






1.Hive bugs归纳
| 工具 | 现象 | 对应bugs | 目前解决方案 | 详情 |
| hive3.1.2 | 内存只升不降,最终进程挂断 | 定时挂断自起
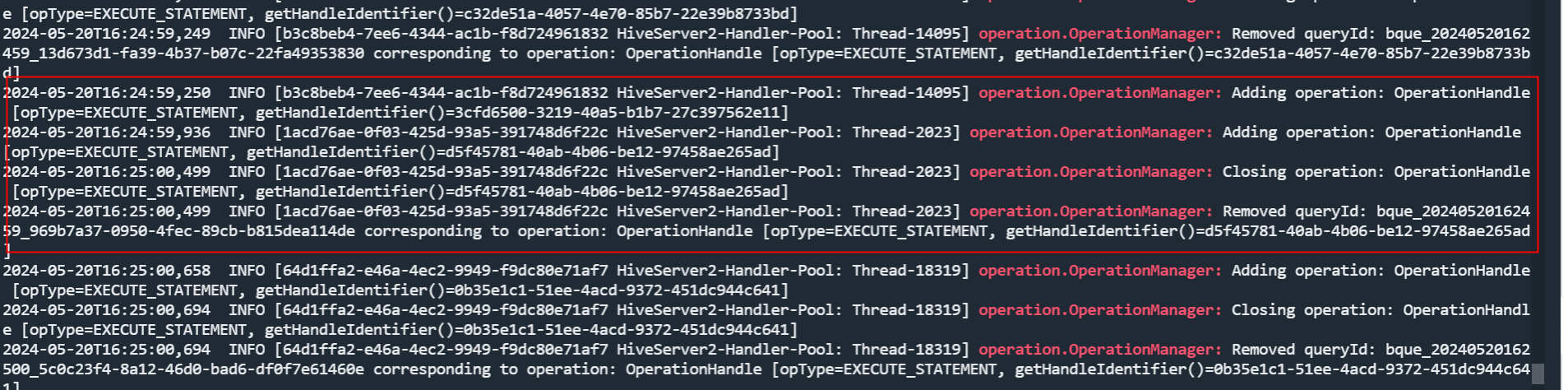
| operation.OperationManager的多个adding,只会remove最后一个 | |
| 多表join丢数据 | [HIVE-22098] Data loss occurs when multiple tables are join with different bucket_version - ASF JIRA | 手动增加临时表指定bucketVersion-》打补丁 | 三个表联接。第一个表中的table_a和第二个表中的table_b的临时结果数据连接结果记录为tmp_a_b,当它与第三个表连接时,hive-3.0.0后默认创建的表的 bucket_version=2,临时数据tmp_a_b初始化了 bucketVerison=-1,然后连接了 ReduceSinkOperator Verketison=-1。在 init 方法中,根据 bucketVersion 选择 join 列的哈希算法。如果 bucketVersion = 2 并且不是 acid 操作,则将获得新的哈希算法。否则,将获得哈希的旧算法。由于哈希算法的不一致,导致的数据分配分区不同。在Reducer阶段,具有相同键的数据无法配对,导致数据丢失。 | |
| dolphinscheduler2.0.6 | 传参偶发性失效 | '${bizdate}'->'${yyyyMMdd-1}' |
2.其他问题归纳
| 工具 | 现象 | 定位排查 | 原因及解决 | 详情 |
| zabbix | 临平集群报警slaver上的resourcemanager找不到 | 定位rm及集群运行正常 | zabbix监控是同一份脚本,由运维上传到了不同的机器上,所以有些机器上的进程并不存在,需要手动将这些监控关掉。 | |
| dolphinscheduler | ds调度时间延长 | 1、9点ds调度机器内存清空 | 由于美创传全量数据时h2内存泄漏带来机器压力,crontab -e 定时做了清理,重新调整 | |
| hadoop | 磁盘空间占用过大 | 临时表没有清理 | 可以配置hive启动时清理临时表,但启动会比较慢 | Hive作业在运行时会在HDFS的临时目录产生大量的数据文件,这些数据文件会占用大量的HDFS空间。这些文件夹用于存储每个查询的临时或中间数据集,并且会在查询完成时通常由Hive客户端清理。但是,如果Hive客户端异常终止,可能会导致Hive作业的临时或中间数据集无法清理,从而导致Hive作业临时目录占用大量的HDFS空间。本篇文章Fayson主要介绍如何解决清理Hive作业产生的临时文件。 |















 2451
2451

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









