






大家好,我是才哥。
今天我们一起来采集王者荣耀英雄的全部皮肤地址,目标网址:
https://pvp.qq.com/web201605/herolist.shtml
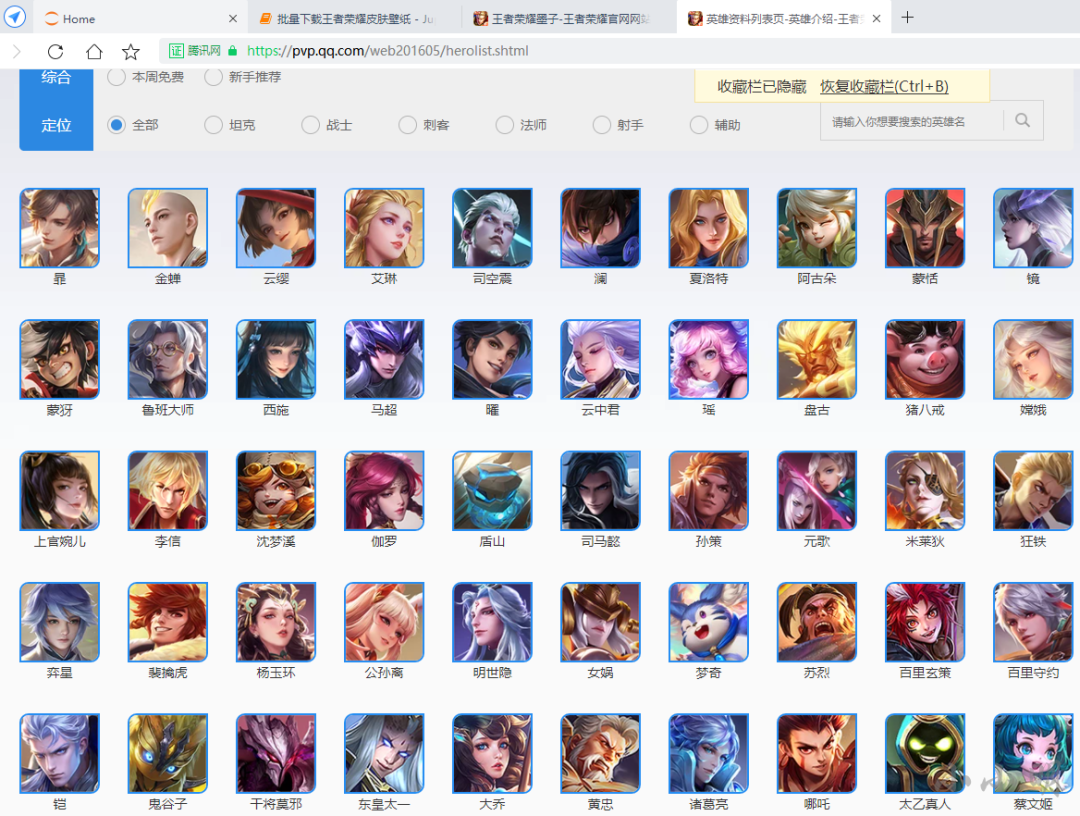
通过开发者工具发现 https://pvp.qq.com/web201605/js/herolist.json接口返回了全部英雄数据。
import requests
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.104 Safari/537.36'
}
herolist = requests.get(
"https://pvp.qq.com/web201605/js/herolist.json", headers=headers).json()
herolist[{'ename': 105,
'cname': '廉颇',
'title': '正义爆轰',
'new_type': 0,
'hero_type': 3,
'skin_name': '正义爆轰|地狱岩魂'},
{'ename': 106,
'cname': '小乔',
'title': '恋之微风',
'new_type': 0,
'hero_type': 2,
'skin_name': '恋之微风|万圣前夜|天鹅之梦|纯白花嫁|缤纷独角兽'},
......但是针对第一个英雄廉颇点开详情页后,可以看到网址为https://pvp.qq.com/web201605/herodetail/105.shtml,从而可以知道页面随着ename变化。
我们发现实际并不只有这两个皮肤,勇者和特殊活动的皮肤并不直接在json接口里显示:
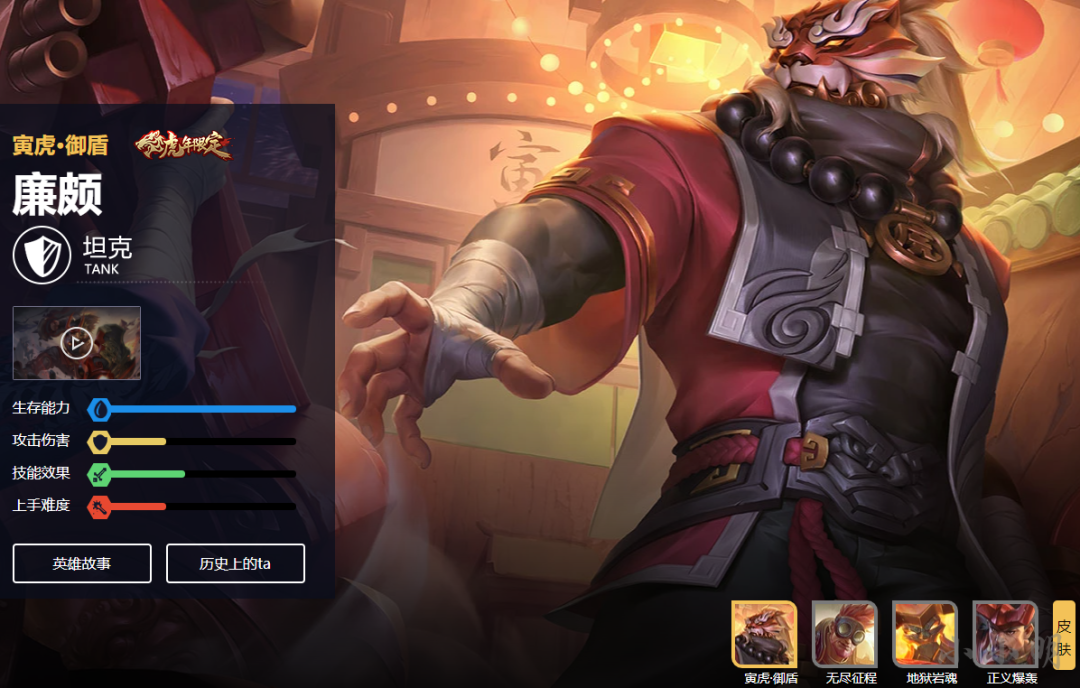
这意味着完整皮肤详情只能访问详情页查看,透过style属性可以看到图片地址,从而发现规律:
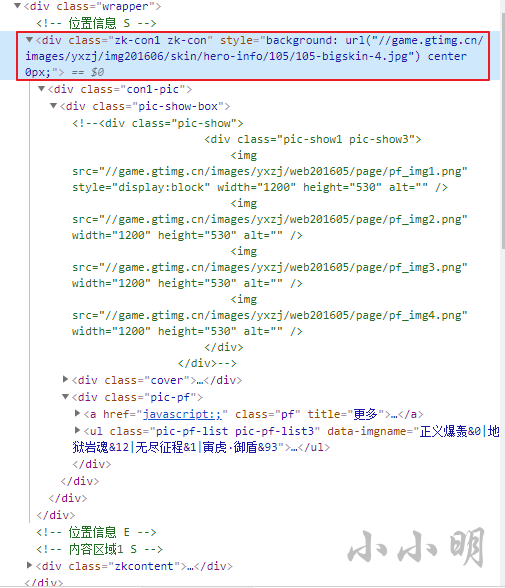
而完整的皮肤名称列表可以通过上述ul的data-imgname属性获取,最终完整代码如下:
import requests
import os
import re
from concurrent.futures import ThreadPoolExecutor
def download_img(eid, name, i, skin_name):
filename = f"王者荣耀壁纸/{eid:0>3}-{name}-{i:0>2}-{skin_name}.jpg"
print(filename)
if os.path.exists(filename):
return
img_url = f"http://game.gtimg.cn/images/yxzj/img201606/skin/hero-info/{eid}/{eid}-bigskin-{i}.jpg"
res = requests.get(img_url)
with open(filename, "wb") as f:
f.write(res.content)
def download_hero_skin(hero):
eid, name = hero["ename"], hero["cname"]
res = requests.get(f"https://pvp.qq.com/web201605/herodetail/{eid}.shtml",
headers=headers)
res.encoding = "gbk"
skin_names = re.findall(
'<ul[^>]+?data-imgname="([^"]+)"', res.text)[0].split("|")
print(eid, name, skin_names)
for i, skin_name in enumerate(skin_names, 1):
end = skin_name.find("&")
skin_name = skin_name[:len(skin_name) if end == -1 else end]
download_img(eid, name, i, skin_name)
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.104 Safari/537.36'
}
herolist = requests.get(
"https://pvp.qq.com/web201605/js/herolist.json", headers=headers).json()
os.makedirs("王者荣耀壁纸", exist_ok=True)
with ThreadPoolExecutor(max_workers=16) as executor:
executor.map(download_hero_skin, herolist)经过30秒左右已经下载完毕:
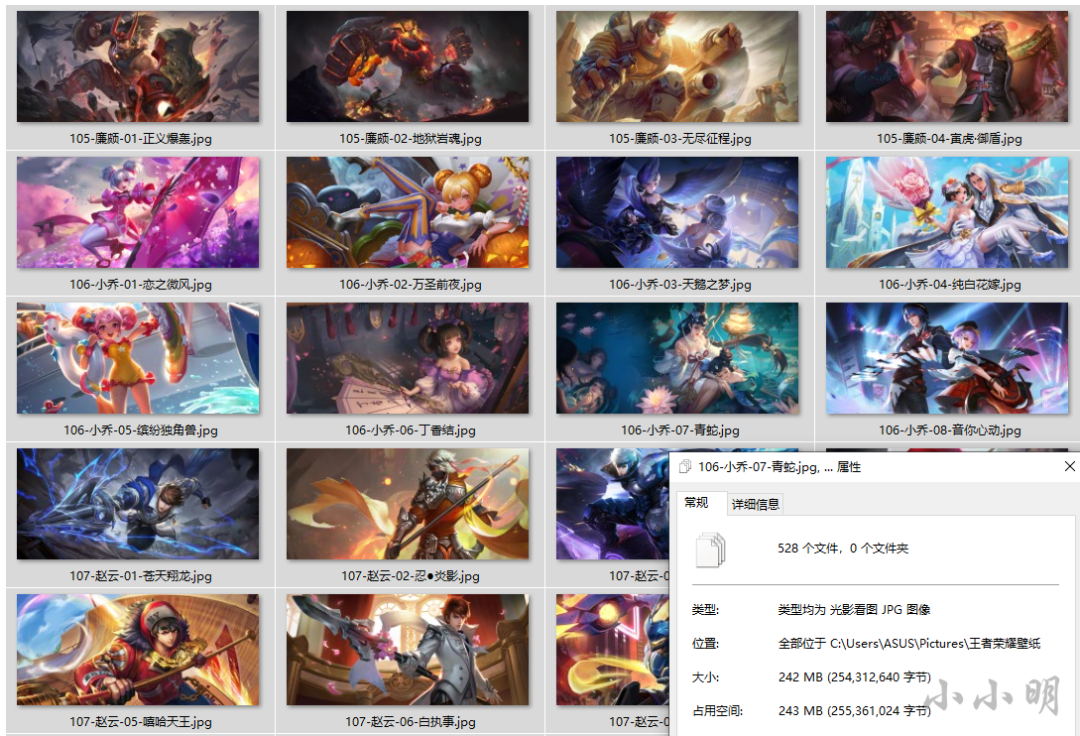
不到40行代码就实现了在30秒内下载完200多MB的王者荣耀壁纸。


扫码加好友,加入海归Python编程和人工智能群














 704
704











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









