








1.什么是Ray
分布式计算框架大家一定都耳熟能详,诸如离线计算的Hadoop(map-reduce),spark, 流式计算的strom,Flink等。相对而言,这些计算框架都依赖于其他大数据组件,安装部署也相对复杂。
在python中,之前有分享过的Celery可以提供分布式的计算。今天和大家分享另外一个开源的分布式计算框架Ray。Ray是UC Berkeley RISELab新推出的高性能分布式执行框架,具有比Spark更优异的计算性能,而且部署和改造更简单,同时支持机器学习和深度学习的分布式训练,支持主流的深度学习框架(pytorch,tensorflow,keras等)

https://github.com/ray-project/ray
2. Ray架构
Ray的架构参见最早发布的论文Ray: A Distributed Framework for Emerging AI Applications
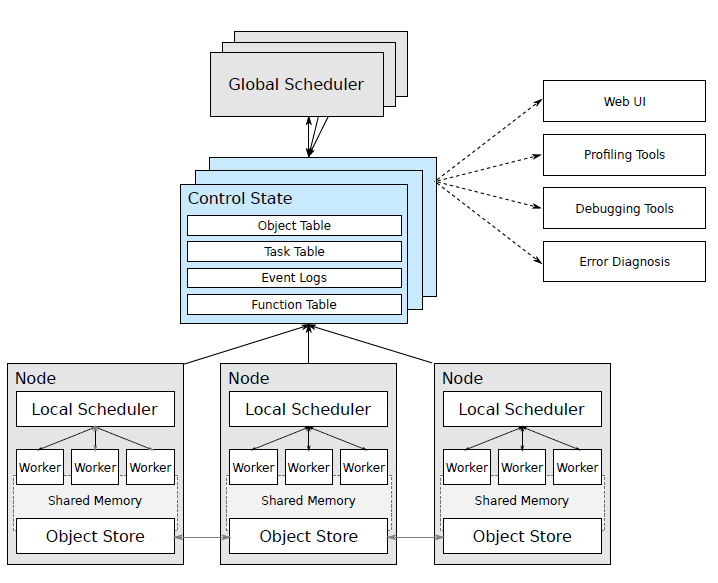
由上图可以Ray主要包括:
Node: 节点,主要是head和worker, head可以认为是Master,worker是执行任务的单元
-
每个节点都有自己的本地调度器local scheduler
object store:一个内存对象存储,允许Node之间进行通信
scheduler:有两个调度器,每个节点都有本地的调度器, 在提交任务时,Local Scheduler会判断是否需要提交给Global Scheduler分发给其他worker来执行。
GCS:全局状态控制记录了Ray中各种对象的状态信息,可以认为是meta数据,是Ray容错的保证
Ray适用于任何分布式计算的任务,包括分布式训练。笔者最近是用在大量的时间序列预测模型训练和在线预测上。
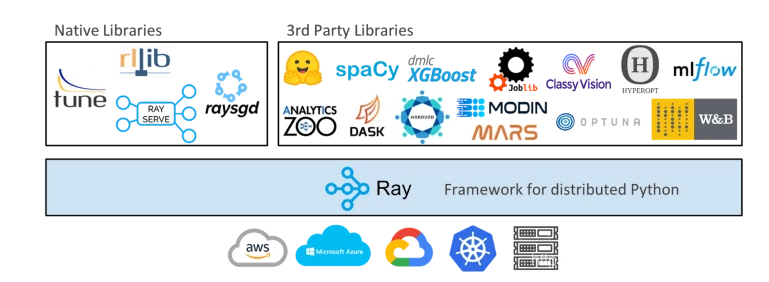
Ray目前库支持超参数调优Ray tune, 梯度下降Ray SGD,推理服务RaySERVE, 分布式数据Dataset以及分布式增强学习RLlib。还有其他第三方库,如下所示:
3. 简单使用
3.1 安装部署
pip install --upgrade pip
# pip install ray
pip install ray == 1.6.0
# ImportError: cannot import name 'deep_mapping'  最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 931
931











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









