=> NULL 的结果是 TRUE(1) |
| !=, <> | 不等于 |
| between a0 and a1 | 范围匹配,[a0, a1],如果 a0 <= value <= a1,返回 TRUE(1) |
| in (option, …) | 如果是 option 中的任意一个,返回 TRUE(1) |
| is null | 是 NULL |
| is not null | 不是 NULL |
| like | 模糊匹配。% 表示任意多个(包括 0 个)任意字符;_ 表示任意一个字符 |
逻辑运算符:
| 运算符 | 说明 |
|---|---|
| and | 多个条件必须都为 TRUE(1),结果才是TRUE(1) |
| or | 任意一个条件为 TRUE(1), 结果为 TRUE(1) |
| not | 条件为 TRUE(1),结果为 FALSE(0) |
模糊匹配示例:
select id,name,math from exam_result where name like '孙%';

3、修改 update
示例:
update exam_result set math = 99 where name = '孙悟空';

- 可以发现,进行修改操作以后,数据库中的数据是会发生改变的,所以在数据修改前也一定要再三确认。
4、删除
示例:
delete from exam_result;


- 从上面两张图中,我们可以发现,进行delete 操作后,只是把表中的数据都删除了,但是表还在(变成空表了)。而之前的drop 操作是将整张表都删除,表也没了,要了解其中的差别。
总结
上面就是数据库的一些基本操作,数据库的创建、删除以及数据表的增删改查等一系列操作。















 3万+
3万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









