






Java.io知识点梳理
如果要进行所有的文件以及文件内容的开发操作,应该使用java.io包完成,而在java.io包里面一共有五个核心类和一个核心接口:
- 五个核心类:File、InputStream、OutputStream、Reader、Writer
- 一个核心接口:Serializable
File类
在整个java.io包里面,File类是唯一一个与文件本身操作有关的类 ,但是不涉及到文件的具体内容,所谓的文件本身,指的是文件的创建和删除等。
几个重点掌握方法:
1.构造方法:public File(String pathname) 设置文件路径
2.普通方法:public boolean delete(); 删除文件
3.普通方法:public boolean exists()判断文件是否存在
4.普通方法:public File getParentFile();public String getParentFile();得找到父路径
5.普通方法:public Boolean mkdirs() 创建多级子目录
6普通方法:.public long length() 取得文件大小,按照字节大小返回;
例:创建目录及文件
import java.io.File;
public class TestFile02 {
public static void main(String[] args) throws Exception{
File file = new File("g:"+File.separator+"demo"+File.separator+"next"+File.separator+"test.txt");//设置路径
System.out.println(file.getParent());//g:\demo\next
if(!(file.getParentFile().exists())) {//如果父路径不存在
file.getParentFile().mkdirs();//如果nex不存在,就创建next
}
if(file.exists()) {
System.out.println("删除成功"+file.delete());
}else {
System.out.println(file.createNewFile());
}
}
}
注意:1.为什么不使用"\\"(表示转义成\)或者“\”?
1.在Windows系统里面支持的是“\”路径分隔,Linux(部署项目)下使用的是“/”路径分隔符;
解决:在File类里面提供有一个常量:public static final String separator(特殊,一般为大写的常量)
2.为什么创建文件时会有延迟?
在进行java.io操作的过程中,出现延迟情况,是因为java程序是通过JVM间接调用操作系统的文件处理函数进行文件处理操作(它不能直接操作文件),所以中间出现延迟。
字节流OutputStream
OutputStream类是一个专门进行字节数据输出的一个类,这个类定义如下
public abstract class OutputStream extends Object
implements Closeable, Flushable //实现了两个接口
public interface Closeable extends AutuCloseable
public interface AutuCloseable
了解一下它实现的两个接口Closeable和Flushable
在JDK1.7的时候引入了一个非常神奇的自动关闭机制,所以让Closeable又多继承了一个AutoCloseable接口,但是OutputStream类在JDk1.0的时候就提供有close()、和flush()两个操作方法,所以以上的两个接口就几乎可以忽略了。
使用OutputStream输出文件内容
OutputStream本身是属于抽象类,如果想要为抽象类进行对象的实例化操作,那么一定要使用抽象类子类,而本身要进行的是对文件的操作,所以可以使用FileOutStream子类。
在FileOutStream子类里定义的构造方法:public FileOutputStream(File file)
创建文件输出流以写入由指定的 File对象表示的文件。
在OutputStream类提供有三个输出方法:

**例:**输出字节数组
public static void main(String[] args) throws Exception {
//1.定义输出文件的路径 (资源访问到处都是异常)
File file =new File("G:"+File.separator+"demo1"+File.separator+"OutpS.text");
//1.此时由于目录不存在,所以文件不能输出,那么得创建目录
if(!file.getParentFile().exists()) {
file.getParentFile().mkdirs();
}
//2.使用OUtputStream和其子类进行对象实例化
//2.此目录存在,文件不存在,利用其构造(File file)生成文件
OutputStream output =new FileOutputStream(file,true);
//3.要进行文件内容的输出,并将字符串变为字节数组
String str ="你好,HelloWorld\r\n";
byte data[]=str.getBytes();
//4.将内容输出
output.write(data);
//资源操作的最后一步一定要进行关闭
output.close();
}
以上对内容进行了输出,并且如果此时要输出的文件不存在,那么将自动进行创建。
**例:**出指定位置(开始),指定长度,字节
public class TestOutpS03 {
public static void main(String[] args) throws Exception {
File file =new File("G:"+File.separator+"demo1"+File.separator+"OutpS03.text");
if(!file.getParentFile().exists()) {
file.getParentFile().mkdirs();
}
//2.此目录存在,文件不存在,利用其构造(File file)生成文件
OutputStream output =new FileOutputStream(file);
String str ="你好,HelloWorld!";
byte data[]=str.getBytes();
output.write(data,6,5);
output.close();
}
}
输出结果为:Hello
注意:我们这是对字节进行输出,一个中文or中文标点占用两个字节(你好,),所以我们是从“H”开始,输出5个字节后结束。
以上操作默认为覆盖内容,如要追加内容,在后面加true
如果涉及到追加那么,那么我们就得换行,而这里的换行
为什么必须是\r加上\n?
\r是回车符
\n是换行符
Linux和Unix系统的换行是"\n",而Windows的换行并不是直接的“\n”,因为Windows不认为"\n"是换行,在文档中只是一个空格或者小黑框。所以应该是先回车,再换行。

字节流InputStream
InputStream也一个抽象类,所以如果想进行文件读取,我们的使用它的子类FileStream(具体实现接口与OutputStream差不多)
其子类构造方法:public FileOutputStream(File file)
在InputStream中定义了如下三种方法读取数据:
1.
读取的单个字节:public abstract int read()
|-返回值:从输入流读取数据的下一个字节。 值字节被返回作为int范围0至255 。 如果没有字节可用,因为已经到达流的末尾,则返回值-1 。(返回值与2.3有区别)
2.将读取的数据保存在字节数组里:public int read(byte[]b)(不建议用)
|-返回值:返回读取的数据长度,已经到达流的末尾,则返回值-1 。
3.将读取的数据保存在部分字节数组里:public int read(byte[]b, int off,int len)
|-返回值:读取的部分数据的长度,已经到达流的末尾,则返回值-1 。
例:将读取的数据保存在部分字节数组里
public class TestInputS02 {
public static void main(String[] args) throws Exception {
File file =new File("G:"+File.separator+"demo1"+File.separator+"OutpS.text");
if(file.exists()) {//文件存在
//2.使用InputStream进行读取
InputStream input =new FileInputStream(file);
byte data[]=new byte [1024];//准备一个1024的字节数组(缓冲区)
//将内容存到数组中,并用len接收他的长度
int len=input.read(data);
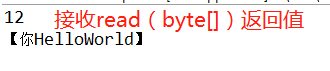
System.out.println(len);//接收返回值
input.close();
System.out.println("【"+new String(data,0,len)+"】");
}else {
System.out.println("文件不存在!");
}
}
}
这个是我们文本内容
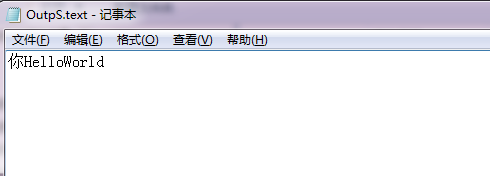
输出结果:
可以看到这个返回值是字节长度。
例:读取的单个字节:public abstract int read()
File file =new File("G:"+File.separator+"demo1"+File.separator+"InpS.text");
if(file.exists()) {//文件存在
InputStream input =new FileInputStream(file);
byte data[]=new byte [1024];//准备一个1024的字节数组(缓冲区)
int temp =0; //接收每次读取的字节数据
for(int x=0;x<5;x++) {
temp=input.read(); //只接收5个返回值
System.out.println(temp);
}
这是我们的文本内容
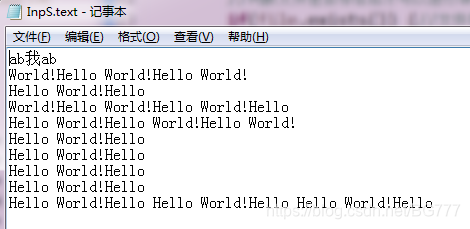
结果:
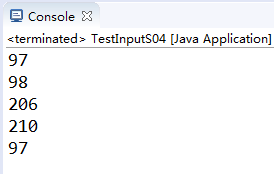
可以看到这时返回的是该字所对应的ASCII值
字符流Writer
public abstract class Writer
implement Closerable,Appendable,Flushable
Appendable接口定义如下:(虽然有这个接口,但我们基本上用不上,因为Writer接口本身就有write方法)

在Writer类里面定义有以下的输出方法(部分):
输出全部字符数组:public void write(char[] cuuf)
输出字符串:public void write(String Str)
Writer是一个抽象类,如果要想为这个类的对象实例化,应该使用FileWriterd子类(和FileOUtputStream一样提供有File构造)
例:使用Writer输出字符串
可以发现Writer可以作为字符串输出流,可以直接进行字符串的输出
字符流Reader
Reader是进行字符数据读取的输入流,其本身也是抽象类
在Reader类里面提供有一系列的读取内容的方法:
Public int read(char [] cbuf)
表示读取的数据长度,如果已经读到结尾了返回-1
在read中没有能够返回字符串的方法
例:

与字节输入流相比结构几乎是一样只是数据类型byte换成char。
字节流与字符流的转换(了解)
public class InputStreamReader extends Reader
在java.io包里面提供有两个类:InputStreamReader(Reader的子类)、OUtputStreamWriter(Writer的子类)
两个构造方法:
1.public InputStreamReader(InputStream in)
2. public InputStreamWriter(OutputStream out)

这种转换的意义不大,但有一种情况可能会用到(字符流方便处理中文数据)
字节流与字符流的区别?
字节流与字符流的最大的区别是:字节流直接与终端进行数据交换,而字符流需要将数据经过缓冲区处理后才可以输出。(OutputStream字节流如果没有使用close关闭数据流,结果可以正常输出,而Writer字符流没有使用close关闭数据流,那么缓冲区之中处理的内容不会被强制清空,所以不会输出数据),如果有特殊情况不能够关闭字符流,可以使用flush()方法强制清空缓冲区。
flush方法和close方法的区别
- flush :刷新缓冲区,流对象可以继续使用。
- close: 先刷新缓冲区,然后通知系统释放资源。流对象不可以再被使用了。
相同:使用两个流进行数据输出(输入)时,都是以字节的方式保存(读取),而在使用字符流读取的时候,实际上也是对字节数据进行读取,只不过这个转换的过程被操作系统隐藏了,在缓冲区里面机进行数据的转换。
两者如何使用?
用字节数据处理的比较多,例如:图片、视频、音乐、文字
字符流:唯一的好处是能对中文进行处理。
所以:在开发中如果要处理中文最好使用字符流,如果不是中文使用字节流(使用较多)。

















 3653
3653

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









