







ps:今天发烧了,所以可能写的不清楚,见谅TAT
题目

分析:动态规划
首先,这道题一定不能用递归去写。今天执行程序,数值还好的话说不定明天就执行完了= =
首先我们来分析子串的性质,假设我们有两个字符串:
- babagbagba
- bag
让后者去匹配前者,可以分为这样的步骤:
从b开始,可以试着找出所有b的位置,然后找每一个b后面a的位置,然后再找每一个a后面g的位置,最后就可以数出所有的子序列
这种需要记录前面的情况来推出后面的情况的思路,一般都用动态规划来高效解决。
算法思路
(笔者在写代码的时候默认想成了从后往前推,实际上并不是一定要从后往前推,从前往后亦可)
首先创建一个祖传二维数组dp[m+1][n+1],
然后导入两个字符串s,t,其中s长度为m,t长度为n
dp[i][j]用来存储s字符串的子串s[i:m-1]中t的子串t[j:n-1]的匹配个数
解释:s[i:m-1]是指下标从i到m-1截获的子串,t同理
首先来处理特殊情况:
-
如果s长度比t小,必然没有匹配数
-
对于任意
dp[m][j],j∈[0,n-1],其表达的含义是:t[j:n-1]在空字符串中的匹配数
所以必然是0;
对于任意
dp[i][n],i∈[0,m],其表达的含义是:一个空字符串在s[i:m-1]中的匹配数
我们规定是1,其中,
dp[m][n]表示空字符串在空字符串中的匹配数,故为1
然后我们可以进行一般的递推了:
对于dp[i][j]的值,我们有以下推论:
-
若
s[i]==t[j],则表明dp的一部分是由dp[i+1][j+1]组成的(我们称之为来源1),另一部分是由dp[i+1][j]组成的(我们称之为来源2)举个例子:
现在有两个字符串:
- dogdog
- dog
令上面为s字符串,下面为t字符串,则其
dp[1][1]是2,因为:s : d
ogdog与 dogdogt : d
og那我现在因为
s[0]==t[0],所以 有:dogdog 、dogdog和dogdog三个匹配。然后呢,我们的来源2是一定会继承下来的,即下面这个匹配:
dog
dog这是字符串
s[1:5]= ogdog 中匹配t[0:2]= dog的个数,即dp[1][0]所以我们有
dp[0][0]=dp[1][1]+dp[1][0]即:
dp[i][j]=dp[i+1][j+1]+dp[i+1][j],s[i] == t[j] -
如果
s[i] != t[j],则我们失去了来源1,只有来源2这个继承下来的个数,即:
dp[i][j]=dp[i+1][j],s[i] != t[j]
所以我们就有了递推方程式:
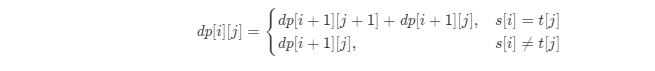
下面我们来看源码:
int numDistinct(string s, string t) {
int s_len = s.size();
int t_len = t.size();
if(s_len < t_len) return 0;
vector<vector<unsigned>> dp(s_len + 1, vector<unsigned>(t_len + 1));
for(int i = 0 ; i <= s_len ; i++)
dp[i][t_len] = 1;
for(int i = 0 ; i < t_len ; i++){
dp[s_len][i] = 0;
}
for(int i = s_len - 1 ; i >= 0 ; i --){
for(int j = t_len - 1 ; j >= 0 ; j --){
if(s[i] == t[j])
dp[i][j] = dp[i+1][j+1] + dp[i+1][j];
else
dp[i][j] = dp[i+1][j];
}
}
return dp[0][0];
}
非常的优美简洁(指相比于递归和栈hhh)














 3022
3022











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









