







之前一直用的是hadoop伪分布式来测试程序实例,于是在自己的电脑上用虚拟机搭建了一个3台的集群,主要是熟练一下搭建过程,仅供学习。
1 环境说明
centos6.5
hadoop2.6.4
2 修改主机名和ip
分别在/etc/sysconfig/network 和/etc/hosts文件下修改主机名和ip地址,之后重新启动系统。主机名和ip的对应关系如下所示:
192.168.1.117 hadoop01
192.168.1.118hadoop02
192.168.1.119hadoop03
其中hadoop01和hadoop02是我们的slave节点,hadoop03是我们的master节点。
3 安装JDK,并配置环境变量
export JAVA_HOME=/usr/java/jdk1.7.0_79
export PATH=$PATH:$JAVA_HOME/bin
安装完成之后可以用Java -version命令来测试java环境是否安装成功,3台机子都要安装同样版本的jdk。
4 配置ssh免登录
5 安装hadoop
在http://mirror.bit.edu.cn/apache/hadoop/common处下载hadoop 2.6.4版本,拷贝到/opt目录下解压,在/etc/profile中配置hadoop的环境变量
export HADOOP_HOME=/opt/hadoop-2.6.4
export PATH=$PATH:$HADOOP_HOME/bin
6 配置hadoop文件
(1) hadoop-env.sh文件
在该文件中添加Java环境,如下所示

(2) core-site.xml文件
指定namenode和文件目录
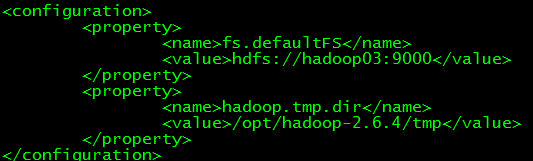
(3) hdfs-site.xml文件
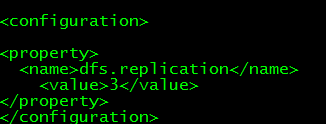
(4) mapred-site.xml 文件
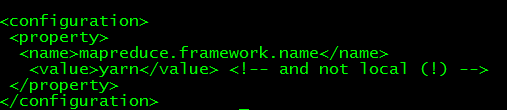
(5) yarn-site.xml
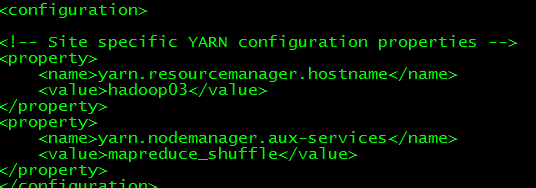
(6)slaves 文件

我们这里将hadoop03节点也作为了一个namenode节点。
在hadoop03上面配置完成之后,可以用scp命令将配置文件全部拷贝到hadoop01和hadoop02上面去。
7 hadoop集群测试
配置完成之后,首先格式化namenode,然后再sbin目录下启动hadoop,可以看到在hadoop03上的进程如下:
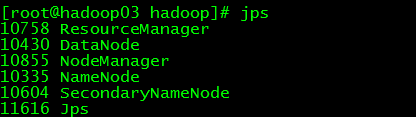
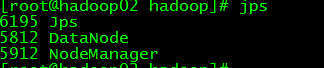
在hadoop01和hadoop02上面的进程如下
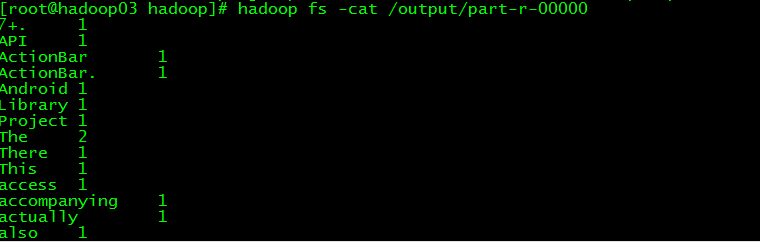
之后我们在HDFS上新建文件,利用hadoop自带的jar文件运行wordcount实例,运行结果如下:


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









