









关键术语
支持向量(Support Vector)
支持向量机(Support Vector Mechines,SVM)
序列最小优化(Sequential Minimal Optimization,SMO)
核函数(Kernel Function)
超平面(Hyperplane)
分隔超平面(Separating hyperplane)
点到分隔面的距离为间隔(margin)
相关公式
分隔超平面的形式写成:
wτx+b
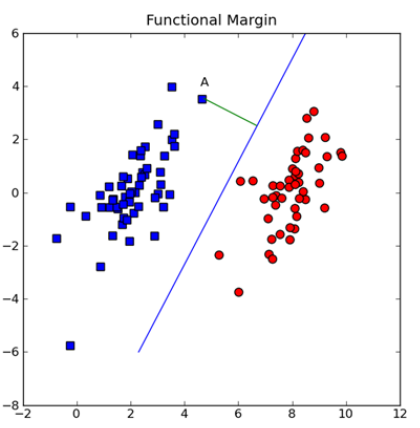
要计算点A到分隔超平面的距离就必须给出点到分隔超平面的法线的长度,该值为:
|wτx+b|∥w∥
当计算点到分隔面的距离并确定分割面的放置位置时,间隔通过
label∗(wτx+b)
,表示点到分隔面的函数间隔;
label∗(wτx+b)⋅1∥w∥
,表示点到分隔面的几何间隔。
如果数据点处于+1类并且离分隔超平面很远的位置时
wτx+b
会是一个很大的正数,同时
label∗(wτx+b)
也是一个很大的正数;
如果数据点处于-1类并且离分隔超平面很远的位置时
wτx+b
也会是一个很大的正数,同时
label∗(wτx+b)
也是一个很大的正数;
目标:找出分类器定义中的w和b。
所以要找到最小间隔的数据点,即支持向量,找到最小间隔的数据点,就要对该间隔最大化,表示为:
令所有支持向量的 label∗(wτx+b) 都为1,可以通过求 ∥w∥−1 的最大值来得到最终解。
该问题转化为带约束条件的最优化问题,这里的约束条件就是:
label∗(wτx+b)≥1.0
。对于这类优化问题,有一个非常著名的求解方法,就是拉格朗日乘子法。
因此可以将超平面写成数据点的形式:
其中 ⟨x(i),x(j)⟩ 表示 x(i),x(j) 两个向量的内积。
上面大公式的约束条件为:
α≥0 ,和 ∑mi=1αi⋅label(i)=0 ;
数据必须是100%线性可分。
因为数据并不那么干净,引入松弛变量,来允许有些数据点可以处于分隔面的错误一侧,这样优化目标保持不变,此时新的约束条件变为:
c≥α≥0 ,和 ∑mi=1αi⋅label(i)=0 ;
c
用来控制“最大化间隔”和“保证大部分点的函数间隔小于1.0”这两个目标的权重。可以调节
一旦求出了所有的alpha,那么分隔超平面就可以通过这些alpha来表达。SVM的主要工作就是求解这些alpha。
SMO(Sequential Minimal Optimization)算法
目标是求出一系列的alpha和b,一旦求出这些alpha就很容易计算出权重向量w并得到分隔超平面。
SMO算法的工作原理:每次循环中选择两个alpha进行优化处理。一旦找到一对合适的alpha,就增大一个同时减小另一个。而“合适”必须符合以下条件:
1. 两个alpha必须在间隔边界之外;
2. 两个alpha还没有进行过区间化处理或者不在边界上。
《Mechine Learning in Action》中简化版的SMO算法代码解读:svmLiA.py
'''
Created on 2016年10月10日
支持向量机练习
@author: laizhiwen
'''
import numpy as np
def loadDataSet(fileName):
dataMat = []; labelMat = []
fr = open(fileName)
for line in fr.readlines():
lineArr = line.strip().split('\t')
dataMat.append([float(lineArr[0]), float(lineArr[1])])
labelMat.append(float(lineArr[2]))
return dataMat,labelMat
'''
i:第一个alpha的下标
m:所有alpha的数目
随机产生不等于输入值i的数
'''
def selectJrand(i,m):
j=i
while (j==i):
j = int(np.random.uniform(0,m))
return j
'''
调整大于H而小于L的alpha值
'''
def clipAlpha(aj,H,L):
if aj > H:
aj = H
if L > aj:
aj = L
return aj
'''
dataMatIn:样本集
classLabels:每一条样本数据对应的分类集
C: 常数
toler: 容错率
maxIter:迭代次数
'''
def smoSimple(dataMatIn, classLabels, C, toler, maxIter):
dataMatrix = np.mat(dataMatIn);
labelMat = np.mat(classLabels).transpose()
b = 0
m,n = np.shape(dataMatrix)
alphas = np.mat(np.zeros((m,1)))
iter = 0
while (iter < maxIter):
alphaPairsChanged = 0 #记录优化alpha值是否有效
for i in range(m):
#矩阵alphas,labelMat相乘得到一个m行1列矩阵,因为都是m行单列矩阵,对应位置的元素相乘重新组成一个新的m行单列矩阵
#fXi是预测的类别,即预测的结果
fXi = float(np.multiply(alphas,labelMat).T * (dataMatrix*dataMatrix[i,:].T)) + b
Ei = fXi - float(labelMat[i]) #误差 = 预测结果-真实结果,如果Ei很大就可以对alpha进行优化
#alpha不能等于0或C。如果if中等于0和C的话,那么它们就已经在边界上了,因而不能再减小和增大,也就不能再优化
if ((labelMat[i]*Ei < -toler) and (alphas[i] < C)) or \
((labelMat[i]*Ei > toler) and (alphas[i] > 0)):
j = selectJrand(i,m) #随机选择第二格alpha的值
#fXj是第二个alpha的误差,计算方法同上
fXj = float(np.multiply(alphas,labelMat).T*(dataMatrix*dataMatrix[j,:].T)) + b
Ej = fXj - float(labelMat[j])
alphaIold = alphas[i].copy()
alphaJold = alphas[j].copy()
#将alpha[j]调整到0和C之间,L=H则不做改变,直接下一个;
if (labelMat[i] != labelMat[j]):
L = max(0, alphas[j] - alphas[i])
H = min(C, C + alphas[j] - alphas[i])
else:
L = max(0, alphas[j] + alphas[i] - C)
H = min(C, alphas[j] + alphas[i])
if L==H:
print("L==H")
continue
#eta是alpha[j]的最优修改量
eta = 2.0 * dataMatrix[i,:]*dataMatrix[j,:].T - \
dataMatrix[i,:]*dataMatrix[i,:].T - \
dataMatrix[j,:]*dataMatrix[j,:].T
if eta >= 0:
print("eta>=0")
continue #如果eta等于0则跳出本次迭代
alphas[j] -= labelMat[j]*(Ei - Ej)/eta #计算出新的alpha[j]
alphas[j] = clipAlpha(alphas[j],H,L) #调整alpha[j]
#判断alpha[j]是否有轻微改变,是就退出本次循环进行下一次迭代
if (abs(alphas[j] - alphaJold) < 0.00001):
print("j not moving enough")
continue
alphas[i] += labelMat[j]*labelMat[i]*(alphaJold - alphas[j])
#给两个alpha值设置常数项b
b1 = b - Ei- labelMat[i]*(alphas[i]-alphaIold)*dataMatrix[i,:]*dataMatrix[i,:].T - \
labelMat[j]*(alphas[j]-alphaJold)*dataMatrix[i,:]*dataMatrix[j,:].T
b2 = b - Ej- labelMat[i]*(alphas[i]-alphaIold)*dataMatrix[i,:]*dataMatrix[j,:].T - \
labelMat[j]*(alphas[j]-alphaJold)*dataMatrix[j,:]*dataMatrix[j,:].T
if (0 < alphas[i]) and (C > alphas[i]):
b = b1
elif (0 < alphas[j]) and (C > alphas[j]):
b = b2
else:
b = (b1 + b2)/2.0
#如果成行执行到此都没有遇到过continue语句,就已经改变了一堆alpha了
alphaPairsChanged += 1
print("iter: %d i:%d, pairs changed %d" % (iter,i,alphaPairsChanged) )
#判断alpha值是否做了更新,如果做了更新就将iter设置为0,继续执行程序
if (alphaPairsChanged == 0):
iter += 1
else:
iter = 0
print("iteration number: %d" % iter)
return b,alphas
dataArr,labelArr = loadDataSet('E:/4.开发书籍/machinelearninginaction/Ch06/testSet.txt')
print(labelArr)
b,alphas = smoSimple(dataArr, labelArr, 0.6, 0.001, 40)
print(b)
print(alphas[alphas>0])
for i in range(100):
if alphas[i]>0.0:
print(dataArr[i],labelArr[i])至此,SMO算法的基本逻辑已经清晰。















 1382
1382

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









