







前言
上一次我们搭建了基于Docker的伪分布式Hadoop集群,这次来搭建分布式的
一、为集群单独构建虚拟网络
现在的 Docker 网络能够提供 DNS 解析功能,我们可以使用如下命令为接下来的 Hadoop 集群单独构建一个虚拟的网络:
sudo docker network create --driver=bridge hadoop
使用下面这个命令查看 Docker 中的网络,可以看到刚刚创建的名为 hadoop 的虚拟桥接网络:
sudo docker network ls

二、进入上次搭建好的容器
我们通过上次制作的镜像启动一个容器:
docker run -dit --name=master --hostname=master hdp
我们进入master容器中
docker exec -it master /bin/bash
三、配置Hadoop环境
在上一次我们已经配置了一个伪分布式的Hadoop环境,接下来我们需要对那些文件再进一步修改。
1.修改core-site.xml
打开/usr/local/hadoop-3.3.1/etc/hadoop路径下的core-site.xml:
cd /usr/local/hadoop-3.3.1
cd etc/hadoop
vim core-site.xml
修改后是这样的:
<configuration>
<!--指定nameNode的地址-->
<property>
<name>fs.defaultFS</name>
<value>hdfs://master:8020</value>
</property>
<!--指定Hadoop数据的存储目录-->
<property>
<name>hadoop.tmp.dir</name>
<value>/usr/local/hadoop/data</value>
</property>
<!--配置HDFS网页登陆使用的静态用户,配置这个之后才有权限可以在网页端删除文件、文件夹-->
<property>
<name>hadoop.http.staticuser.user</name>
<value>root</value>
</property>
</configuration>
2.修改hdfs-site.xml
vim hdfs-site.xml
修改后:
<configuration>
<!--文件的存储个数-->
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<!--nn web端访问地址,使用网页访问HDFS文件系统就是这个端口-->
<property>
<name>dfs.namenode.http-address</name>
<value>master:9870</value>
</property>
<!--2nn web端访问地址-->
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>master:9868</value>
</property>
<!--网页查看HDFS文件内容,出现Couldn‘t preview the file报错,需要配置的参数-->
<property>
<name>dfs.webhdfs.enabled</name>
<value>true</value>
</property>
</configuration>
3.修改mapred-site.xml
vim mapred-site.xml
修改后:
<configuration>
<!--指定MapReduce程序运行在Yarn上-->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
4.修改yarn-site.xml
vim yarn-site.xml
修改后:
<configuration>
<!--指定MR走 shuffle-->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!--指定ResourceManager的地址-->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>h01</value>
</property>
<!--环境变量的继承-->
<property>
<name>yarn.nodemanager.env-whitelist</name>
<value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOME</value>
</property>
</configuration>
5.修改workers
vim workers
修改后:
master
slave1
slave2
注意:master这些后面不要有空格!slave2后面,不要有空的行!自己准备起多少集群,就在这里写几个,要是准备起5个集群,就写到slave4。
四、在Docker中启动集群
1.先将容器导出为镜像
docker commit master nethdp
2.启动三个终端
-
第一条命令启动的是
master做master节点的,所以要开放一些端口,用来访问web页面docker run -dit --network hadoop --hostname=master --name=master -p 9870:9870 -p 8088:8088 nethdp /bin/bash -
后面几条命令都类似,只要注意修改名字和主机名就行
docker run -dit --network hadoop -hostname=slave1 --name=slave1 nethdp /bin/bash -
第三条命令
docker run -dit --network hadoop -hostname=slave2 --name=slave2 nethdp /bin/bash
3.接下来在master主机中启动Hadoop集群
先在hadoop安装目录进行格式化操作,不格式化操作,hdfs起不来(只有第一次启动的时候需要初始化,以后启动就不需要了,先删除所有机器的 data和logs目录,然后再进行格式化):
./bin/hdfs namenode -format

然后启动HDFS集群:
./sbin/start-dfs.sh

最后,启动yarn集群管理节点:
./sbin/start-yarn.sh
都启动完成后,使用 jps 命令查看:
jps

可以看到,除了Jps,一共有5个进程,因为这里没有将 nameNode、ResourceManager、SecondaryNameNode分开部署,所以都在 h01这一台机器上,实际生产中,应该是需要分开部署的。
至此,Hadoop 集群已经构建好了。
五、网页访问
1.浏览器访问本机的9870端口

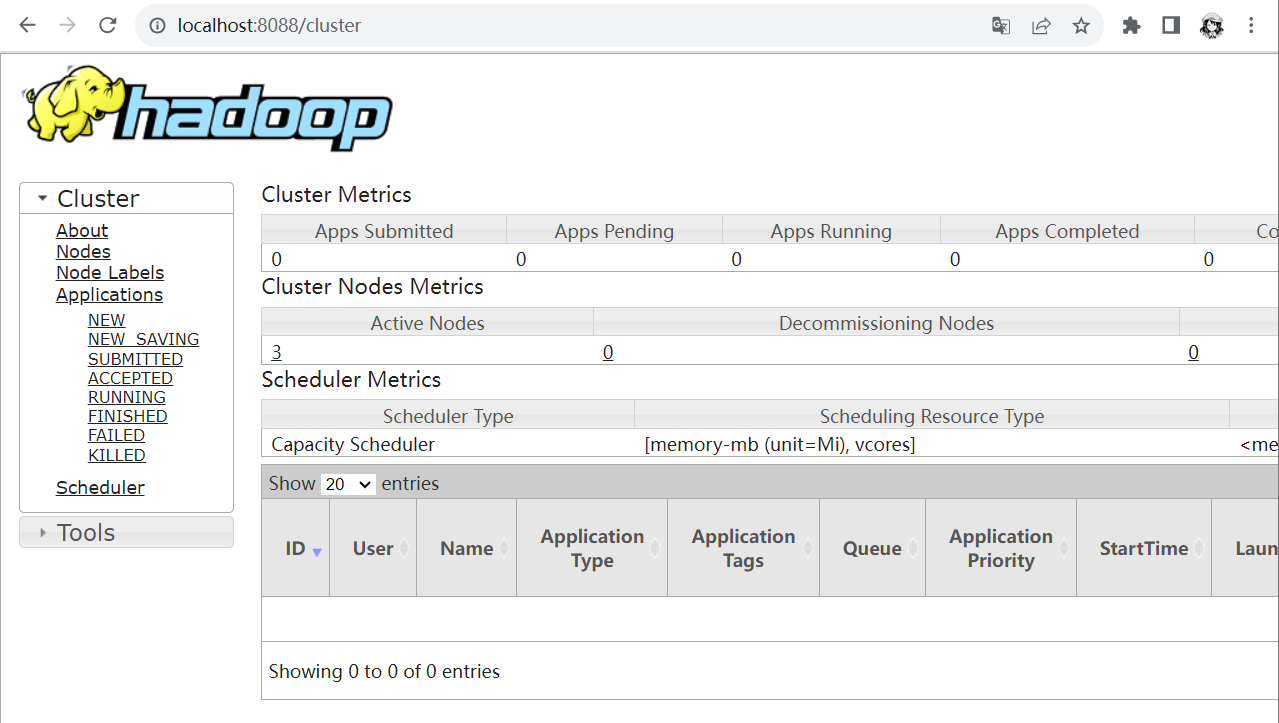
2.浏览器访问本机的8088端口
参考:















 1621
1621











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









