







1.最简化的代码
继承 ModelViewSet(模型视图集)如下, 这样就包含了6个接口:
from .models import Projects
from .serializers import ProjectsModelSerializer
from rest_framework.viewsets import ModelViewSet
class ProjectViewSet(ModelViewSet):
queryset = Projects.objects.all()
serializer_class = ProjectsModelSerializerurl.py 中,要进行配置:
指定一个 路由前缀,关联 定义的模型是图集类
(详见:视图类、视图集_A~taoker的博客-CSDN博客)
2.搜索 、排序功能
(详见:视图类、视图集_A~taoker的博客-CSDN博客)
查询(list方法)中使用了 filter_queryset方法,所以list查询可以进行搜索,排序。
from rest_framework import filters
class ProjectViewSet(ModelViewSet):
*******
# 搜索、排序功能
filter_backends = [filters.SearchFilter,
filters.OrderingFilter]
search_fields = ["name", 'leader'] # 默认:搜索关键字参数:search, 如:/projects/?search=项目2
ordering_fields = ['id', 'name', 'leader'] # 默认:排序关键字参数:ordering 如:/projects/?ordering=name
3.分页功能
查询(list方法)中使用了 filter_queryset方法,所以list查询可以有分页功能。
一般推荐自定义PageNumberPagination类(utils包中pagination.py)
(详见:视图类、视图集_A~taoker的博客-CSDN博客)
from utils.pagination import PageNumberPagination
class ProjectViewSet(ModelViewSet):
******
# 分页功能 #使用: http://127.0.0.1:8000/projects/?page=1&page_size=3
pagination_class = PageNumberPagination
4. 不同的方法返回不同的序列化器,重写get_serializer_class(),
可以实现不同的接口使用不同的序列化器- 如下达到的效果: * 查询单个项目用的一种序列化器 * 列表接口使用的另一种序列化器,返回的字段就可以定制了
class ProjectViewSet(ModelViewSet):
def get_serializer_class(self):
if self.action == 'retrieve': # 原有的action
return ProjectsModelSerializer1
elif self.action =='list':
return ProjectsModelSerializer
elif self.action =='names': # 自定义的action
return ProjectsModelSerializer2
else:
return super().get_serializer_class()
自定义的action,也可以用自定义的序列化器 ,如下是自定义的names 使用序列化器的代码
class ProjectViewSet(ModelViewSet):
****
@action(methods=['GET'],detail=False,url_path='names',url_name='yyy')
def names(self,request, *args,**kwargs):
# names_list =[]
# for project in self.get_queryset():
# names_list.append({
# 'id':project.id,
# 'name': project.name
# })
queryset = self.get_queryset()
# 过滤一下
queryset = self.filter_queryset(queryset)
serializer=self.get_serializer(queryset,many=True)
# return Response(names_list, status=200)
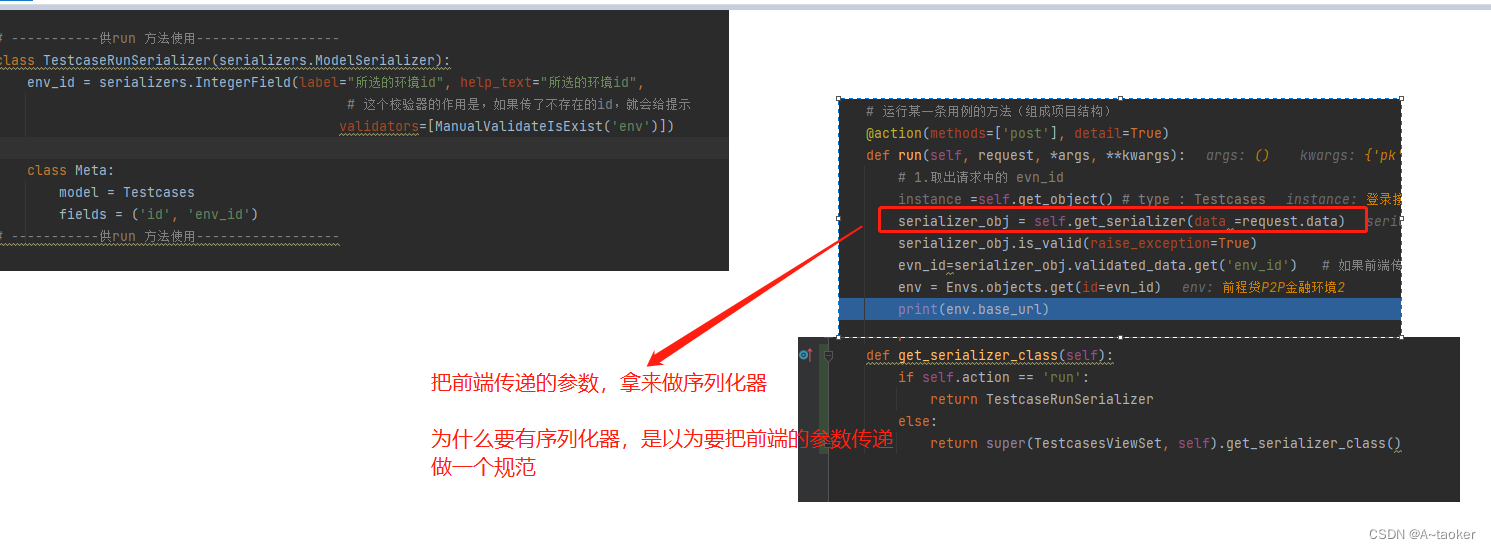
return Response(serializer.data,status=200)a. 用法:不同的方法中,调用get_serializer() , 就能进行序列化
进行一个序列化,本来是这样写serializer= ProjectSerilizer(instance=queryset, many=True)
即这样写 self.get_serializer_class()(instance=queryset, many=True)
但它进行了封装,调用get_serializer时,会调用self.get_serializer_class() ,来判断使用哪个序列化器。
可以直接(在 APIview继承类下使用)
如:序列化 serializer=get_serializer(instance=queryset, many=True)
反序列化 serializer= get_serializer(data=python_data)
5.修改原有的list、retrieve方法
原有方法只有一点点不满足,就考虑用这种重写的方式,如下,重写retrieve方法
def retrieve(self, request, *args, **kwargs):
response =super().retrieve(request,*args,**kwargs)
response.data.pop('id')
return response6.自定义action,可以调原有的list、retrieve方法(47分钟)
如:4中的names方法例子,已经有了过滤、排序,但还没有分页。
可以直接调list方法,有完成一样了,只是调的序列化器不同
class ProjectViewSet(ModelViewSet):
@action(methods=['GET'],detail=False,url_path='names',url_name='yyy')
def names(self,request, *args,**kwargs):
# 直接调list方法,(有分页功能)
return super().list(request, *args,**kwargs)7.重写filter_queryset(), 实现有些action有过滤,有些没有

8.重写paginate_queryse(),实现有些action有分页,有些没有
class ProjectViewSet(ModelViewSet):
def paginate_queryset(self,queryset):
if self.action=="names":
return None
else:
return super().paginate_queryset(queryset)9. 重写get_queryset()
不同的action,得到不同的查询集

10. 设计原则
- 选择合适的【模型视图集】,不一定用6个接口的 ModelViewSet
- 能用已有的逻辑,就调已有的action方法,或者改已有的action方法














 6091
6091











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









