







个人博客:https://alive0103.github.io/
代码在GitHub:https://github.com/Alive0103/XDU-CS-lab
能点个Star就更好了,欢迎来逛逛哇~❣
一、实验目的与要求
1. 实验目的
- 加深编译原理基础知识的理解:通过词法分析、语法分析、语法制导翻译等环节,理解编译器的基本原理。
- 加深数据库系统相关知识的理解:通过实现数据库的基本操作,理解数据库系统、数据结构与操作系统的相关知识。
2. 实验要求
设计并实现一个DBMS原型系统,能够接受基本的SQL语句,对其进行词法分析、语法分析、语义分析,并解释执行SQL语句,实现对数据库文件的基本操作。
支持的SQL语句及功能如下:
| SQL语句 | 功能 |
|---|---|
| CREATE DATABASE | 创建数据库 |
| USE DATABASE | 选择数据库 |
| CREATE TABLE | 创建表 |
| SHOW TABLES | 显示表名 |
| INSERT | 插入元组 |
| SELECT | 查询元组 |
| UPDATE | 更新元组 |
| DELETE | 删除元组 |
| DROP TABLE | 删除表 |
| DROP DATABASE | 删除数据库 |
| EXIT | 退出系统 |
注: 支持数据类型有
INT、CHAR(N)等。
二、实验环境配置
- 操作系统:Windows 10/11
- 编译器:GCC(MSYS2环境下的mingw-w64-x86_64-gcc)
- 工具链:Flex、Bison
- 开发环境:VSCode、PowerShell
环境安装步骤
-
安装MSYS2
下载并安装 MSYS2。 -
安装开发工具链
打开MSYS2 MINGW64终端,执行:pacman -Syu pacman -S mingw-w64-x86_64-gcc mingw-w64-x86_64-flex mingw-w64-x86_64-bison -
配置环境变量
将C:\msys64\mingw64\bin添加到系统环境变量PATH。 -
验证安装
在终端输入gcc --version、flex --version、bison --version,输出版本号。
三、系统设计
1. 总体架构设计
本系统采用模块化设计,主要分为四大模块:
- 词法分析模块(Flex):负责将输入的SQL语句分解为Token流。
- 语法分析模块(Bison):根据SQL语法规则对Token流进行语法分析,构建语法树并驱动后续操作。
- 语义执行模块(C代码):在Bison的动作代码中实现具体的数据库操作逻辑。
- 数据存储与管理模块(C结构体链表):所有数据库、表、字段、记录等信息均存储于内存链表结构中。
数据流转说明
- 用户输入SQL语句
- Flex将输入分词,生成Token
- Bison根据Token流进行语法分析,匹配规则并调用相应C函数
- C函数操作内存中的数据库/表/记录链表,实现SQL语义
- 输出操作结果或错误信息
2. 主要数据结构设计
2.1 数据库结构体
struct mydb {
char name[50]; // 数据库名
struct table *tbroot; // 指向该数据库下的表链表
struct mydb *next; // 下一个数据库
};
- 设计思路:采用链表管理多个数据库,每个数据库下挂载自己的表链表。
2.2 表结构体
struct table {
char name[50]; // 表名
struct field *ffield; // 字段数组(每个字段包含所有记录的数据)
int flen; // 字段数
int ilen; // 记录数
struct table *next; // 下一个表
};
- 设计思路:每个表有自己的字段数组,字段数组中每个元素存储所有记录的该字段值。
2.3 字段结构体
struct field {
char name[50]; // 字段名
int type; // 0: int, 1: string
struct key {
int intkey;
char skey[50];
} key[100]; // 最多100条记录
};
- 设计思路:每个字段有一个key数组,key[i]表示第i条记录在该字段的值。
2.4 其他结构体
- item_def:用于SELECT/UPDATE等语句的字段链表
- hyper_items_def:用于CREATE TABLE时的字段定义链表
- value_def:用于INSERT等语句的值链表
- conditions_def:用于WHERE条件的二叉树
- table_def:用于多表操作的表链表
- upcon_def:用于UPDATE语句的赋值链表
3. 主要功能实现细节
3.1 数据库管理
- 创建数据库:
createDB()
检查数据库名是否已存在,若不存在则在dbroot链表尾部插入新数据库节点。 - 删除数据库:
dropDB(char *dbname)
遍历dbroot链表,找到目标数据库,释放其所有表和自身内存。 - 切换数据库:
useDB(char *dbname)
遍历dbroot链表,找到目标数据库,更新全局变量database。
3.2 表管理
- 创建表:
createTable(char *tableval, struct hyper_items_def *Hitemroot)
在当前数据库下新建表节点,初始化字段数组,设置字段名和类型。 - 删除表:
dropTable(char *tableval)
遍历表链表,找到目标表,释放其字段数组和自身内存。 - 显示表:
showTable()
遍历当前数据库下的表链表,输出所有表名。
3.3 数据操作
- 插入记录:
multiInsert(char *tableval, struct item_def *itemroot, struct value_def *valroot)
找到目标表,将值链表中的数据依次插入到字段数组的key数组中,支持指定字段插入和全字段插入。 - 查询记录:
selectWhere(struct item_def *itemroot, struct table_def *tableroot, struct conditions_def *conroot)
支持单表和两表联合查询,遍历记录并根据WHERE条件筛选,输出指定字段。 - 更新记录:
updates(struct table *tabletemp, struct upcon_def *uptemp, struct conditions_def *conroot)
遍历表的记录,若满足WHERE条件则将指定字段更新为新值。 - 删除记录:
deletes(char *tableval, struct conditions_def *conroot)
遍历表的记录,若满足WHERE条件则删除该记录(通过后移覆盖实现)。
3.4 词法与语法分析
- sql.l:定义所有SQL关键字、标识符、数字、字符串的正则表达式,生成Token。
- sql.y:定义SQL语句的BNF文法,使用Bison的动作代码调用上述C函数,实现SQL语义。
4. 关键实现举例
4.1 CREATE TABLE 语句处理流程
- 用户输入:
CREATE TABLE STUDENT(SNAME CHAR(20), SAGE INT, SSEX INT); - Flex识别关键字、标识符、类型等Token
- Bison匹配CREATE TABLE语法规则,构建hyper_items_def链表
- 动作代码调用
createTable,在当前数据库下新建表,初始化字段数组 - 输出"Table STUDENT created successfully!"
4.2 SELECT 语句处理流程
- 用户输入:
SELECT SNAME, SAGE FROM STUDENT WHERE SSEX = 1; - Flex分词,Bison语法分析,构建item_def链表和conditions_def条件树
- 动作代码调用
selectWhere,遍历STUDENT表所有记录,筛选SSEX=1的记录,输出SNAME和SAGE字段
5. 内存管理与异常处理
- 所有链表节点和数组均动态分配内存,操作完成后及时释放,防止内存泄漏。
- 对所有输入参数和操作结果进行合法性检查,发现错误及时输出提示信息。
如需进一步细化某一部分(如具体函数实现、数据结构图示、流程图等),请随时告知!
四、实现细节
1. 词法分析(sql.l)
- 定义SQL关键字、标识符、数字、字符串等Token。
- 忽略空白字符和注释。
2. 语法分析(sql.y)
- 定义SQL语句的BNF文法规则。
- 每个语法规则对应C代码动作,实现具体操作。
- 通过
%union和%type支持多种数据类型的语义值传递。
3. 主要C文件
- sql.c:实现所有数据库、表、记录的操作函数。
- sql.h:定义所有结构体和函数声明。
- main函数:在
sql.y中,调用yyparse()启动交互式SQL解析。
4. 编译与运行
flex sql.l
bison -d sql.y
gcc -o mysql sql.tab.c lex.yy.c sql.c
./mysql
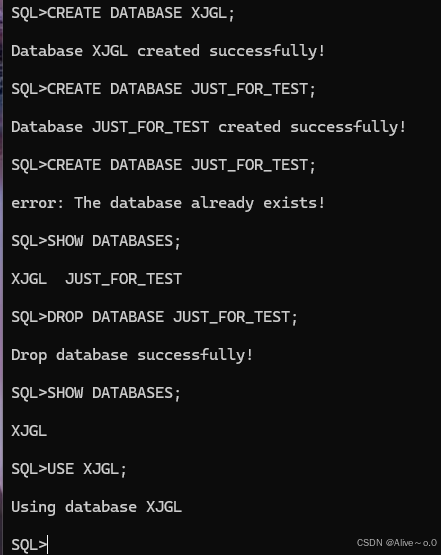
五、运行结果展示
六、带注释版代码
用的时候请把注释去掉,其他相关代码见我仓库
sql.l
%{
/* 定义段开始 */
// 包含标准库头文件
#include <stdio.h> // 标准输入输出函数
#include <stdlib.h> // 标准库函数,如 exit()
#include <string.h> // 字符串处理函数,如 strdup()
#include "sql.h" // 自定义的 SQL 相关头文件
#include "sql.tab.h" // Bison 生成的语法分析器头文件(包含 token 定义)
// 声明外部变量,用于跟踪行号
extern int yylineno;
%}
/* 定义段结束 */
%%
/* 规则段开始 */
/* 关键字处理(不区分大小写) */
/* 匹配 SELECT 或 select,返回 SELECT token */
select | SELECT { return SELECT; }
/* 匹配 DROP 或 drop,返回 DROP token */
drop | DROP { return DROP; }
/* 匹配 TABLE 或 table,返回 TABLE token */
table | TABLE { return TABLE; }
/* 匹配 TABLES 或 tables,返回 TABLES token */
tables | TABLES { return TABLES; }
/* 匹配 DATABASE 或 database,返回 DATABASE token */
database | DATABASE { return DATABASE; }
/* 匹配 DATABASES 或 databases,返回 DATABASES token */
databases | DATABASES { return DATABASES; }
/* 匹配 CREATE 或 create,返回 CREATE token */
create | CREATE { return CREATE; }
/* 匹配 INSERT 或 insert,返回 INSERT token */
insert | INSERT { return INSERT; }
/* 匹配 UPDATE 或 update,返回 UPDATE token */
update | UPDATE { return UPDATE; }
/* 匹配 SET 或 set,返回 SET token */
set | SET { return SET; }
/* 匹配 DELETE 或 delete,返回 DELETE token */
delete | DELETE { return DELETE; }
/* 匹配 FROM 或 from,返回 FROM token */
from | FROM { return FROM; }
/* 匹配 WHERE 或 where,返回 WHERE token */
where | WHERE { return WHERE; }
/* 匹配 INTO 或 into,返回 INTO token */
into | INTO { return INTO; }
/* 匹配 VALUES 或 values,返回 VALUES token */
values | VALUES { return VALUES; }
/* 匹配 AND 或 and,返回 AND token */
and | AND { return AND; }
/* 匹配 OR 或 or,返回 OR token */
or | OR { return OR; }
/* 匹配 INT 或 int,返回 INT token */
int | INT { return INT; }
/* 匹配 CHAR 或 char,返回 CHAR token */
char | CHAR { return CHAR; }
/* 匹配 SHOW 或 show,返回 SHOW token */
show | SHOW { return SHOW; }
/* 匹配 EXIT 或 exit,返回 EXIT token */
exit | EXIT { return EXIT; }
/* 匹配 USE 或 use,返回 USE token */
use | USE { return USE; }
/* 符号处理 */
/* 匹配分号、括号、星号、逗号等符号,直接返回对应字符的 ASCII 值 */
[;] | [(] | [)] | [*] | [,] { return *yytext; }
/* 比较运算符处理 */
"<=" | ">=" | "!" | "<" | ">" | "=" { return *yytext; }
/* 字符串字面量处理 */
/* 匹配单引号括起的字符串(至少包含一个字母,后接字母/数字/下划线) */
'[A-Za-z][A-Za-z0-9_]*' {
yylval.strval = strdup(yytext); // 复制字符串内容到 yylval(用于传递值给语法分析器)
return STRING; // 返回 STRING token
}
/* 标识符处理 */
/* 匹配以字母开头,后接字母/数字/下划线的标识符 */
[A-Za-z][A-Za-z0-9_]* {
yylval.strval = strdup(yytext); // 复制标识符名称
return ID; // 返回 ID token
}
/* 数字处理 */
/* 匹配整数 */
[0-9]+ {
yylval.intval = atoi(yytext); // 将字符串转换为整数值
return NUMBER; // 返回 NUMBER token
}
/* 换行符处理(可能用于跟踪行号) */
\n {
return *yytext; // 返回换行符本身(通常建议在此处增加 yylineno)
}
/* 忽略空白字符 */
[ \t]+ { /* 不做任何操作 */ }
%%
/* 规则段结束 */
sql.y
%{
/* 头文件与全局函数声明 */
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include "sql.h" // 包含自定义数据结构声明
/* 接口声明 */
extern int yylex(); // 词法分析器入口
extern int yyparse(); // 语法分析器入口
extern FILE *yyin; // 输入文件指针
extern char *yytext; // 当前词法单元文本
extern int yylineno; // 当前行号计数器
char database[64] = {0}; // 当前使用的数据库名称存储
extern struct mydb *dbroot; // 全局数据库链表头指针
/* 错误处理函数 */
void yyerror(const char *str) {
fprintf(stderr, "error: %s\n", str); // 输出带错误定位的提示信息
}
/* 输入结束处理函数 */
int yywrap() {
return 1; // 表示输入结束
}
/* 主程序入口 */
int main() {
printf("SQL>"); // 显示交互提示符
return yyparse(); // 启动语法分析器
}
%}
/* 联合体定义 - 用于存储不同类型的语义值 */
%union{
int intval; // 整数值存储
char *strval; // 字符串值存储
struct hyper_items_def *Citemsval; // 表字段定义链表
struct value_def *valueval; // 值列表节点
struct item_def *itemval; // 查询字段项
struct conditions_def *conval; // 条件表达式节点
struct table_def *tbval; // 表名链表节点
struct upcon_def *updateval; // 更新条件节点
}
/* 终结符声明(词法单元)*/
%token SELECT FROM WHERE AND OR DROP DELETE TABLE CREATE INTO VALUES INSERT UPDATE SET SHOW DATABASE DATABASES TABLES EXIT USE
%token <intval> NUMBER // 绑定到intval的数值类型
%token <strval> STRING ID INT CHAR // 绑定到strval的字符串类型
/* 非终结符类型声明 */
%type <intval> comparator // 比较运算符类型
%type <Citemsval> hyper_items create_items // 表字段定义相关
%type <valueval> value_list value // 值列表相关
%type <itemval> item item_list // 查询字段列表相关
%type <conval> condition conditions // 条件表达式相关
%type <tbval> tables // 表名列表相关
%type <updateval> up_cond up_conds // 更新条件相关
/* 运算符优先级定义 */
%left OR // 最低优先级
%left AND // 高于OR
%%
/* 语法规则部分 */
/* 语句集合规则 */
statements: statements statement // 多语句递归定义
| statement // 单语句情况
;
/* 单个语句类型 */
statement: createsql | showsql | selectsql | insertsql | deletesql | updatesql | dropsql | exitsql | usesql;
/* USE语句规则 */
usesql: USE ID ';' '\n' { // 语法:USE 数据库名;
printf("\n");
useDB($2); // 调用数据库切换函数
printf("\nSQL>");
}
/* SHOW语句规则 */
showsql: SHOW DATABASES ';' '\n' { // 显示所有数据库
printf("\n");
showDB(); // 调用数据库列表显示函数
printf("\nSQL>");
}
| SHOW TABLES ';' '\n' { // 显示当前数据库所有表
printf("\n");
showTable(); // 调用表列表显示函数
printf("\nSQL>");
}
/* CREATE语句规则 */
createsql: CREATE TABLE ID '(' hyper_items ')' ';' '\n' { // 创建表语法
printf("\n");
createTable($3, $5); // $3=表名,$5=字段定义链表
printf("\nSQL>");
}
| CREATE DATABASE ID ';' '\n' { // 创建数据库语法
strcpy(database, $3); // 记录当前数据库名
printf("\n");
createDB(); // 调用数据库创建函数
printf("\nSQL>");
}
/* SELECT语句规则 */
selectsql: SELECT '*' FROM tables ';' '\n' { // 全字段查询
printf("\n");
selectWhere(NULL, $4, NULL); // $4=表名链表,NULL表示无字段列表
printf("\nSQL>");
}
| SELECT item_list FROM tables ';' '\n' { // 带字段列表查询
printf("\n");
selectWhere($2, $4, NULL); // $2=字段列表,$4=表名链表
printf("\nSQL>");
}
| SELECT '*' FROM tables WHERE conditions ';' '\n' { // 带条件全字段查询
printf("\n");
selectWhere(NULL, $4, $6); // $6=条件表达式树
printf("\nSQL>");
}
| SELECT item_list FROM tables WHERE conditions ';' '\n' { // 完整SELECT语法
printf("\n");
selectWhere($2, $4, $6); // $2=字段列表,$4=表列表,$6=条件
printf("\nSQL>");
}
/* DELETE语句规则 */
deletesql: DELETE FROM ID ';' '\n' { // 无条件删除
printf("\n");
deletes($3, NULL); // $3=表名,NULL表示无删除条件
printf("\nSQL>");
}
| DELETE FROM ID WHERE conditions ';' '\n' { // 条件删除
printf("\n");
deletes($3, $5); // $5=条件表达式树
printf("\nSQL>");
}
/* INSERT语句规则 */
insertsql: INSERT INTO ID VALUES '(' value_list ')' ';' '\n' { // 全字段插入
printf("\n");
multiInsert($3, NULL, $6); // $3=表名,$6=值列表
printf("\nSQL>");
}
| INSERT INTO ID '(' item_list ')' VALUES '(' value_list ')' ';' '\n' { // 指定字段插入
printf("\n");
multiInsert($3, $5, $9); // $5=字段列表,$9=值列表
printf("\nSQL>");
}
/* UPDATE语句规则 */
updatesql: UPDATE ID SET up_conds ';' '\n' { // 无条件更新
// 数据库存在性检查
struct mydb *dbtemp = dbroot;
struct table *tabletemp = NULL;
while(dbtemp != NULL) {
if(strcmp(dbtemp->name, database) == 0) {
// 遍历表链表查找目标表
tabletemp = dbtemp->tbroot;
while(tabletemp != NULL) {
if(strcmp(tabletemp->name, $2) == 0) {
updates(tabletemp, $4, NULL); // $4=更新条件链表
printf("\nSQL>");
return 0;
}
tabletemp = tabletemp->next;
}
printf("error: Table %s doesn't exist!\n", $2);
printf("\nSQL>");
return 0;
}
dbtemp = dbtemp->next;
}
printf("error: Database %s doesn't exist!\n", database);
printf("\nSQL>");
return 0;
}
| UPDATE ID SET up_conds WHERE conditions ';' '\n' { // 条件更新
// 类似上述数据库/表存在性检查流程
struct mydb *dbtemp = dbroot;
struct table *tabletemp = NULL;
while(dbtemp != NULL) {
if(strcmp(dbtemp->name, database) == 0) {
tabletemp = dbtemp->tbroot;
while(tabletemp != NULL) {
if(strcmp(tabletemp->name, $2) == 0) {
updates(tabletemp, $4, $6); // $6=WHERE条件表达式
printf("\nSQL>");
return 0;
}
tabletemp = tabletemp->next;
}
printf("error: Table %s doesn't exist!\n", $2);
printf("\nSQL>");
return 0;
}
dbtemp = dbtemp->next;
}
printf("error: Database %s doesn't exist!\n", database);
printf("\nSQL>");
return 0;
}
/* DROP语句规则 */
dropsql: DROP TABLE ID ';' '\n' { // 删除表
printf("\n");
dropTable($3); // $3=表名
printf("\nSQL>");
}
| DROP DATABASE ID ';' '\n' { // 删除数据库
printf("\n");
dropDB($3); // $3=数据库名
printf("\nSQL>");
}
/* 退出命令 */
exitsql: EXIT ';' {
printf("\n");
printf("exit with code 0!\n");
exit(0);
}
/* 字段定义规则 */
create_items: ID INT { // 整数字段定义
$$ = (struct hyper_items_def *)malloc(sizeof(struct hyper_items_def));
strcpy($$->field, $1); // 存储字段名
$$
->type = 0; // 类型标记为整数
$$->next = NULL; // 初始化链表指针
}
| ID CHAR '(' NUMBER ')' { // 定长字符字段定义
$$ = (struct hyper_items_def *)malloc(sizeof(struct hyper_items_def));
strcpy($$->field, $1);
$$
->type = 1; // 类型标记为字符
$$->next = NULL;
}
/* 字段定义链表构建 */
hyper_items: create_items { // 单字段情况
$$
= $1;
}
| hyper_items ',' create_items { // 多字段递归组合
$$ = $3; // 新节点成为链表头
$$
->next = $1; // 原有链表接续
}
/* 查询字段项处理 */
item: ID { // 单个查询字段
$$ = (struct item_def *)malloc(sizeof(struct item_def));
strcpy($$
->field, $1); // 存储字段名称
$$->pos = NULL;
$$
->next = NULL;
}
/* 字段列表链表构建 */
item_list: item { // 单字段
$$ = $1;
}
| item_list ',' item { // 多字段递归组合
$$
= $3;
$$->next = $1; // 头插法构建链表
}
/* 值节点处理 */
value: NUMBER { // 整数值
$$
= ((struct value_def *)malloc(sizeof(struct value_def)));
$$->value.intkey = $1; // 存储整数值
$$
->type = 0; // 类型标记
$$->next = NULL;
}
| STRING { // 字符串值
$$ = ((struct value_def *)malloc(sizeof(struct value_def)));
strcpy($$->value.skey, $1); // 复制字符串
$$
->type = 1;
$$->next = NULL;
}
/* 值列表链表构建 */
value_list: value { // 单值
$$
= $1;
}
| value_list ',' value { // 多值递归组合
$$ = $3;
$$->next = $1; // 头插法构建链表
}
/* 比较运算符处理 */
comparator: '=' {$$ = 1; } // 运算符编码
| '>' {$$ = 2; }
| '<' {$$ = 3; }
| ">=" {$$ = 4; }
| "<=" {$$ = 5; }
| '!' '=' {$$
= 6; } // 注意:需确保词法分析器支持"!="作为单一token
/* 条件表达式构建 */
condition: item comparator NUMBER { // 整数比较条件
$$ = ((struct conditions_def *)malloc(sizeof(struct conditions_def)));
$$
->type = 0; // 标记为整数比较
$$->litem = $1; // 左操作数(字段)
$$
->intv = $3; // 右操作数值
$$->cmp_op = $2; // 比较运算符编码
$$
->left = NULL;
$$->right = NULL;
}
| item comparator STRING { // 字符串比较条件
$$
= ((struct conditions_def *)malloc(sizeof(struct conditions_def)));
$$->type = 1; // 标记为字符串比较
$$->litem = $1;
strcpy($$->strv, $3); // 存储比较字符串
$$
->cmp_op = $2;
$$->left = NULL;
$$
->right = NULL;
}
/* 复杂条件表达式树构建 */
conditions: condition { // 基础条件
$$ = $1;
}
| '(' conditions ')' { // 括号优先级
$$
= $2;
}
| conditions AND conditions { // 逻辑与组合
$$ = ((struct conditions_def *)malloc(sizeof(struct conditions_def)));
$$
->cmp_op = 7; // 自定义AND操作码
$$->left = $1; // 左子树
$$
->right = $3; // 右子树
}
| conditions OR conditions { // 逻辑或组合
$$ = ((struct conditions_def *)malloc(sizeof(struct conditions_def)));
$$
->cmp_op = 8; // 自定义OR操作码
$$->left = $1;
$$
->right = $3;
}
/* 表名列表处理 */
tables: ID { // 单表查询
$$ = ((struct table_def *)malloc(sizeof(struct table_def)));
strcpy($$
->table, $1);
$$->next = NULL;
}
| tables ',' ID { // 多表连接
$$ = ((struct table_def *)malloc(sizeof(struct table_def)));
strcpy($$->table, $3); // 存储新表名
$$
->next = $1; // 头插法构建链表
}
/* 更新条件处理 */
up_cond: ID '=' NUMBER { // 整数字段更新
$$ = ((struct upcon_def *)malloc(sizeof(struct upcon_def)));
strcpy($$
->field, $1); // 目标字段
$$->type = 0; // 整数类型标记
$$
->value.intkey = $3; // 新值
$$->next = NULL;
}
| ID '=' STRING { // 字符串字段更新
$$ = ((struct upcon_def *)malloc(sizeof(struct upcon_def)));
strcpy($$->field, $1);
$$->type = 1;
strcpy($$->value.skey, $3); // 存储新字符串值
$$
->next = NULL;
}
/* 更新条件链表构建 */
up_conds: up_cond { // 单个更新条件
$$ = $1;
}
| up_conds ',' up_cond { // 多个更新条件
$$
= $3;
$$->next = $1; // 头插法构建链表
}
%%


















 3064
3064

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











