







在《官方教程:个人编程助手: 训练你自己的编码助手》和《第三方教程:个人编程助手: 训练你自己的编码助手》中存在一个微调 StarCoder 模型的教程,但没有讲清楚如何配置环境,以及其他所需附加知识点,本帖旨在解决这两个问题。
一、环境配置
1. 安装 Nvidia 显卡驱动
安装 Nvidia 显卡驱动有两种方法,第一种方法是从官网下载驱动 官网历史版本驱动下载,然后禁用本地驱动,最后安装下载的驱动,该方法安装失败的可能性较高。第二种方法是直接去 【软件和更新 --> 附加驱动】 中安装或升级驱动,推荐第二种方法,有时第二种方法可能不显示 Nvidia 显卡驱动,那需要参考 1 参考 2 参考 3,有时虽然显示 Nvidia 显卡驱动,但却是灰色,解决方法参考。
下载显卡驱动前首先需要确定显卡的硬件版本,查看硬件版本的方式是,首先运行 lspci | grep VGA 命令,查看硬件号,如下图是 2460,然后去链接中查询硬件版本,如下图为 RTX 3080 Ti。

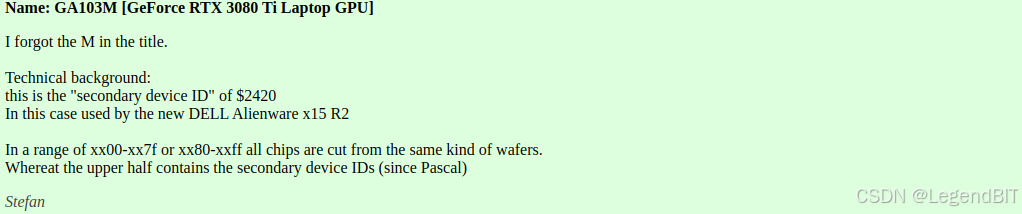
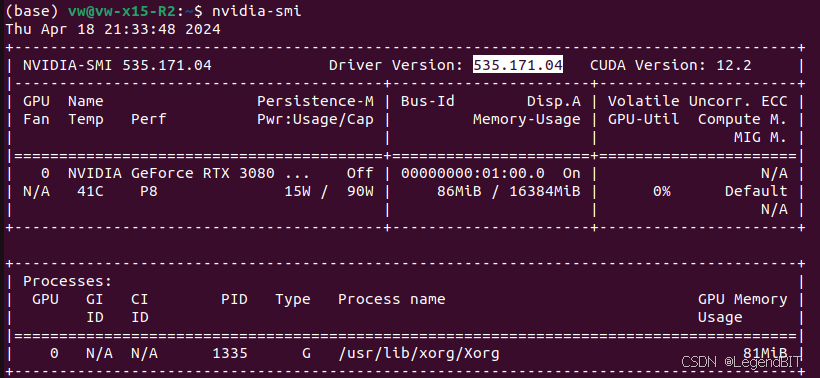
驱动版本需要 >=520。显卡驱动需要与 Cuda 版本匹配。由于后面需要安装 Flash Attention (要求 Cuda 版本大于 11.6) 和 Pytorch (较新版本均要求 Cuda 11.8 或 Cuda 12.1),所以可选的 Cuda 版本只有 Cuda 11.8 和 Cuda 12.1。当选择 Cuda 11.8 时,Nvidia 显卡驱动需要 >=520,当选择 Cuda 12.1 时,Nvidia 显卡驱动需要 >=530。Nvidia 显卡驱动与 Cuda 版本匹配要求见 链接。nvidia-smi 命令显示结果中右上部分的 CUDA Version: 12.2 是当前 Nvidia 显卡驱动所支持的最高 Cuda 版本。
实际测试成功安装的是 535.171.04,所用 Ubuntu 版本是 22.04.4 LTS。
2. 安装 Cuda
首次安装 Cuda 的教程参考,删除现有 Cuda 更换新版本的教程参考。简单来说就是,从官网下载对应版本 Cuda,通过 sudo sh cuda_12.1.0_530.30.02_linux.run 命令安装。需要注意的是,在安装过程中不要选择安装 Driver。
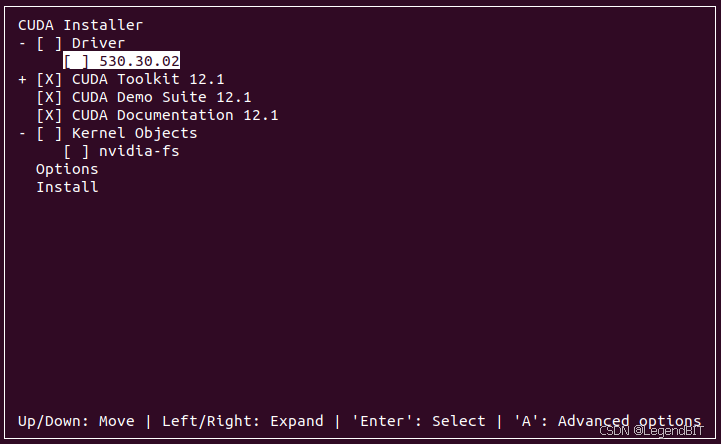
安装完成后需要添加环境变量。
sudo vim ~/.bashrc
在其中添加:
export PATH=/usr/local/cuda-12.1/bin:$PATH
export LD_LIBRARY_PATH=/usr/local/cuda-12.1/lib64$LD_LIBRARY_PATH
然后运行:
source ~/.bashrc
安装完成后,需要通过命令 nvcc --version 判断是否安装成功,实际测试成功安装的是 Cuda 12.1。
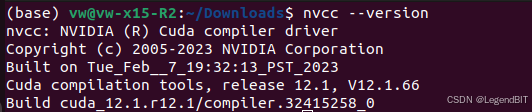
完成 Cuda 安装后,如果下面的深度学习开发库是 pytorch,据说可以不用再安装 cudnn,pytorch 自带 cudnn。所以这里可以不用再继续安装 cudnn,经过测试 pytorch 也确实可以运行成功。但为了以防万一,这里还是记录了 cudnn 的单独安装教程。
从官网下载 cudnn。首页选择版本号 (不用太新),然后选择对应系统等信息,最后建议选择 deb (network) 的安装方式。运行如下命令便可完成安装:
wget https://developer.download.nvidia.com/compute/cuda/repos/ubuntu2204/x86_64/cuda-keyring_1.1-1_all.deb
sudo dpkg -i cuda-keyring_1.1-1_all.deb
sudo apt-get update
sudo apt-get -y install cudnn
查看已安装 Cudnn 版本的方法是
cat /usr/include/cudnn_version.h
测试 cudnn 是否安装成功
cp -r /usr/src/cudnn_samples_v8/ $HOME
cd $HOME/cudnn_samples_v8/mnistCUDNN
make clean && make
./mnistCUDNN
显示 Test passed! 则安装成功。如果上面的 make 命令提示缺少 FreeImage.h,运行:sudo apt-get install libfreeimage3 libfreeimage-dev。
cudnn 的卸载教程参考链接。
3. 安装 Anaconda
从清华镜像下载 Linux 版本的 Anaconda,清华镜像官网 Anaconda 下载,版本选择不用太在意,建议选择新一点的版本,不用最新。举例使用 Anaconda3-2023.03-Linux-x86_64.sh,通过命令 bash Anaconda3-2023.03-Linux-x86_64.sh 安装 Anaconda,然后一路 yes 即可完成安装。安装教程参考链接。
完成 Anaconda 安装后,需要通过 conda create --name starcoder python=3.10 命令创建虚拟环境,并指定 python 版本,由于后面需要安装 xformers,而 xformers 版本需要与 python 版本以及 pytorch 版本匹配,实际测试安装成功的是 python 3.10 + pytorch 2.1.1 和 xformers 0.0.23。完成虚拟环境创建后,需要通过命令 conda activate starcoder 激活虚拟环境。如果后面想要删除虚拟环境,可以通过命令 conda remove --starcoder --all。
4. clone 代码
git clone GitHub - pacman100/LLM-Workshop: LLM Workshop by Sourab Mangrulkar
cd DHS-LLM-Workshop
5. 安装一系列所需的软件包
5.1 安装 pytorch
pytorch 版本需要与 xformer 版本和 Cuda 版本匹配,所以实际测试安装成功的是 pytorch 2.1.1,如下第一句为官网推荐安装方式,但是速度巨慢,可以使用第二句进行安装。
conda install pytorch==2.1.1 torchvision==0.16.1 torchaudio==2.1.1 pytorch-cuda=12.1 -c pytorch -c nvidia
pip install torch==2.1.1 torchvision==0.16.1 torchaudio==2.1.1 -i https://mirrors.aliyun.com/pypi/simple/
5.2 安装 packing
pip install packaging
5.3 安装 ninja
必须首先安装 ninja,否则后面编译 FlashAttention 会很慢
pip uninstall -y ninja && pip install ninja
![]()
5.4 安装剩余软件包
pip install -r requirements.txt -i https://mirrors.aliyun.com/pypi/simple/
如果安装过程中,部分之前安装的软件包被升级,需要手动再降级回来,此外,如果还存在版本不匹配,则需要调整部分软件的版本,参照附件 1 的 pip list。
5.5 安装 FlashAttention
如果上一步没有报错,那 FlashAttention 已经安装完成,不用再管这一步,如果没有安装完成,可以尝试从源码进行安装,参考 链接 1 链接 2 链接 3。
需要注意目前原生的 FlashAttention 仅支持 Ampere、Hopper 等架构的 GPU。RTX3080ti 属于 Ampere 架构。架构不支持可能会报错。
6. 关于 WanDB
WanDB 是一个可类比 Tensorboard 的可视化程序,可以实现可视化模型的训练过程,甚至可以选择保存本次训练所用的代码和数据,但是它没有本地查看客户端,需要先将数据保存在本地,然后自动上传服务器端,最后通过浏览器查看结果,上传远程服务器需要提前注册账户和梯子,也可以选择本地 Docker 方式部署,完成部署后就可以将训练数据自动上传本地服务器,以实现可视化。相关教程可以参考 链接 1 链接 2 链接 3 链接 4。
运行代码时可通过命令 wandb login --relogin 然后输入证书,实现远程连接。但在执行 StarCoder 代码时,我们选择关闭这个功能,避免麻烦的云端上传。
7. 关于 HuggingFace
由于代码在运行时需要从 HuggingFace 官网下载预训练模型和 fine-tune 数据集,而 HuggingFace 要求在数据下载前先要验证身份,所以需要事先去 HuggingFace 官网注册一个账号,然后去 setting --> Access Tokens 中拿到证书秘钥。
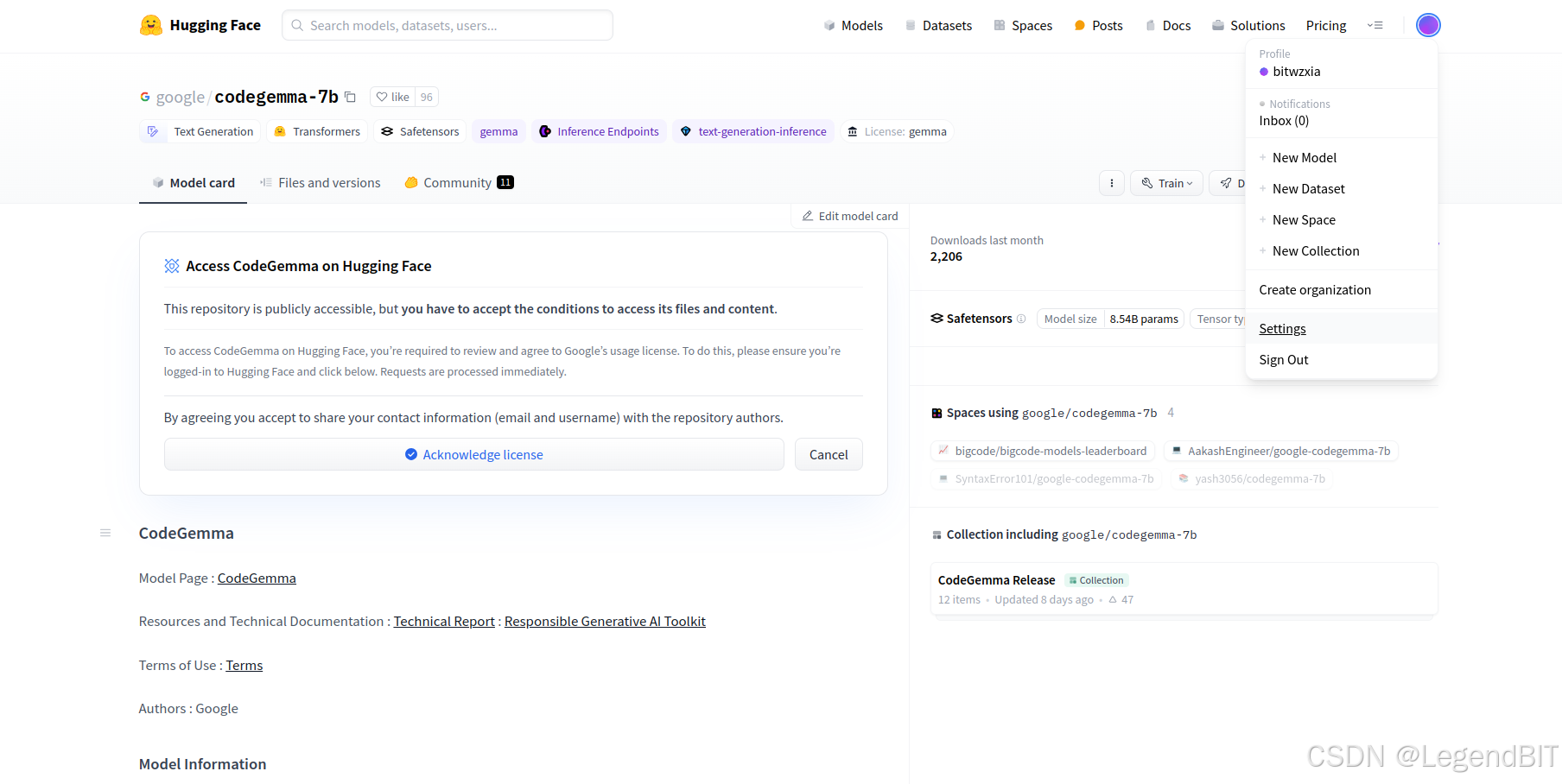
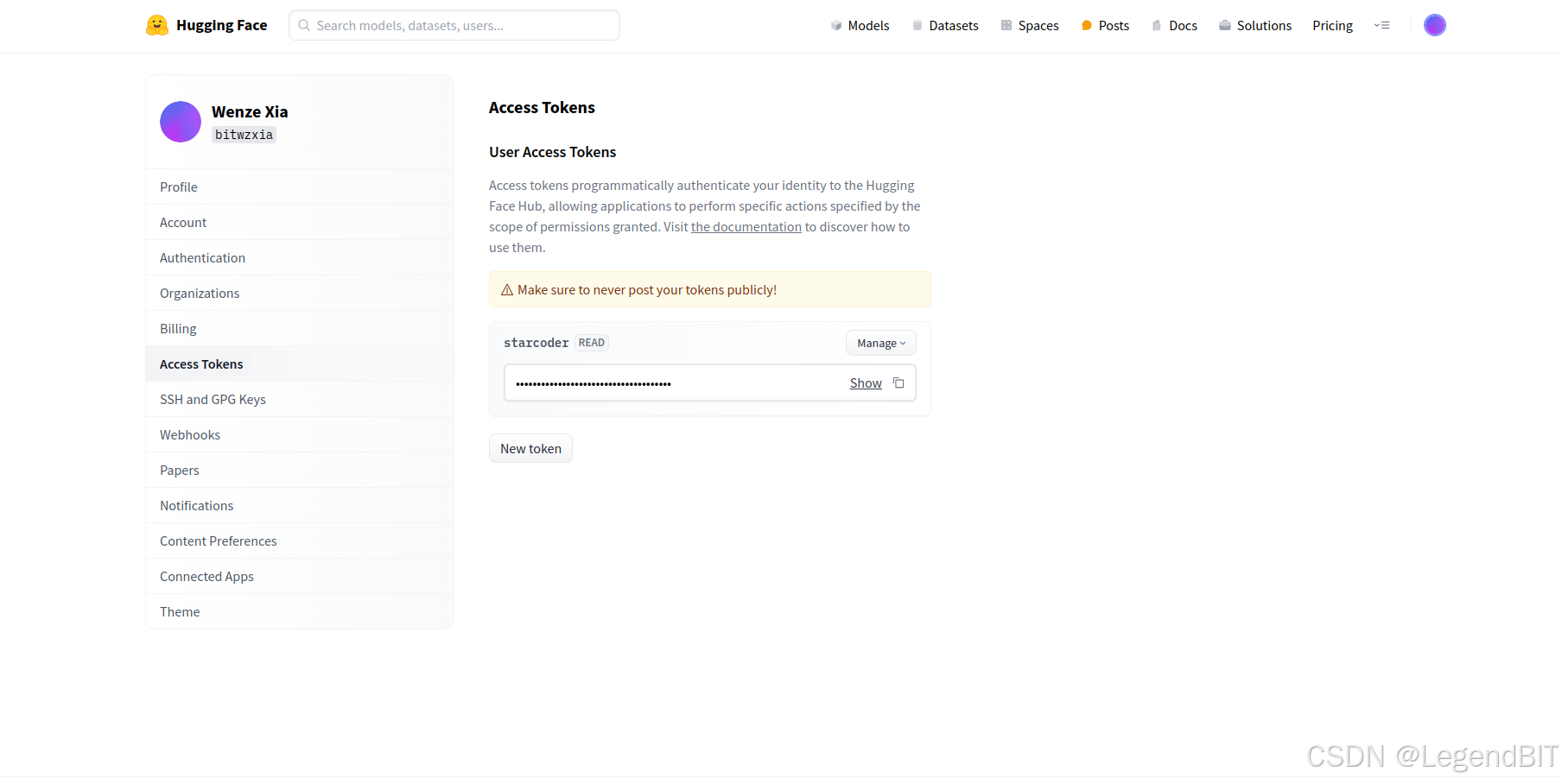
此外,还要根据代码运行时所需的模型去网页上拿到模型下载授权,例如上面第一个图是 codegemma-7b 的界面,界面左上部分显示,我们并没有获得下载权限,点击 Acknowlege License 即可获得授权,如下图这种界面就是已获得 starcoderbase-1b 的下载授权。
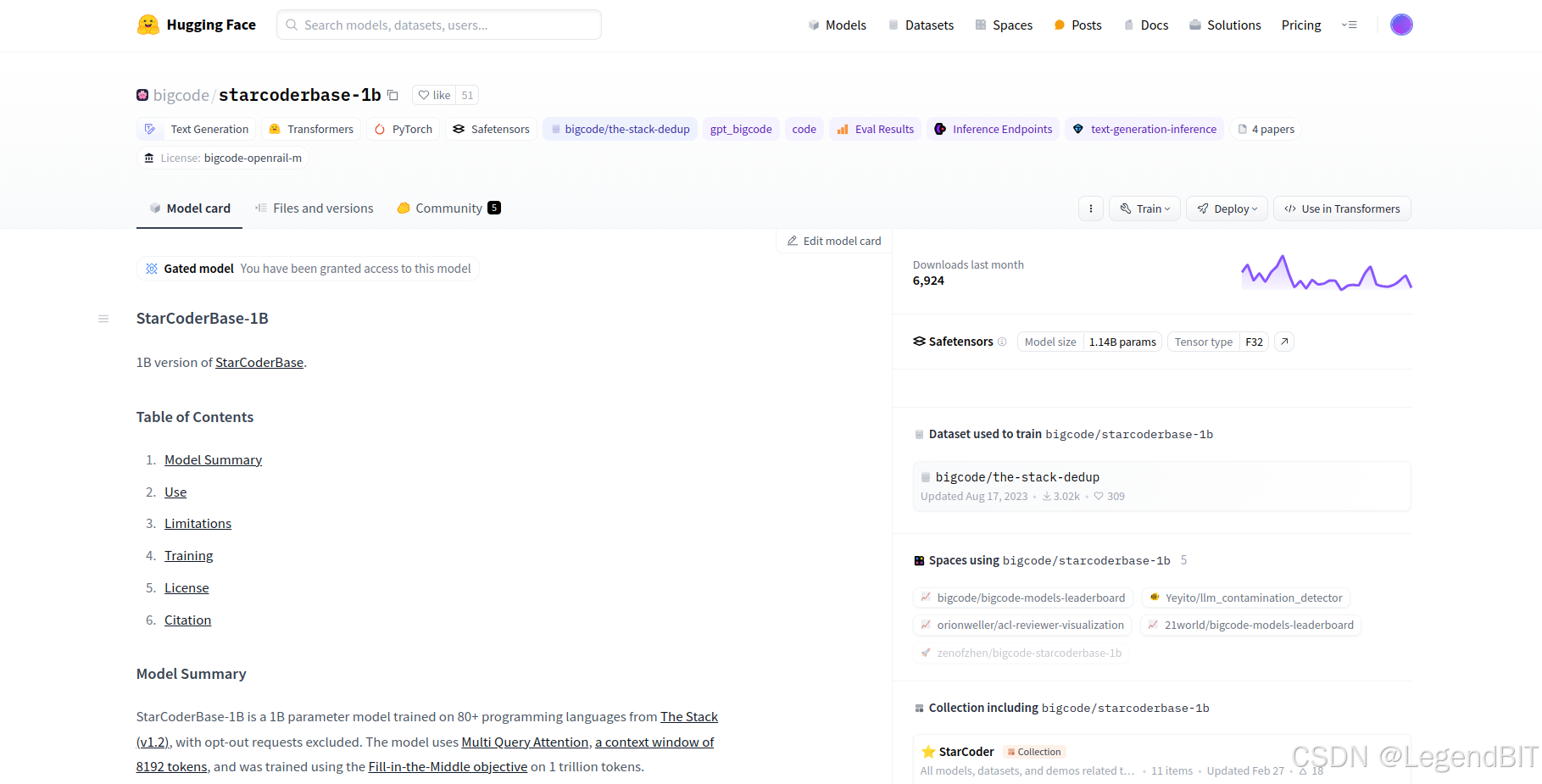
然后在代码运行时,由于 huggingface-cli login 命令的存在,会要求输入秘钥,只有在输入证书秘钥后才会继续运行。
二、运行代码
1. 运行命令
原教程中的代码运行命令存在版本不匹配问题,不建议使用原教程的运行命令,报错参考链接。我重写了运行命令,可以使用如下命令进行运行。当前参数设置下,1B 的模型可以训练,7B 模型会内存不够。
cd personal_copilot/training/
sh train.sh
train.sh 内容如下:
huggingface-cli login
CUDA_VISIBLE_DEVICES=0 python train.py \
--model_name_or_path "bigcode/starcoderbase-1b" \
--dataset_name "smangrul/hf-stack-v1" \
--splits "train" \
--max_seq_len 2048 \
--max_steps 1000 \
--save_steps 100 \
--eval_steps 100 \
--logging_steps 25 \
--log_level "info" \
--logging_strategy "steps" \
--evaluation_strategy "steps" \
--save_strategy "steps" \
--push_to_hub False \
--hub_private_repo True \
--hub_strategy "every_save" \
--bf16 True \
--learning_rate 2e-4 \
--lr_scheduler_type "cosine" \
--weight_decay 0.01 \
--warmup_ratio 0.1 \
--max_grad_norm 1.0 \
--output_dir "peft-qlora-starcoderbase1B-personal-copilot-3080Ti-16GB" \
--per_device_train_batch_size 6 \
--per_device_eval_batch_size 6 \
--gradient_accumulation_steps 2 \
--gradient_checkpointing True \
--use_reentrant True \
--dataset_text_field "content" \
--test_size 0.1 \
--fim_rate 0.5 \
--fim_spm_rate 0.5 \
--use_peft_lora True \
--lora_r 8 \
--lora_alpha 32 \
--lora_dropout 0.1 \
--lora_target_modules "c_proj,c_attn,q_attn,c_fc,c_proj" \
--use_4bit_quantization True \
--use_nested_quant True \
--bnb_4bit_compute_dtype "bfloat16" \
--use_flash_attn True然后显示如下界面,需要输入 HuggingFace 秘钥。

然后显示如下界面,需要选择 3 ,即不使用 WanDB 可视化工具,否则需要去官网注册账号,还需要梯子。在代码运行前提前设置环境变量可以避免出现如下界面,Automatic Weights & Biases logging enabled, to disable set os.environ["WANDB_DISABLED"] = "true"。
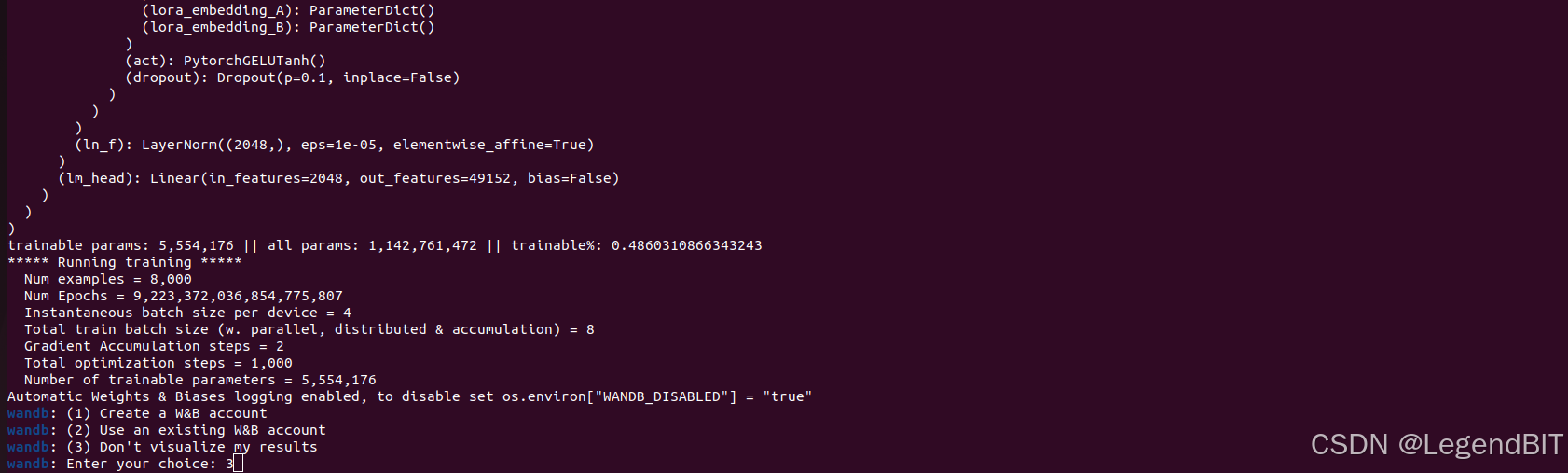
然后模型开始正常训练,1000 个 step 的 fine tune 时间预计 2 小时。
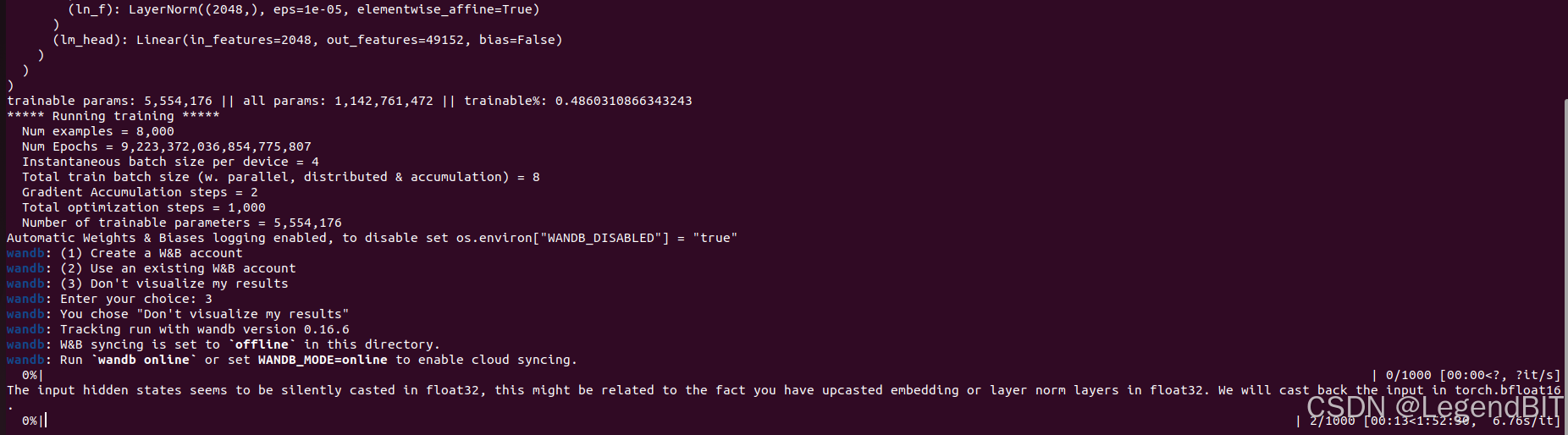
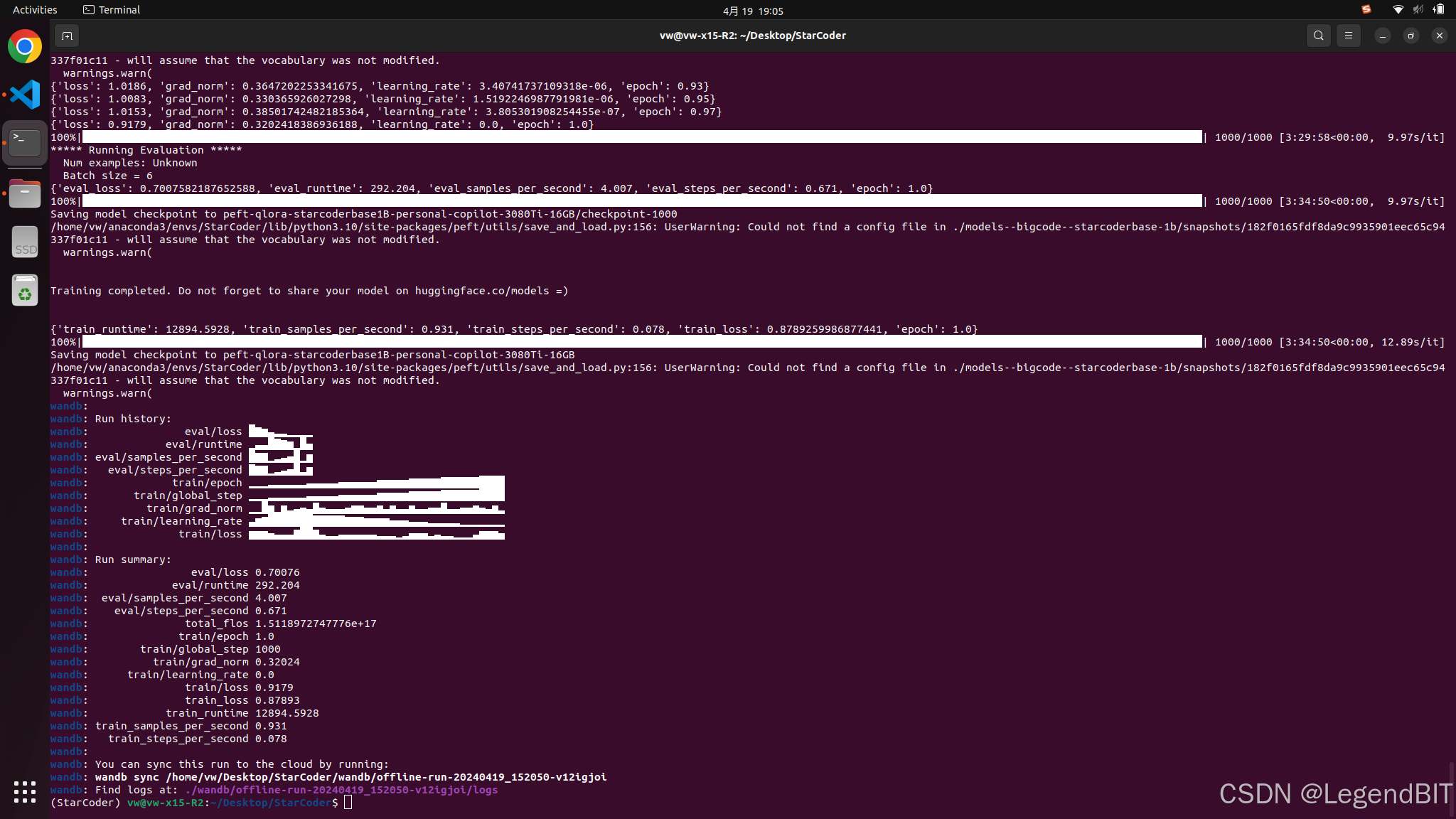
最终训练结果保存在 .peft-qlora-starcoderbase1B-personal-copilot-3080Ti-16GB 目录下。保存结果只有 LoRA 的权重,没有将权重合并进基础权重中。
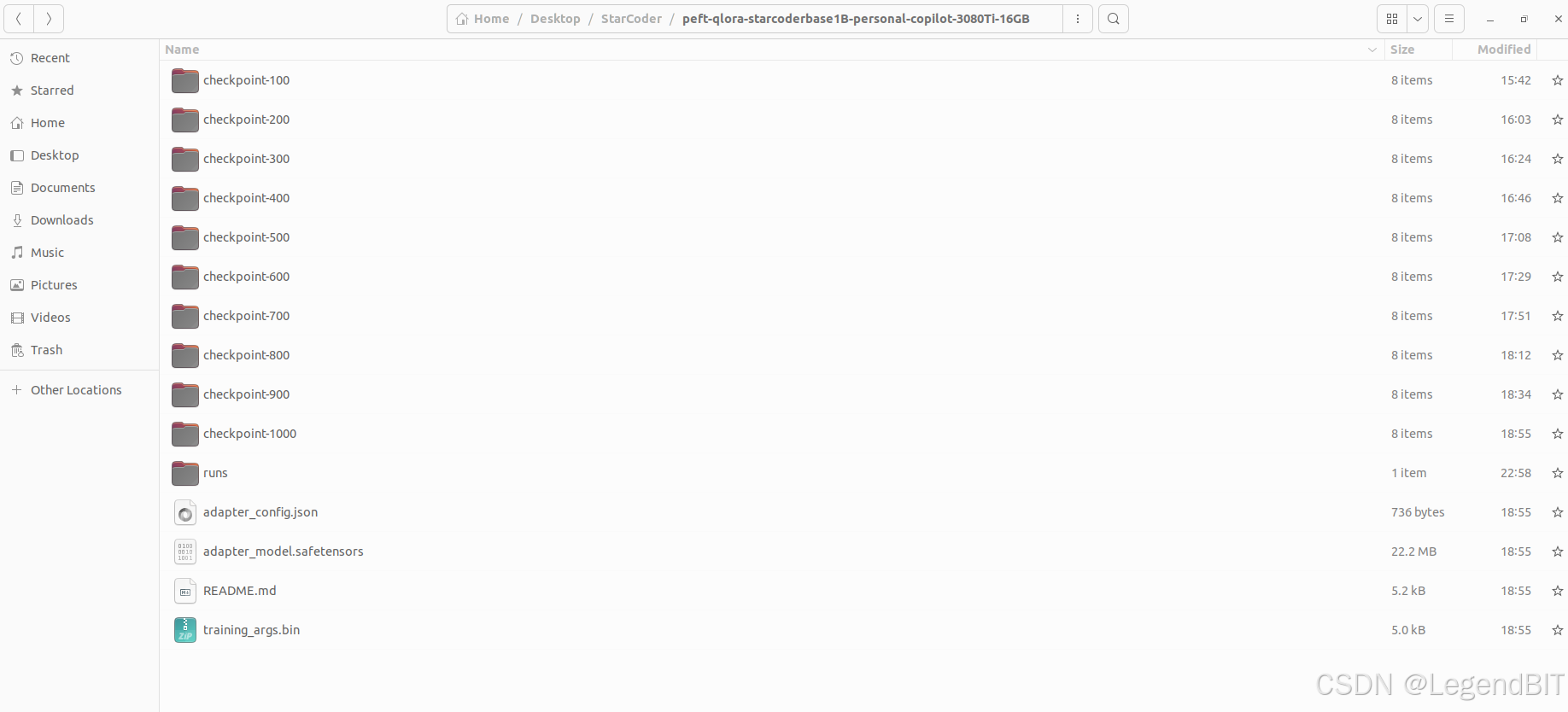
如果想要将 LoRA 权重合并进基础权重中可以使用如下代码,merge_peft_adapter.py 见附件 2。
python merge_peft_adapter.py \
--model_type starcoder \
--base_model ./models--bigcode--starcoderbase-1b \ # 基础模型参数路径
--tokenizer_path ./models--bigcode--starcoderbase-1b \ # 基础模型参数路径
--lora_model ./peft-qlora-starcoderbase1B-personal-copilot-3080Ti-16GB \ # Adapter模型参数路径
--output_dir ./peft-qlora-starcoderbase1B-personal-copilot-3080Ti-16GB/merge_model # 输出路径
如果想用本地模型和数据集进行训练,则可以替换 train.sh 中的前两行为如下两行:
--model_name_or_path "./models/models--bigcode--starcoderbase-1b" \
--dataset_name "./data/hf-stack-v1" \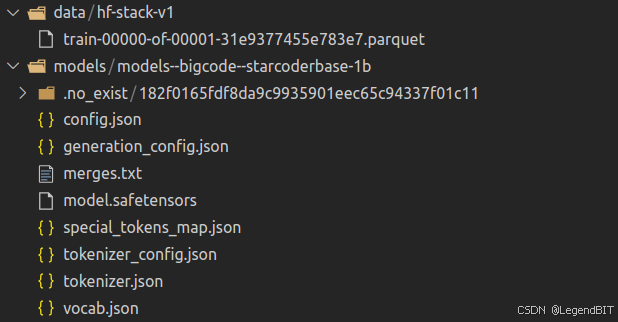
models--bigcode--starcoderbase-1b 中的内容从 链接 下载,hf-stack-v1 中的内容从 链接 下载。
参考链接
附件 1
Package Version
------------------------ -----------
absl-py 2.1.0
accelerate 0.30.0.dev0
aiohttp 3.9.4
aiosignal 1.3.1
annotated-types 0.6.0
appdirs 1.4.4
async-timeout 4.0.3
attrs 23.2.0
bitsandbytes 0.43.1
certifi 2024.2.2
cffi 1.16.0
charset-normalizer 3.3.2
click 8.1.7
contourpy 1.2.1
cryptography 42.0.5
cycler 0.12.1
datasets 2.18.0
datatrove 0.0.1
deepspeed 0.14.0
Deprecated 1.2.14
dill 0.3.8
docker-pycreds 0.4.0
docstring_parser 0.16
einops 0.7.0
evaluate 0.4.1
filelock 3.13.4
flash-attn 2.5.7
fonttools 4.51.0
frozenlist 1.4.1
fsspec 2024.2.0
gitdb 4.0.11
GitPython 3.1.43
grpcio 1.62.1
hjson 3.1.0
huggingface-hub 0.22.2
humanize 4.9.0
idna 3.7
Jinja2 3.1.3
joblib 1.4.0
kiwisolver 1.4.5
loguru 0.7.2
Markdown 3.6
markdown-it-py 3.0.0
MarkupSafe 2.1.5
matplotlib 3.8.4
mdurl 0.1.2
mpmath 1.3.0
multidict 6.0.5
multiprocess 0.70.16
networkx 3.3
ninja 1.11.1.1
nltk 3.8.1
numpy 1.26.4
nvidia-cublas-cu12 12.1.3.1
nvidia-cuda-cupti-cu12 12.1.105
nvidia-cuda-nvrtc-cu12 12.1.105
nvidia-cuda-runtime-cu12 12.1.105
nvidia-cudnn-cu12 8.9.2.26
nvidia-cufft-cu12 11.0.2.54
nvidia-curand-cu12 10.3.2.106
nvidia-cusolver-cu12 11.4.5.107
nvidia-cusparse-cu12 12.1.0.106
nvidia-nccl-cu12 2.18.1
nvidia-nvjitlink-cu12 12.4.127
nvidia-nvtx-cu12 12.1.105
opencv-python 4.9.0.80
packaging 24.0
pandas 2.2.2
peft 0.10.1.dev0
pillow 10.3.0
pip 23.3.1
protobuf 3.20.3
psutil 5.9.8
py-cpuinfo 9.0.0
pyarrow 15.0.2
pyarrow-hotfix 0.6
pycparser 2.22
pydantic 2.7.0
pydantic_core 2.18.1
PyGithub 2.3.0
Pygments 2.17.2
PyJWT 2.8.0
PyNaCl 1.5.0
pynvml 11.5.0
pyparsing 3.1.2
python-dateutil 2.9.0.post0
pytz 2024.1
PyYAML 6.0.1
regex 2023.12.25
requests 2.31.0
responses 0.18.0
rich 13.7.1
safetensors 0.4.2
scipy 1.13.0
sentencepiece 0.2.0
sentry-sdk 1.45.0
setproctitle 1.3.3
setuptools 68.2.2
shtab 1.7.1
six 1.16.0
smmap 5.0.1
sympy 1.12
tensorboard 2.16.2
tensorboard-data-server 0.7.2
tiktoken 0.6.0
tokenizers 0.15.2
torch 2.1.1
torchaudio 2.1.1
torchvision 0.16.1
tqdm 4.66.2
transformers 4.40.0.dev0
triton 2.1.0
trl 0.8.3.dev0
typing_extensions 4.11.0
tyro 0.8.3
tzdata 2024.1
unsloth 2024.4
urllib3 2.2.1
wandb 0.16.6
Werkzeug 3.0.2
wheel 0.43.0
wrapt 1.16.0
xformers 0.0.23
xxhash 3.4.1
yarl 1.9.4
附件 2
import argparse
import torch
from peft import PeftModel, PeftConfig
from transformers import (
AutoModel,
AutoTokenizer,
BloomForCausalLM,
BloomTokenizerFast,
AutoModelForCausalLM,
LlamaTokenizer,
LlamaForCausalLM,
AutoModelForSequenceClassification,
)
MODEL_CLASSES = {
"starcoder": (AutoModelForCausalLM, AutoTokenizer),
"bloom": (BloomForCausalLM, BloomTokenizerFast),
"chatglm": (AutoModel, AutoTokenizer),
"llama": (LlamaForCausalLM, LlamaTokenizer),
"baichuan": (AutoModelForCausalLM, AutoTokenizer),
"auto": (AutoModelForCausalLM, AutoTokenizer),
}
def main():
parser = argparse.ArgumentParser()
parser.add_argument('--model_type', default=None, type=str, required=True)
parser.add_argument('--base_model', default=None, required=True, type=str,
help="Base model name or path")
parser.add_argument('--tokenizer_path', default=None, type=str,
help="Please specify tokenization path.")
parser.add_argument('--lora_model', default=None, required=True, type=str,
help="Please specify LoRA model to be merged.")
parser.add_argument('--resize_emb', action='store_true', help='Whether to resize model token embeddings')
parser.add_argument('--output_dir', default='./merged', type=str)
parser.add_argument('--hf_hub_model_id', default='', type=str)
parser.add_argument('--hf_hub_token', default=None, type=str)
args = parser.parse_args()
# print(args)
base_model_path = args.base_model
lora_model_path = args.lora_model
output_dir = args.output_dir
print(f"Base model: {base_model_path}")
print(f"LoRA model: {lora_model_path}")
peft_config = PeftConfig.from_pretrained(lora_model_path)
model_class, tokenizer_class = MODEL_CLASSES[args.model_type]
if peft_config.task_type == "SEQ_CLS":
print("Loading LoRA for sequence classification model")
if args.model_type == "chatglm":
raise ValueError("chatglm does not support sequence classification")
base_model = AutoModelForSequenceClassification.from_pretrained(
base_model_path,
num_labels=1,
load_in_8bit=False,
torch_dtype=torch.float32,
trust_remote_code=True,
device_map="auto",
)
else:
print("Loading LoRA for causal language model")
base_model = model_class.from_pretrained(
base_model_path,
load_in_8bit=False,
torch_dtype=torch.float16,
trust_remote_code=True,
device_map="auto",
)
if args.tokenizer_path:
tokenizer = tokenizer_class.from_pretrained(args.tokenizer_path, trust_remote_code=True)
else:
tokenizer = tokenizer_class.from_pretrained(base_model_path, trust_remote_code=True)
if args.resize_emb:
base_model_token_size = base_model.get_input_embeddings().weight.size(0)
if base_model_token_size != len(tokenizer):
base_model.resize_token_embeddings(len(tokenizer))
print(f"Resize vocabulary size {base_model_token_size} to {len(tokenizer)}")
new_model = PeftModel.from_pretrained(
base_model,
lora_model_path,
device_map="auto",
torch_dtype=torch.float16,
)
new_model.eval()
print(f"Merging with merge_and_unload...")
base_model = new_model.merge_and_unload()
print("Saving to Hugging Face format...")
tokenizer.save_pretrained(output_dir)
base_model.save_pretrained(output_dir, max_shard_size='10GB')
print(f"Done! model saved to {output_dir}")
if args.hf_hub_model_id:
print(f"Pushing to Hugging Face Hub...")
base_model.push_to_hub(
args.hf_hub_model_id,
token=args.hf_hub_token,
max_shard_size="10GB",
)
tokenizer.push_to_hub(
args.hf_hub_model_id,
token=args.hf_hub_token,
)
print(f"Done! model pushed to Hugging Face Hub: {args.hf_hub_model_id}")
if __name__ == '__main__':
main()

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









