







文章来源:https://blog.csdn.net/alxe_made/article/details/88594550
1. 扩张卷积的提出
- Multi-Scale Context Aggregation by Dilated Convolutions
- Dilated Residual Networks
- 论文笔记——CVPR 2017 Dilated Residual Networks
在图像分割领域,图像输入到CNN(典型的网络比如FCN)中,FCN先像传统的CNN那样对图像做卷积再pooling,降低图像尺寸的同时增大感受野,但是由于图像分割预测是pixel-wise的输出,所以要将pooling后较小的图像尺寸upsampling到原始的图像尺寸进行预测(upsampling一般采用deconv反卷积操作,之前的pooling操作使得每个pixel预测都能看到较大感受野信息。因此图像分割FCN中有两个关键,一个是pooling减小图像尺寸增大感受野,另一个是upsampling扩大图像尺寸。在先减小再增大尺寸的过程中,肯定有一些信息损失掉了,那么能不能设计一种新的操作,不通过pooling也能有较大的感受野看到更多的信息呢?答案就是dilated conv。
这里的话我们就主要介绍一下扩张卷积的理解,具体在图像分割或者语音合成、机器翻译应用暂时不做考虑。
2. 理解的难点

其实上来就给出这个图,确实有点不知所云,有几个问题需要我们回答:

3. 感受野
在理解上面这个公式之前,我们先理解一下感受野这个含义。
参考:
1.A guide to receptive field arithmetic for Convolutional Neural Networks
2.你知道如何计算CNN感受野吗?这里有一份详细指南
然后看完之后我们才可以进行下面的内容,我们截取其中重要的图进行说明:


4. 计算空洞卷积感受野
空洞卷积就是在传统的卷积中加入了一个dilation rate这个系数。可以从两个方面理解这个参数,从原图像层面理解:就是我们对原图以(dilation rate-1)进行间隔采样;从卷积核自身的角度来看,我们相当于在未使用空洞卷积的卷积核中,在其内部插入(dilation rate-1)个0,可以理解为使用空洞卷积之后我们卷积核的尺寸变大了。后面的公式推导中,我们按照后面一种理解进行讲述。
下图是空洞卷积的动态示意图:
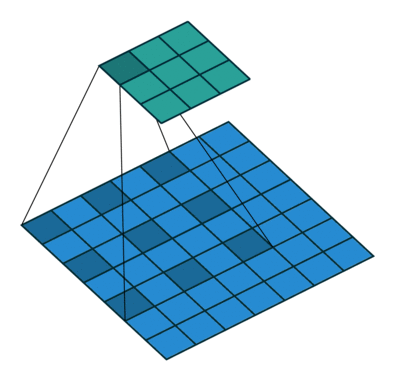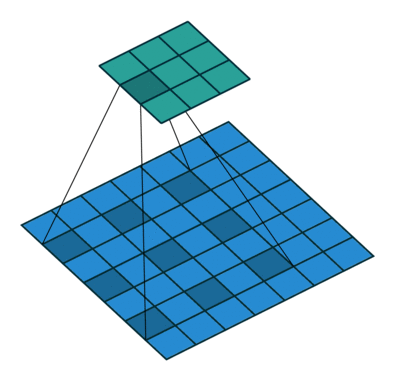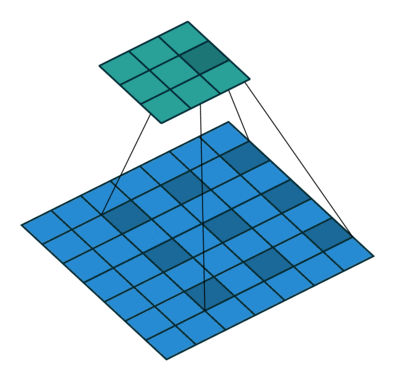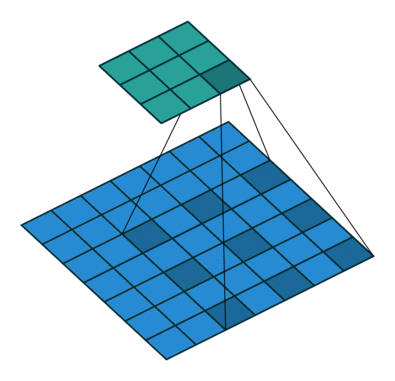
Dilated Convolution with a 3 x 3 kernel and dilation rate 2
4.1 从一个简单的一维例子出发
为了更好理解空洞卷积,我们从一维入手:

a: 卷积核大小是3,然后移动的步长是2,padding是1
b: 卷积核大小是3,移动的步长是1,padding是1
c.卷积核大小是3,移动的步长是1,dilation rate是2
然后我们着重对比b和c两张图,考虑亮黄色的神经元,我们在b中视野(感受野)只有2-4,也就是只有3;在c图中我们的视野变成了1-5,也就是感受野变成了5,增加了感受野了。那么为什么感受野变成了5?
我们可以这样理解,从b到c图,我们仅仅是使用了空洞卷积,按照上面对空洞卷积第二层理解也就是从卷积核的角度出发,我们相当于在kernel size内部每隔一个卷积核插入(dilation rate - 1)个0,共插入(kernel-1)次。再加上原始的卷积核的感受野,可以这样计算:
kernel_size_after_dilate = (dilate rate -1) * (kernel_size_before_dilate - 1) + kernel_size_before_dilate
这里是dilation rate是2,kernel_size_before_dilate=3。因此我们的kernel_size_after_dilate感受野为:(2-1)*(3-1)+3 = 5。 这里第一个3代表的原始的感受野,也就是kernel size大小,这里是3。
4.2 一个稍微复杂的例子


5. 最初的四个问题
在第二小节中我们提出了四个问题,现在我们可以尝试回答一下:
- 红点代表什么意思?代表的是感受野的中心~
- 为什么扩张卷积导致图像尺寸不变?
从4.1那个一维的例子出发我们可以直观的理解,空洞卷积只是可以以指数形式提高网络的感受野,但是不改变图像输出的特征图。特征图的计算可以依据:

3.图中最外层图像的代表什么?
代表的就是感受野的大小
![]()
其实这个公式自己并不是特别理解,也不是特别好用,感觉不具有一般性。
下面是关于多尺度的一些理解:
个人理解,理解多尺度首先理解尺度空间,我们的尺度空间是分辨率是相同的,然后使用不同的高斯核(传统反向);从直觉上说,这个多尺度是模仿人类的视网膜的特征,不同的距离看的物体模糊是不同的,离我们越远,然后越模糊,从而我们看到全局信息;离我们越近的话,我们看的越清楚,然后看到的是局部信息。从cnn网络来看我们使用不同的conv层,(缩放到同一尺寸下面)。越深的卷积层提取出的特征图越抽象,提取到的特征更高级。所以这个就相当于是一种不同的尺度下的特征(分辨率一致)这么理解的。而多和多尺度相对应的是多分辨率,他的分辨率不是不变的,常见的是图像金字塔,它的分辨率是逐渐缩小的
7. Tensorflow和Pytorch使用空洞卷积
7.1 Tensorflow
tf.nn.atrous_conv2d()参考:
7.2 Pytorch
参考文章:














 388
388











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









