



 文章讲述了在集成Kafka客户端后,线上出现大量RetriableCommitFailedException异常,集中在灰度环境中。通过流量检查、Broker负载分析和日志排查未找到明显原因。在无法复现问题和怀疑网络环境后,分析了异常的重试机制,发现同步提交和异步提交的差异可能导致问题。最终,通过将灰度实例的提交方式改为同步可重试解决异常,避免了位移覆盖和重复消费的问题。
文章讲述了在集成Kafka客户端后,线上出现大量RetriableCommitFailedException异常,集中在灰度环境中。通过流量检查、Broker负载分析和日志排查未找到明显原因。在无法复现问题和怀疑网络环境后,分析了异常的重试机制,发现同步提交和异步提交的差异可能导致问题。最终,通过将灰度实例的提交方式改为同步可重试解决异常,避免了位移覆盖和重复消费的问题。
之前线上发生了一个很诡异的异常,网上各种搜索、排查,都没有找到问题,给大家分享一下。
大概在 2 月份的时候,我们的某个应用整合了中间件的 kafka 客户端,发布到灰度和蓝节点进行观察,然后就发现线上某个 Topic 发生了大量的RetriableCommitException,并且集中在灰度机器上。
E20:21:59.770 RuntimeException org.apache.kafka.clients.consumer.RetriableCommitFailedException ERROR [Consumer clientId=xx-xx.4-0, groupId=xx-xx-consumer_[gray]] Offset commit with offsets {xx-xx-xx-callback-1=OffsetAndMetadata{offset=181894918, leaderEpoch=4, metadata=''}, xx-xx-xx-callback-0=OffsetAndMetadata{offset=181909228, leaderEpoch=5, metadata=''}} failed org.apache.kafka.clients.consumer.RetriableCommitFailedException: Offset commit failed with a retriable exception. You should retry committing the latest consumed offsets.
Caused by: org.apache.kafka.common.errors.TimeoutException: Failed to send request after 30000 ms.
复制代码
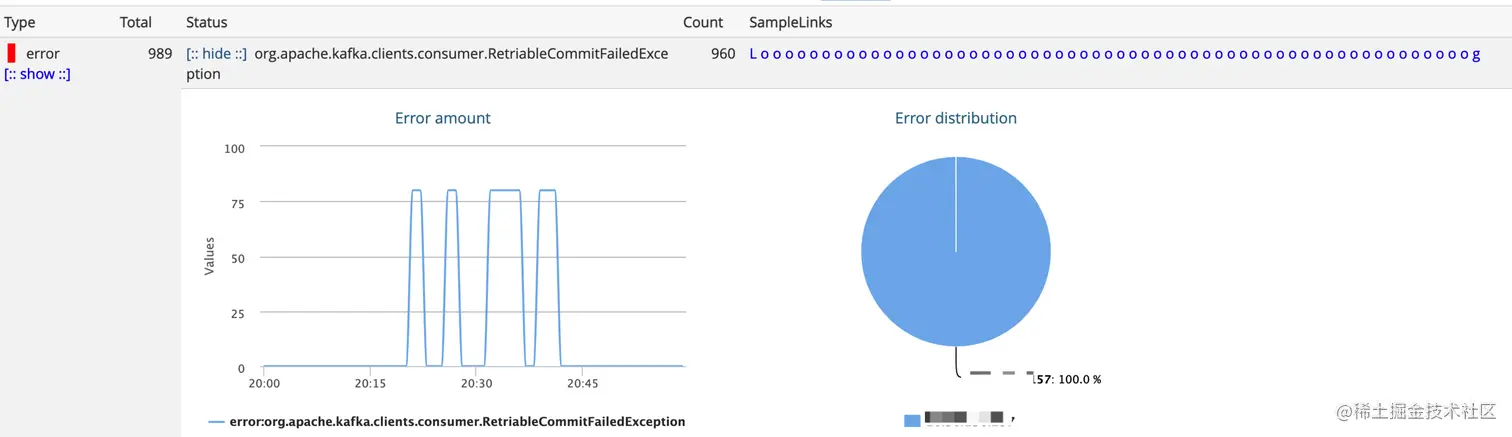
排查
检查了这个 Topic 的流量流入、流出情况,发现并不是很高,至少和 QA 环境的压测流量对比,连零头都没有达到。
但是从发生异常的这个 Topic 的历史流量来看的话,发生问题的那几个时间点的流量又确实比平时高出了很多。
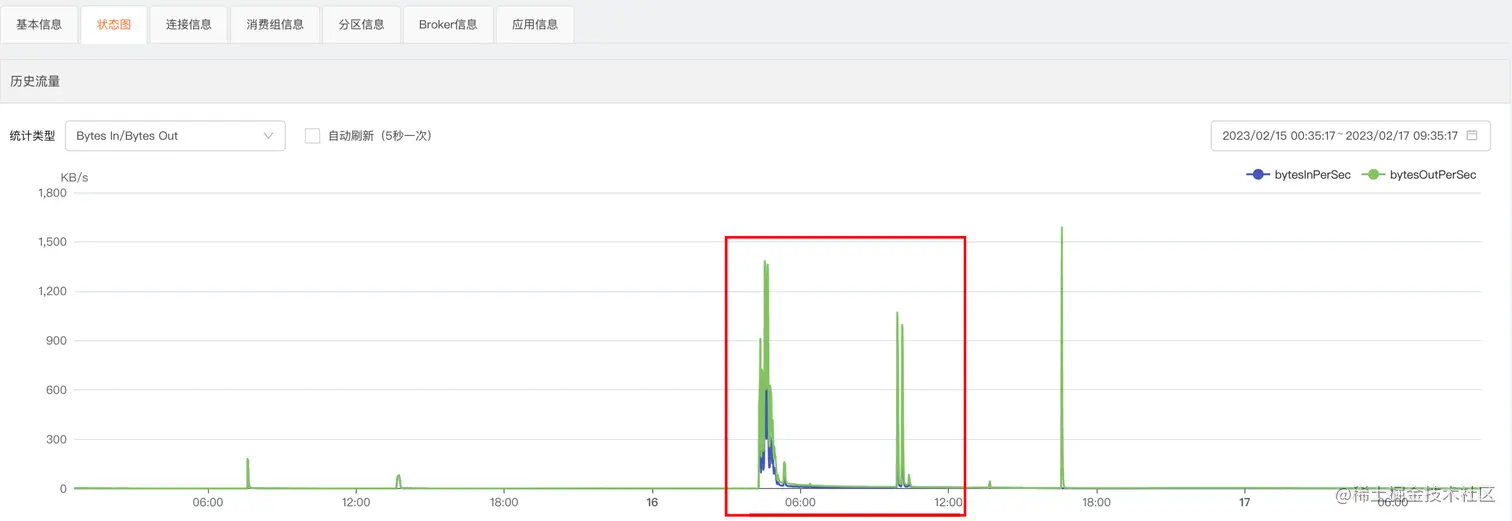
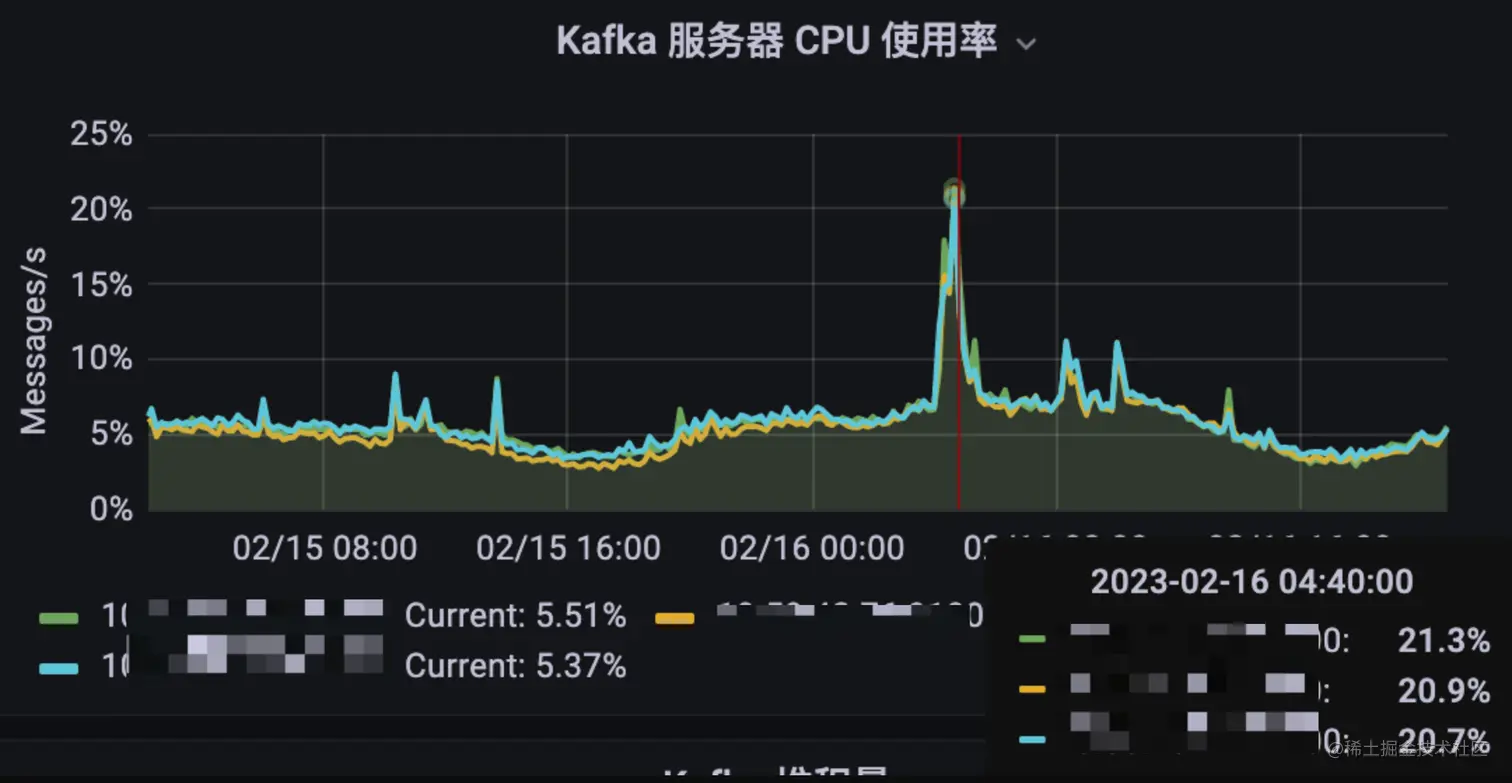
同时我们检查 Broker 集群的负载情况,发现那几个时间点的 CPU 负载也比平时也高出很多(也只是比平时高,整体并不算高)。
对Broker集群的日志排查,也没发现什么特殊的地方。
然后我们对这个应用在QA上进行了模拟,尝试复现,遗憾的是,尽管我们在QA上把生产流量放大到很多倍并尝试了多次,问题还是没能出现。
此时,我们把问题归于当时的网络环境,这个结论在当时其实是站不住脚的,如果那个时刻网络环境发生了抖动的话,其它应用为什么没有这类异常?
可能其它的服务实例网络情况是好的,只是发生问题的这个灰实例网络发生了问题。
那问题又来了,为什么这个实例的其它 Topic 没有报出异常,偏偏问题只出现在这个 Topic 呢?。。。。。。。。。
至此,陷入了僵局,无从下手的感觉。
从这个客户端的开发、测试到压测,如果有 bug 的话,不可能躲过前面那么多环节,偏偏爆发在了生产环境。
没办法了,我们再次进行了一次灰度发布,如果过了一夜没有事情发生,我们就把问题划分到环境问题,如果再次出现问题的话,那就只能把问题划分到我们实现的 Kafka 客户端的问题了。
果不其然,发布后的第二天凌晨1点多,又出现了大量的 RetriableCommitFailedException,只是这次换了个 Topic,并且异常的原因又多出了其它Caused by 。
org.apache.kafka.clients.consumer.RetriableCommitFailedException: Offset commit failed with a retriable exception. You should retry committing the latest consumed offsets.
Caused by: org.apache.kafka.common.errors.DisconnectException
...
...
E16:23:31.640 RuntimeException org.apache.kafka.clients.consumer.RetriableCommitFailedException ERROR
...
...
org.apache.kafka.clients.consumer.RetriableCommitFailedException: Offset commit failed with a retriable exception. You should retry committing the latest consumed offsets.
Caused by: org.apache.kafka.common.errors.TimeoutException: The request timed out.
复制代码
分析
这次出现的异常与之前异常的不同之处在于:
- 1. Topic 变了
- 2. 异常Cause变了
而与之前异常又有相同之处:
- 1. 只发生在灰度消费者组
- 2. 都是
RetriableCommitFailedException
RetriableCommitFailedException 意思很明确了,可以重试提交的异常,网上搜了一圈后仅发现StackOverFlow上有一问题描述和我们的现象相似度很高,遗憾的是没人回复这个问题:StackOverFlow。
我们看下 RetriableCommitFailedException 这个异常和产生这个异常的调用层级关系。
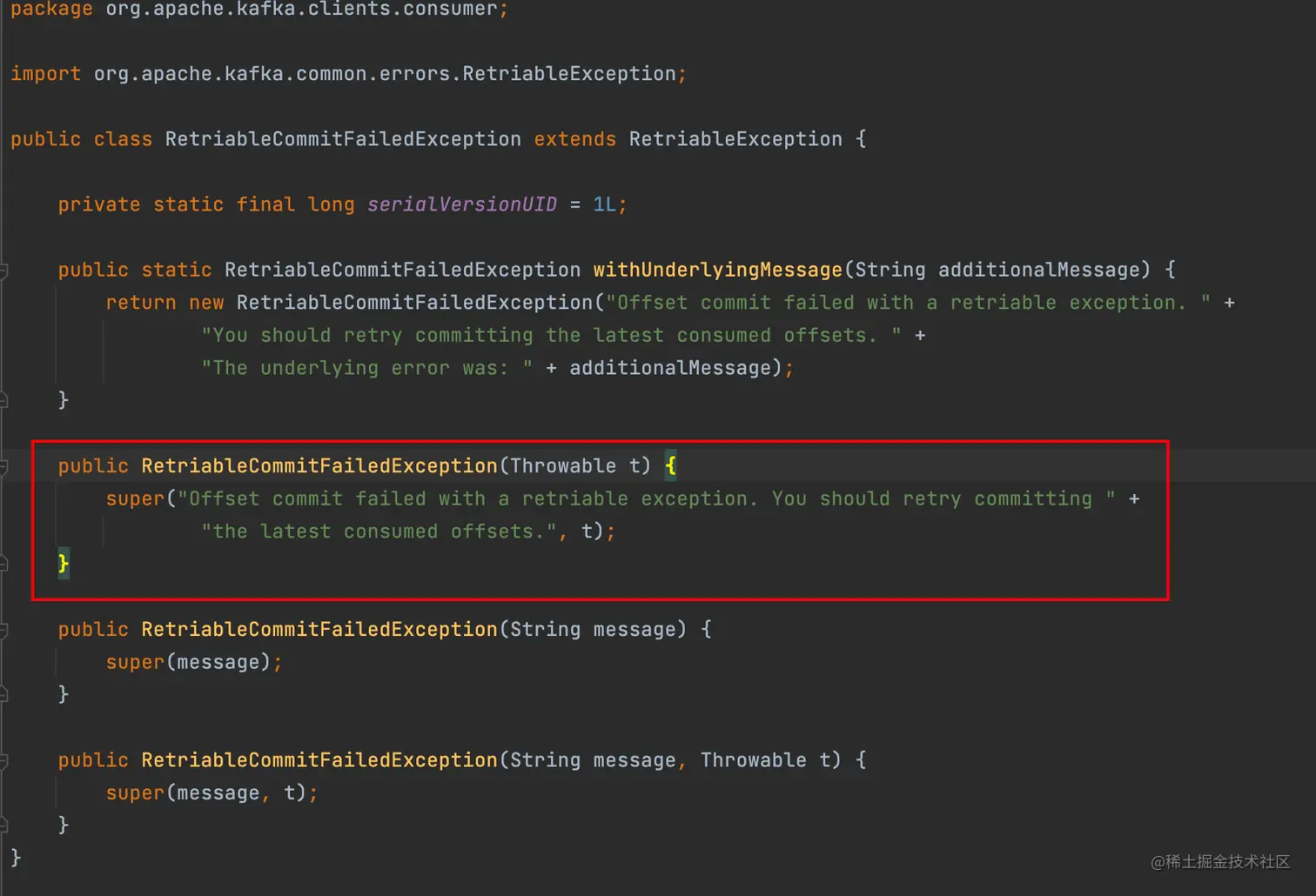
除了产生异常的具体 Cause 不同,剩下的都是让我们再 retry,You should retry Commiting the lastest consumed offsets。
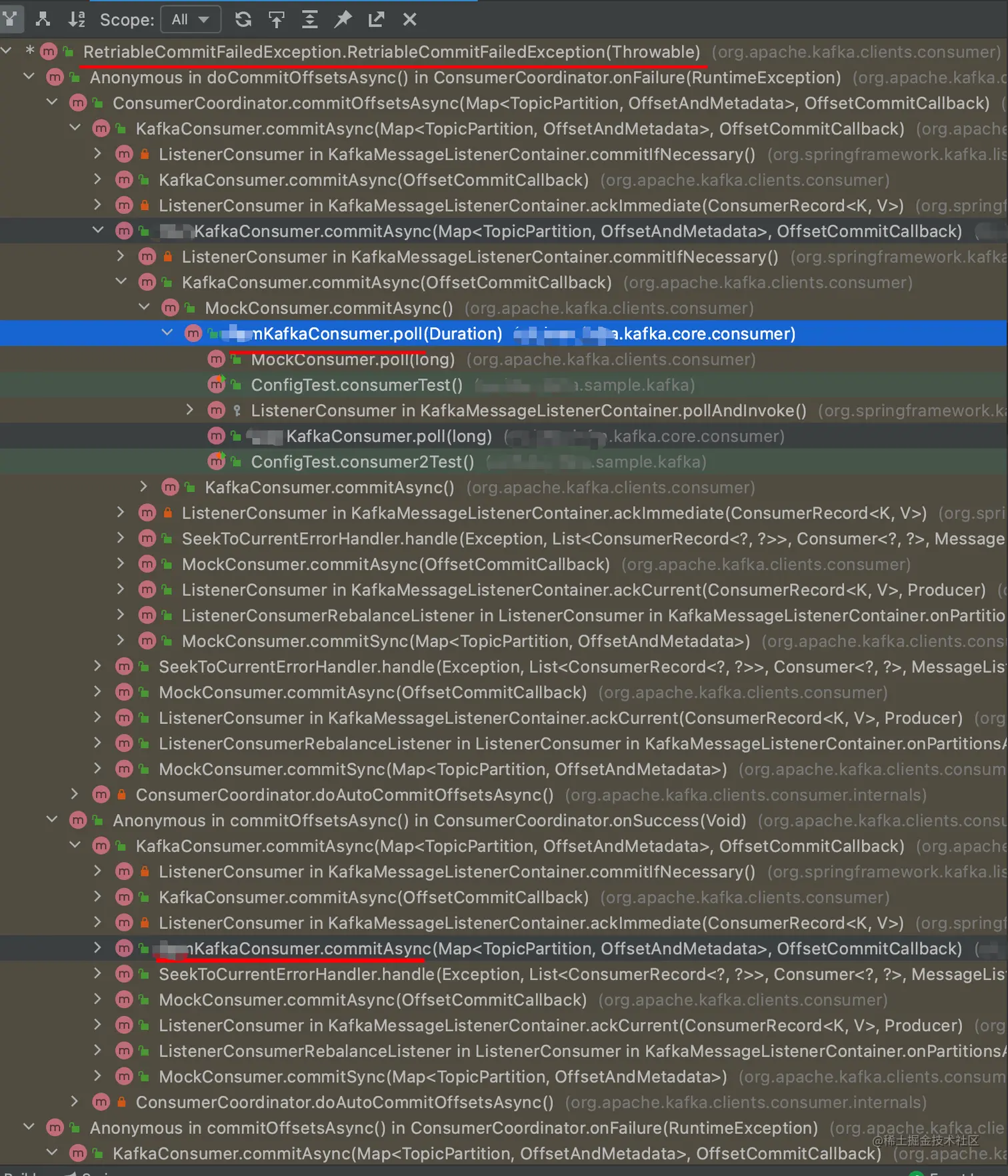
从调用层级上来看,我们可以得到几个关键的信息,commit 、 async。
再结合异常发生的实例,我们可以得到有用关键信息: 灰度、commit 、async。
在灰度消息的实现上,我们确实存在着管理位移和手动提交的实现。
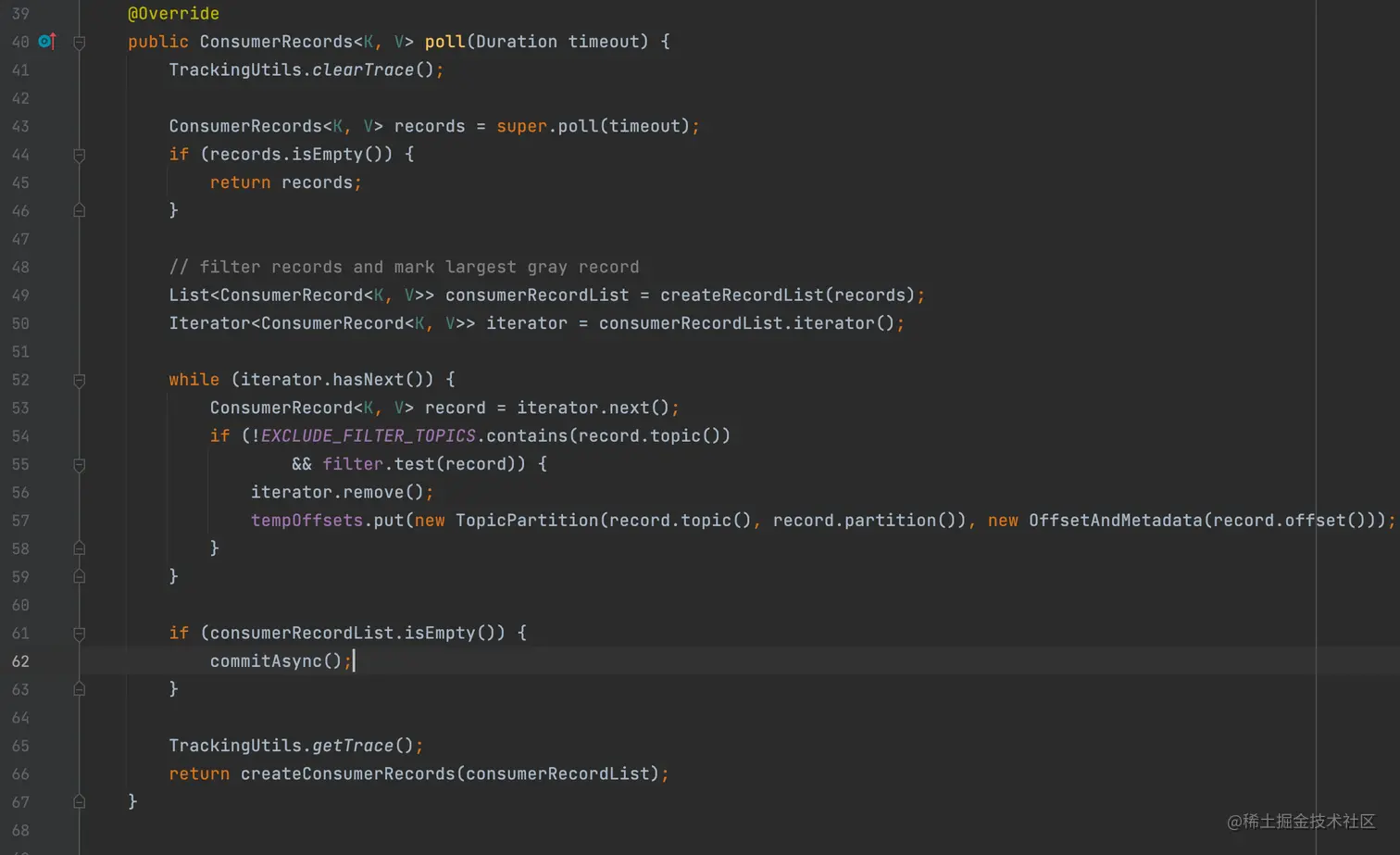
看代码的第 62 行,如果当前批次消息经过 filter 的过滤后一条消息都不符合当前实例消费,那么我们就把当前批次进行手动异步提交位移。结合我们在生产的实际情况,在灰度实例上我们确实会把所有的消息都过滤掉,并异步提交位移。
为什么我们封装的客户端提交就会报大量的报错,而使用 spring-kafka 的没有呢?
我们看下Spring对提交位移这块的核心实现逻辑。
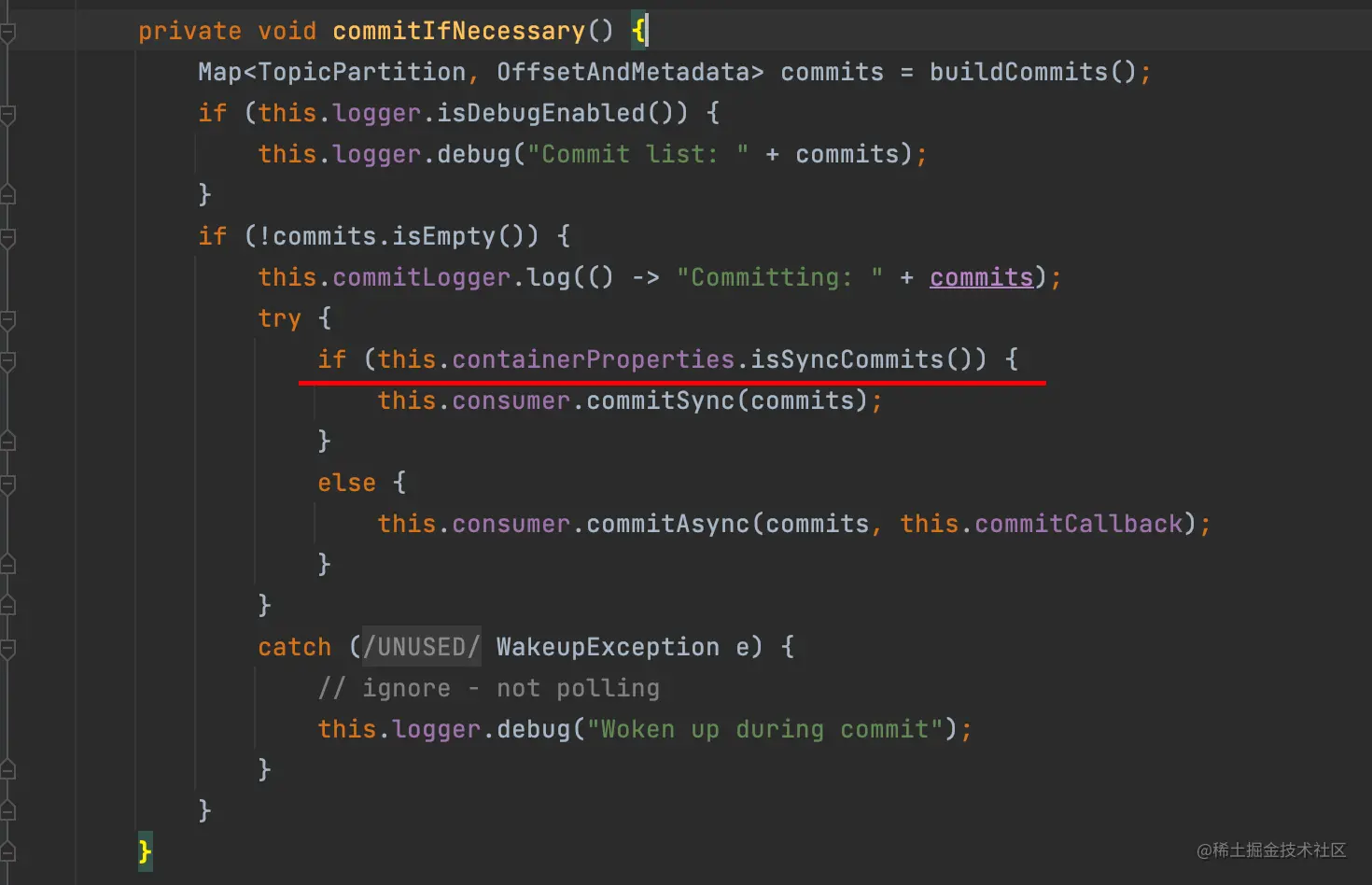
可以同步,也可以异步提交,具体那种提交方式就要看 this.containerProperties.isSyncCommits() 这个属性的配置了,然而我们一般也不会去配置这个东西,大部分都是在使用默认配置。

人家默认使用的是同步提交方式,而我们使用的是异步方式。
同步提交和异步提交有什么区别么?
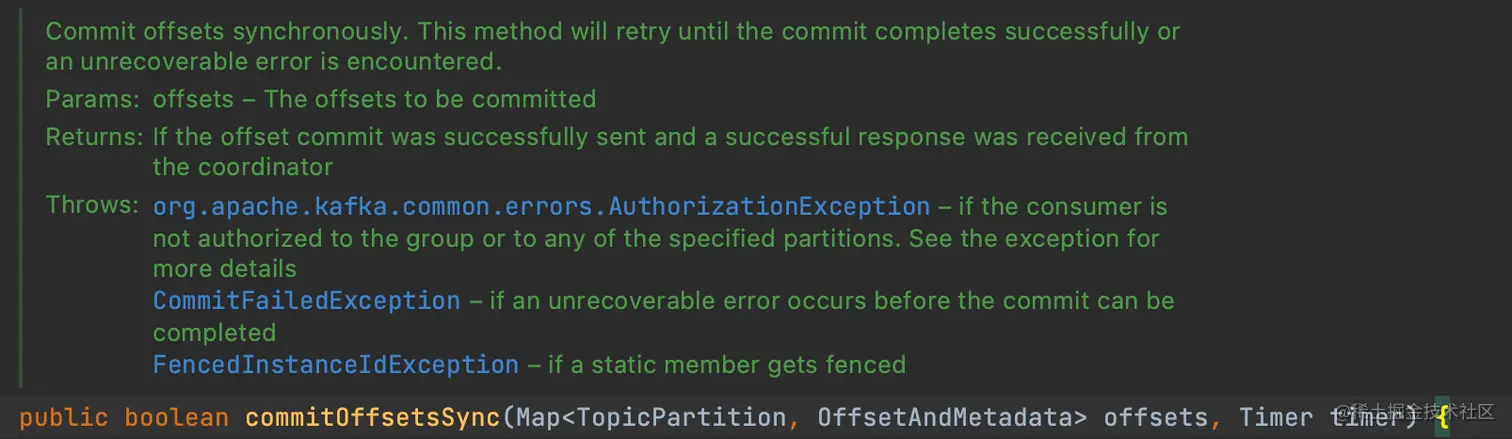
先看下同步提交的实现:
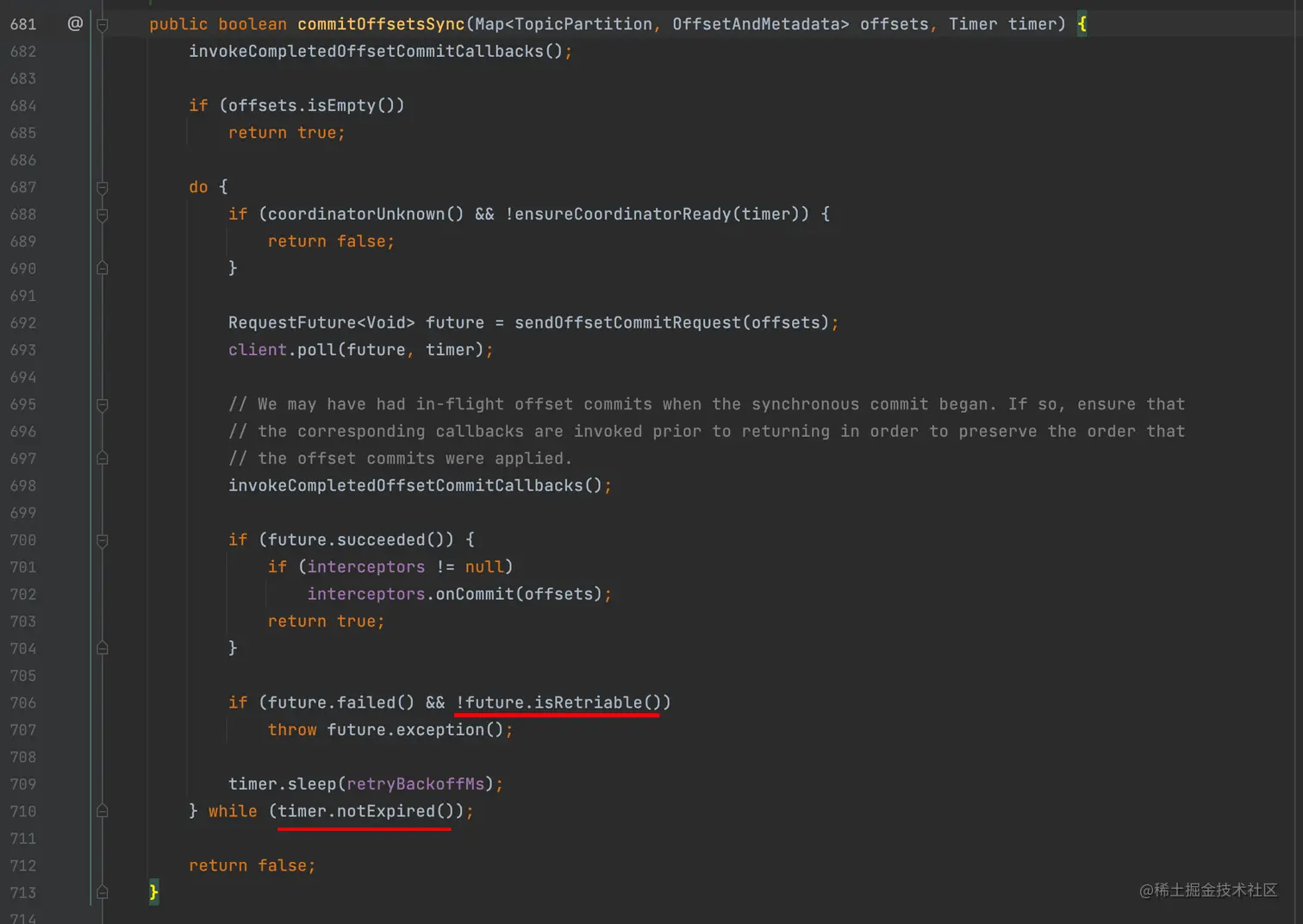
只要遇到了不是不可恢复的异常外,在 timer 参数过期时间范围内重试到成功(这个方法的描述感觉不是很严谨的样子)。
我们在看下异步提交方式的核心实现:
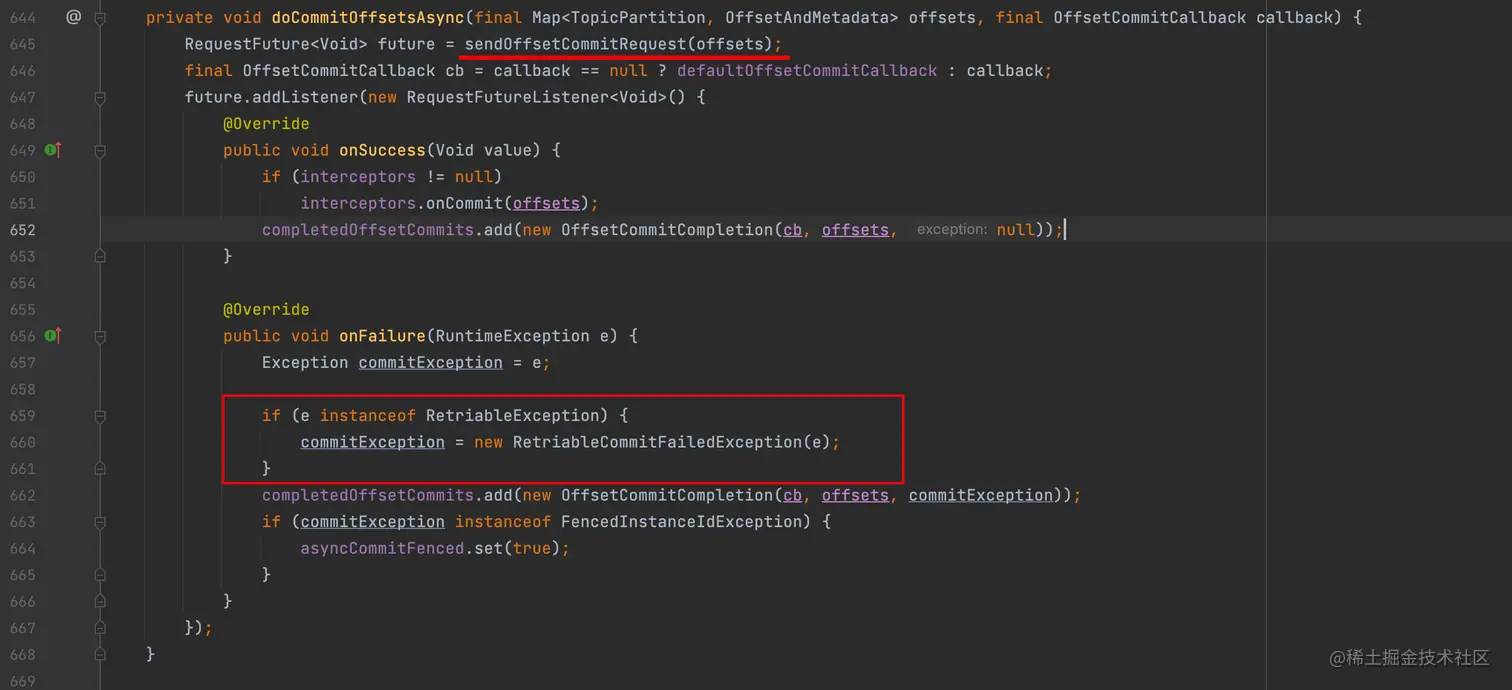
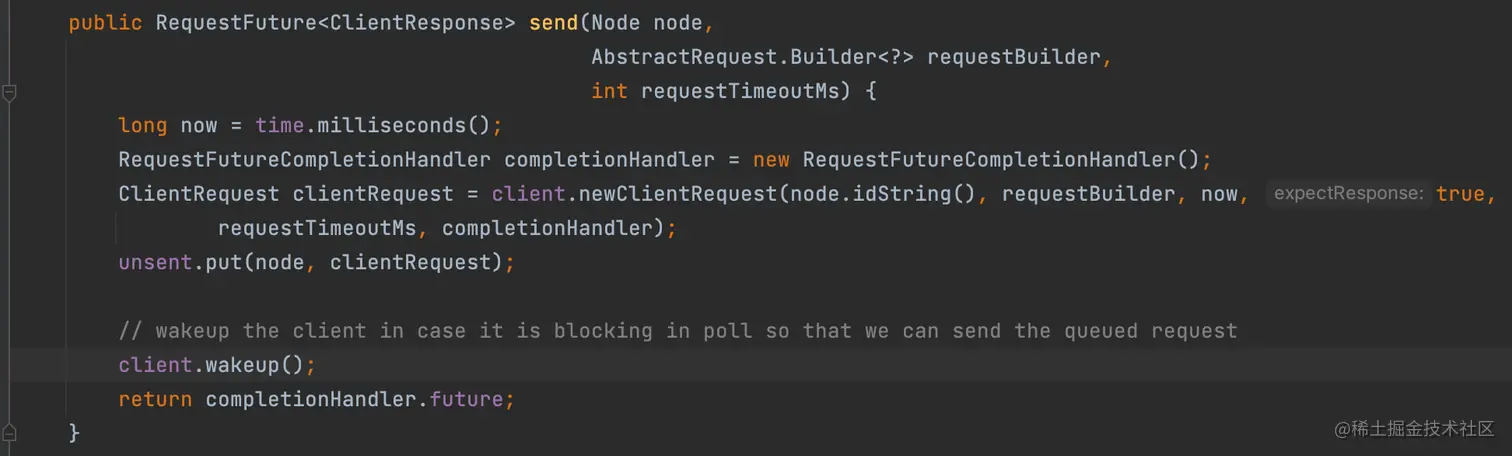
我们不要被第 645 行的 RequestFuture future = sendOffsetCommitRequest(offsets) 所迷惑,它其实并不是发送位移提交的请求,它内部只是把当前请求包装好,放到 private final UnsentRequests unsent = new UnsentRequests(); 这个属性中,同时唤醒真正的发送线程来发送的。
这里不是重点,重点是如果我们的异步提交发生了异常,它只是简单的使用 RetriableCommitFailedException 给我们包装了一层。
重试呢?为什么异步发送产生了可重试异常它不给我们自动重试?
如果我们对多个异步提交进行重试的话,很大可能会导致位移覆盖,从而引发重复消费的问题。
正好,我们遇到的所有异常都是 RetriableCommitException 类型的,也就是说,我们把灰度位移提交的方式修改成同步可重试的提交方式,就可以解决我们遇到的问题了。

















 370
370

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









