







1. 内容概览
本节介绍B+树的更多知识,包括重复的KEY处理、部分索引、Tries索引,倒排索引等.

2. 处理重复Key
前面一节讲过B+中处理重复KEY的方法,这里是从更宏观的角度看. 介绍了两种方案:在KEY后面加上Record ID使每个KEY变得唯一,或者给叶节点添加溢出节点专门存放重复的KEY.

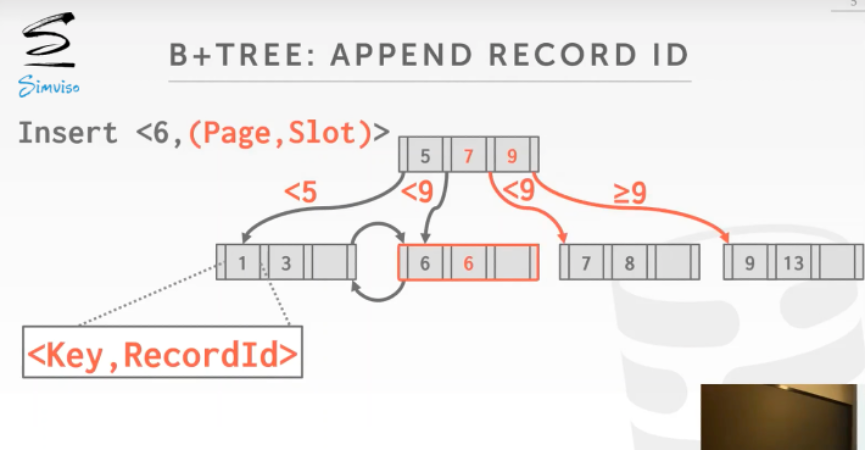
第一种方案中,每个叶节点的KEY都加上了Record ID,Record ID中包括Page和Offset,DBMS依然可以根据KEY前面的部分进行搜索.
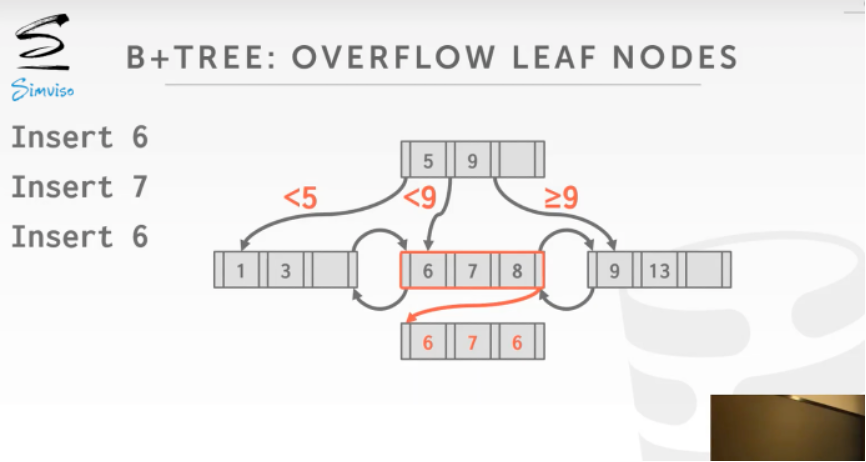
第二种方案中,重复的KEY会加入到叶节点的溢出节点中(这时候B+树可能会不平衡),搜索的时候相同的KEY从叶节点的溢出节点中继续寻找.
3. 部分索引
有时候只需要对表中满足特定条件的部分数据建索引,这时候只需要建立部分索引。例如下面的例子中,只需要在c='WuTang’的元组的(a,b)属性上建立索引.这样可以降低B+树的深度,降低索引大小,减少无关数据对Buffer Pool的占用.

如果索引能够完全覆盖我们查询涉及的数据,那么也称为覆盖索引.下面的例子中,SELECT涉及的数据完全被(a,b)上的索引覆盖,DBMS无需到叶子节点中通过 Record ID 拿到 Tuple 之后进一步判断其他属性是否满足条件.

如果查询中添加了属性c的判断,可以通过include语句将c属性的真实值加到B+树的叶子节点中而不添加中中间节点,这样既可以让DBMS不用拿到真实的数据后再做判断,减少了一次I/O,同时没有占用索引太多的空间(只是在叶子节点中添加了c的值).

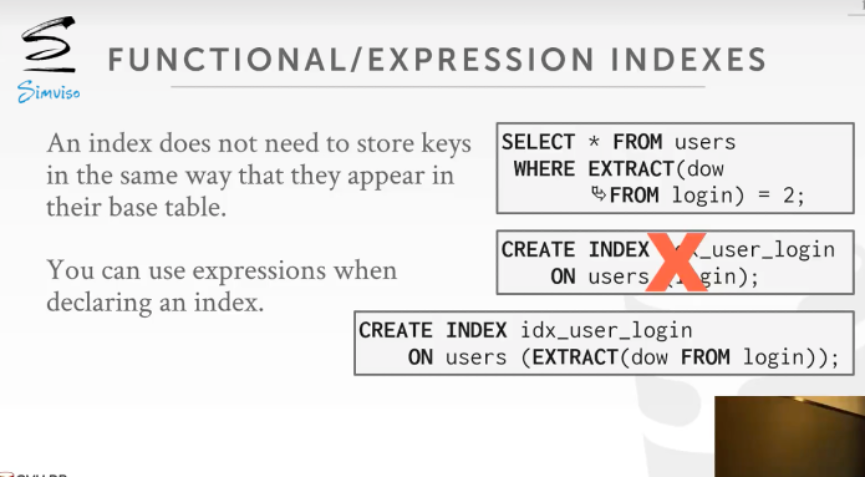
另外,有时候索引并不是建立在某个属性原本的值上,因此还有函数索引的概念,将索引建立在某个函数变换后的属性上.
到目前为止我们发现,仅通过B+树的叶子节点无法判断数据是否真实存在(仅管覆盖索引),真实的数据都只存储在叶子节点中.
4. Trie索引
Trie索引将排序后的每个KEY拆分(一般按照字符拆分)组成的树形结构,又叫做Trie树、字典树、前缀树等.

Trie索引具有一些有趣的性质,例如无论KEY插入的顺序如何,最终的树都是确定的. 增删改查的复杂度为O(k),其中k为Key的长度.经常被用在点查询,不适合范围查询(因为在Trie树上范围查询必须回溯)

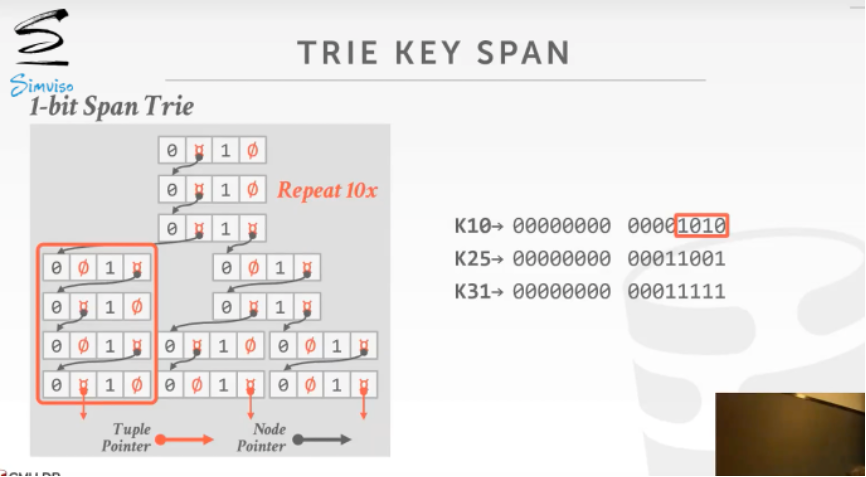
Trie索引的SPAN指的是Trie树节点中每个KEY占的比特位.

例如下图表示SPAN=1的Trie索引
若Trie索引中的节点只有一个孩子节点,那么可以将这些节点合并为一个节点,形成Radix树(基数树),例如下图就是一个1-bit span的基数树.

若基数树种新插入的节点只有一个孩子节点,那么这些节点可以合并.
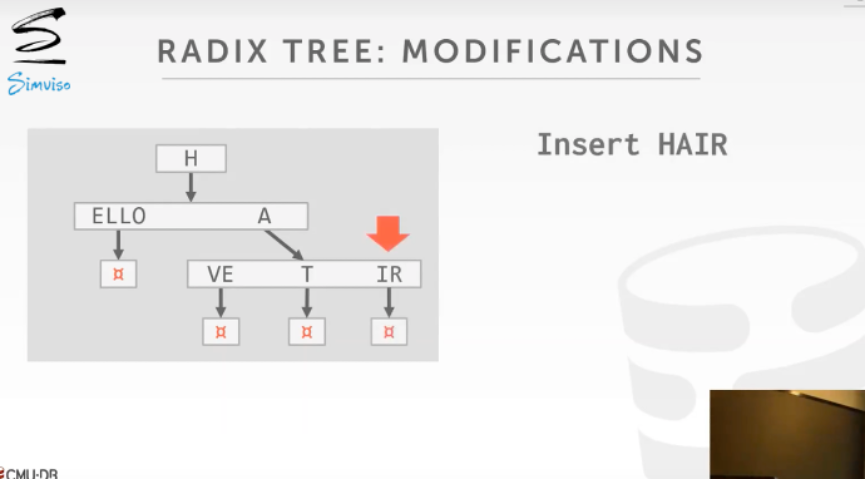
5. 倒排索引
前面介绍的所有索引(包括哈希索引、B+树索引、Trie索引)都能很好的处理点查询和范围查询,但是都不能支持全文检索任务,需要新的索引机制来解决这个问题.
倒排索引原理是存储每个 word 及其出现的 Record ID,因此倒排索引的维护代价较高.

倒排索引一般支持的查询有短语查询、临近查询、通配符查询:

由于倒排索引需要支持较为复杂的查询并且维护成本较大,因此设计的时候需要考虑保存哪些数据以及合适的索引更新时机:

关注我的微信订阅号,交流分布式系统相关技术:
















 4233
4233











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









