






 文章讲述了在使用pyspark进行分布式计算时,由于导入了pyspark.sql模块导致map方法报错的问题。问题在于sum函数被误解为SQL中的sum,从而在计算代价cost和更新质心过程中引发错误。作者指出了问题的原因并提供了可能的解决方案。
文章讲述了在使用pyspark进行分布式计算时,由于导入了pyspark.sql模块导致map方法报错的问题。问题在于sum函数被误解为SQL中的sum,从而在计算代价cost和更新质心过程中引发错误。作者指出了问题的原因并提供了可能的解决方案。
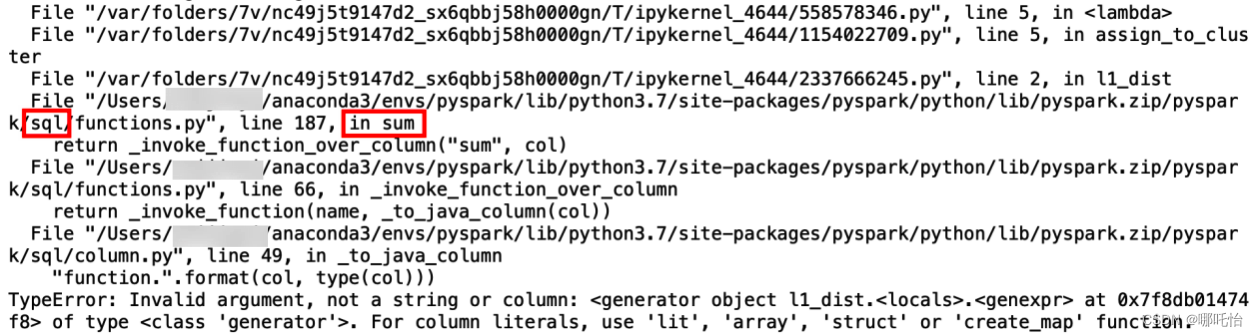
在运行分布式计算本轮迭代代价cost时,使用map方法出现如上报错,代码如下
for i in range(MAX_ITER):
# 输出结果(cluster, point, cost)
assignment = data.map(lambda point: assign_to_cluster(point, centroids, dist_fn))
# 计算本轮迭代代价cost
cost = assignment.map(lambda x: x[2])\
.reduce(lambda x, y: x + y)
print(f'iter {i}: cost is {cost}')
cost_seq.append(cost)
#计算新的质心
new_centroids = assignment.map(lambda x: (x[0], (x[1], 1)))\
.reduceByKey(lambda x, y: (x[0] + y[0], x[1] + y[1]))\
.mapValues(lambda x: x[0] /x[1])\
.map(lambda x: x[1])\
.collect()原因是我在前面导入了pyspark.sql模块,导致使用sum方法时用到sql模块中而不是正常的sum方法,出现报错
















 1029
1029

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









