







一、先说说ArrayList
- ArrayList是List接口的可变数组的实现。
- 实现了所有可选列表操作,并允许包括 null 在内的所有元素。
- 除了实现 List接口外,此类还提供一些方法来操作内部用来存储列表的数组的大小。
- 每个ArrayList实例都有一个容量,该容量是指用来存储列表元素的数组的大小。
- 它总是至少等于列表的大小。
- 随着向ArrayList中不断添加元素,其容量也自动增长。
- 自动增长会带来数据向新数组的重新拷贝,因此,如果可预知数据量的多少,可在构造ArrayList时指定其容量。
二、ArrayList比较常用实现
对于ArrayList而言,它实现List接口、底层使用数组保存所有元素。其操作基本上是对数组的操作。下面我们来分析ArrayList的源代码:
(1)底层使用数组
不要惊讶,它就是用数组实现的。
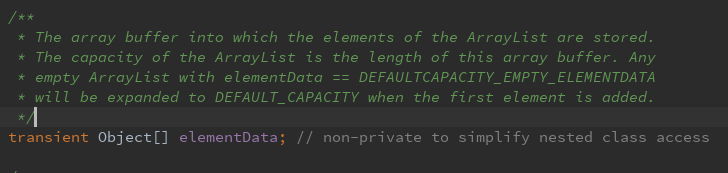
其中transient解释:transient是Java语言的关键字,用来表示一个域不是该对象串行化的一部分。当一个对象被串行化的时候,transient型变量的值不包括在串行化的表示中,然而非transient型的变量是被包括进去的。
(2)构造方法
ArrayList提供了三种方式的构造器
- 可以构造一个默认初始容量为10的空列表、
- 构造一个指定初始容量的空列表
- 构造一个包含指定collection的元素的列表,这些元素按照该collection的迭代器返回它们的顺序排列的。
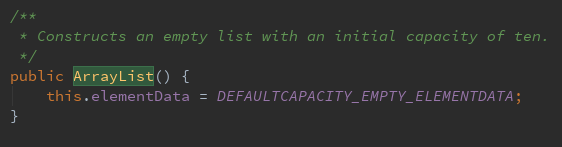
第一种
这里发现它是初始化了一个默认的数组,但是
DEFAULTCAPACITY_EMPTY_ELEMENTDATA这个东西它定义的时候是空

这里小伙伴都惊呆了
不用怕,java怎么可能犯这样的错误,下面咱们慢慢道来。
第二种

这里就没什么好说的,就是初始化了数组。判断了一下初始化容量是否合法。
第三种
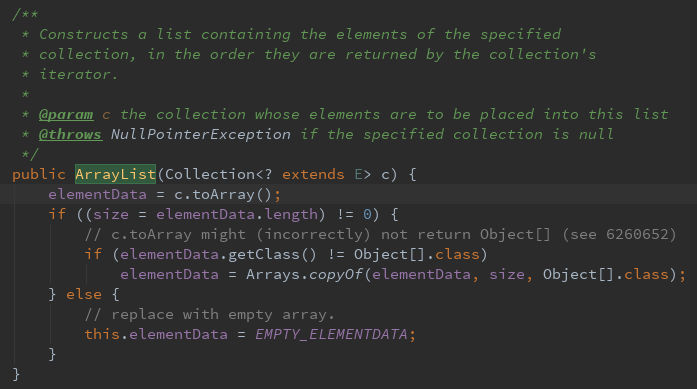
对java不熟悉的小伙伴,可能对Collection有疑惑,知道的就忽略这句话
Collection解释:类集,是一组对象。类集的增加使得许多 java.util中的成员在结构和体系结构上发生根本的改变。它也扩展了包可以被应用的任务范围。(网上查的)
(3)存储数据
ArrayList提供了5种存储数据的方法
1. set(int index, E element)、
2. add(E e)、
3. add(int index, E element)、
4. addAll(Collection<? extends E> c)、
5. addAll(int index, Collection<?extends E> c)- 1
- 2
- 3
- 4
- 5
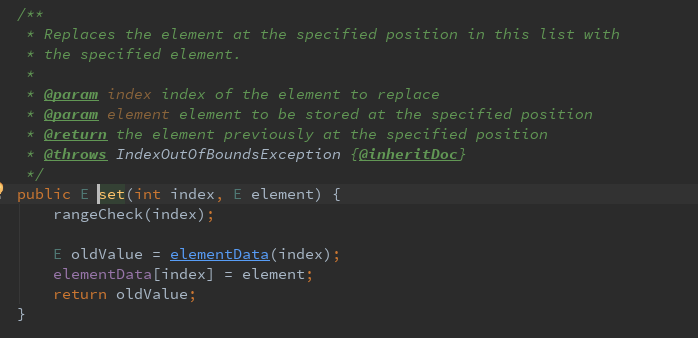
第一种:替换
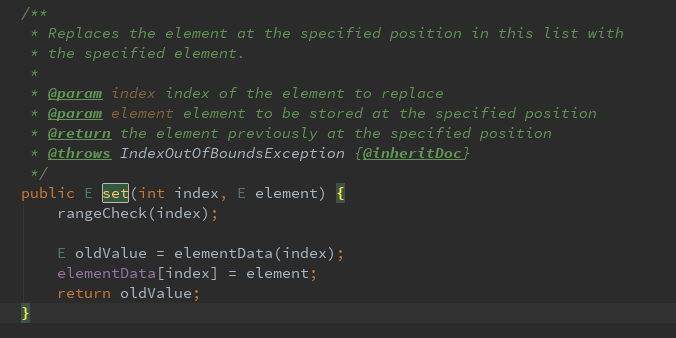
替换指定位置上的元素,并且返回替换之前的指定位置的元素
其中rangeCheck(index)方法是检查指定位置是否大于等于列表长度,如果大于则抛出异常。elemntData(index)方法是返回替换之前的指定位置的元素。
第二种:添加元素
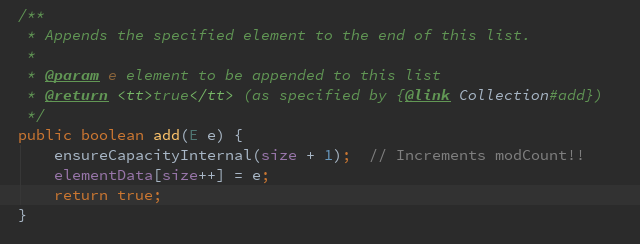
添加元素到此列表的尾部
其中ensureCapacityInternal(size+1)方法:是检查当前容量是否满足需要(查看添加的位置是否已经超出),如果不能够满足当前需要,则需要重新规划容量,并且把已经存在的值拷贝过去。
这里要注意了ensureCapacityInternal方法,在上面说到初始化,为啥初始化的时候是一个空值呢?

从上面的代码可以看到,如果你是第一次使用,并且请求的最小容量小于默认容量,则取默认容量,但是如果一下子你就存储超过默认的容量,比如调用addAll()方法,则不会是默认大小了。
具体实现“容量确认”的逻辑下面再说。
第三种:元素插入到指定位置
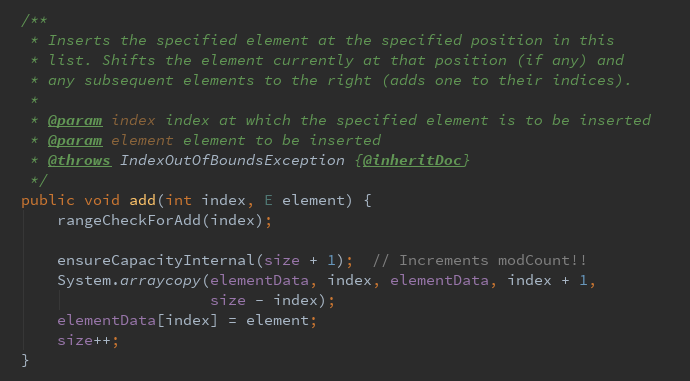
将元素插入到列表中指定的位置 如果当前位置有元素,则向后移动当前位置的元素以及所有后续的元素(将其索引加+1)
其中rangeCheckForAdd(index)方法:检查插入的位置是否大于当前列表的长度,则抛出异常,允许在列表末尾插入元素;ensureCapacityInternal(index)方法:检查当前当前容量是否能够满足需求,如果不满足则重新规划,System.arraycop()方法:将指定位置以及后续的元素向后移动一位。
第四种:添加集合
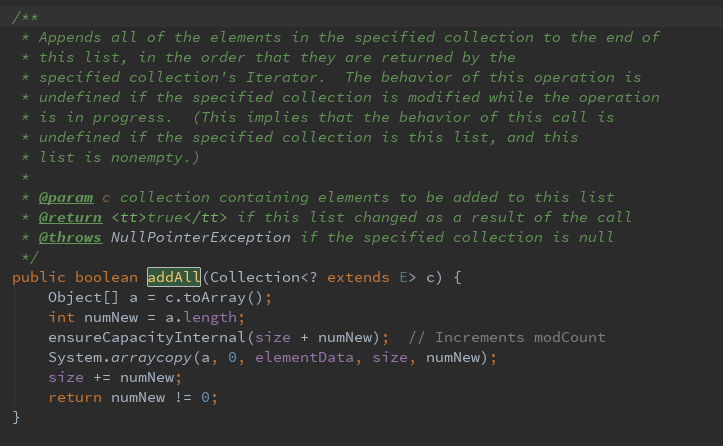
按照collection的迭代器返回的元素顺序,将collection中的所有元素添加到列表尾部。其中ensureCapacityInternal()方法计算容量是否那种需求,system.arraycopy()方法将collection的元素添加到列表尾部。
第五种:添加集合到指定位置
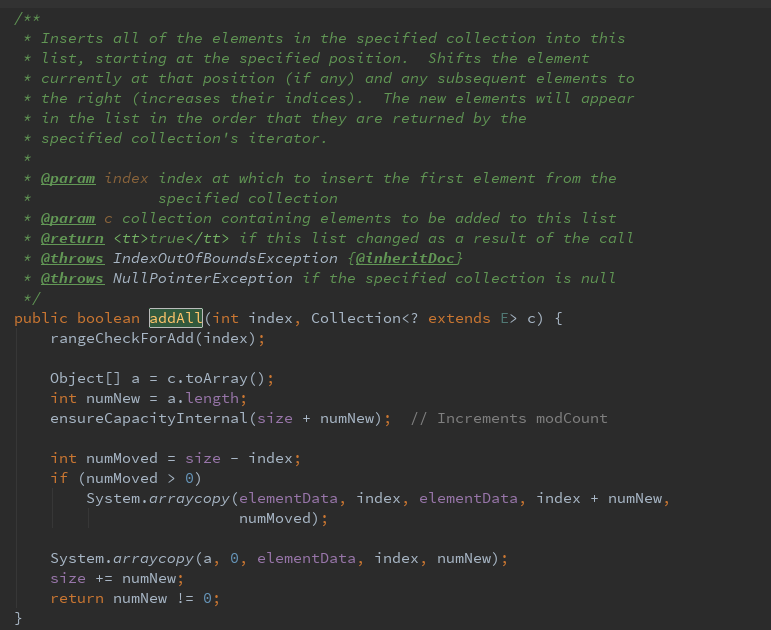
从指定位置开始,将指定collection的所有元素插入次列表中。
其中rangeCheckForAdd(index)方法检测输入位置是否大于列表位置,ensureCapcityIntanal()方法确认容量是否满足需要,如插入位置小于列表长度,则需要将列的指定位置以及后续的元素都移动到插入元素长度以后。
(4)读取
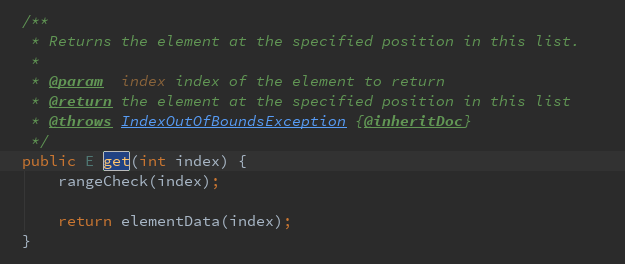
返回指定位置的元素
其中rangeCheck(index)方法,检测位置是否越界
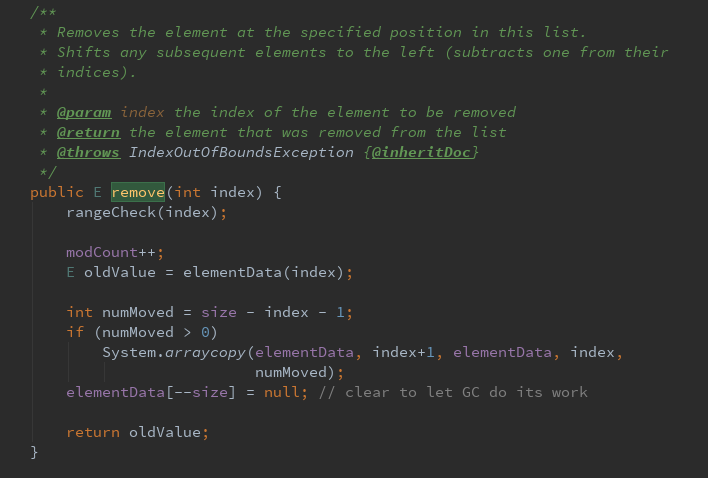
(5)删除
remove(int index)
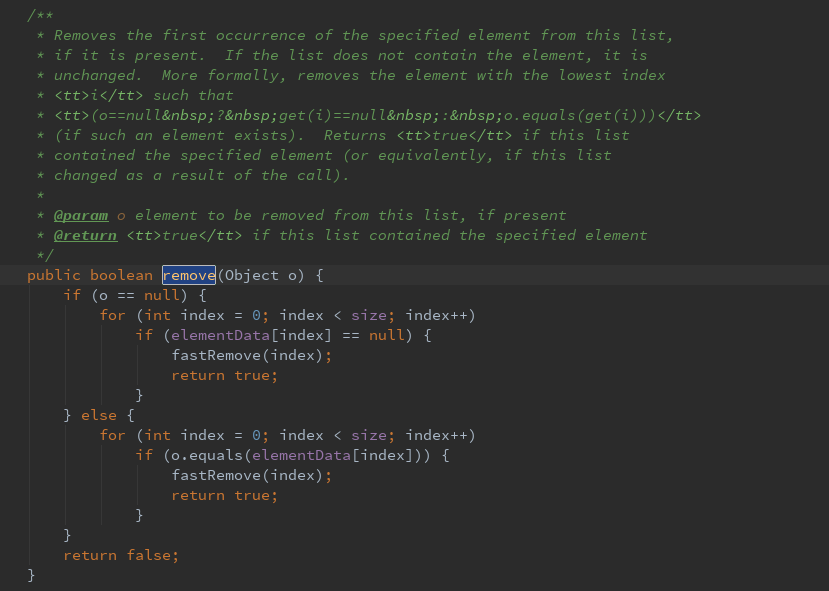
remove(Object o)- 1
- 2
第一种:删除指定位置的元素
第二种:移除此列表首次出现的指定元素(如果存在),ArrayList可以存放重复的元素。由于可以存储Null,所以要分情况处理。其中fastremove()方法:将移除的位置以后的元素向前移动。并且将最后一位置null
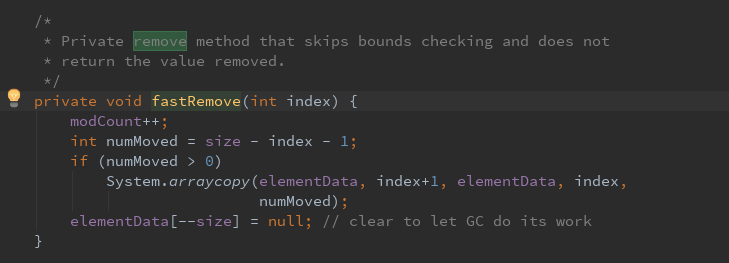
(6)调整数组容量
上面讲到想ArrayList中存储元素的时候,都会坚持添加的元素是否超出当前长度,并且初始化数组长度(所以),以满足添加数据的需求。
数组扩容通过一个公开的方法ensureCapacity(int minCapacity)来实现。在实际添加大量元素前,我也可以使用ensureCapacityIntanal来手动增加ArrayList实例的容量,以减少递增式再分配的数量。

这个方法就是确认内部容量,这里可以初始化数组容量为10,然后在调用ensureExplicitCapacity方法来明确容量
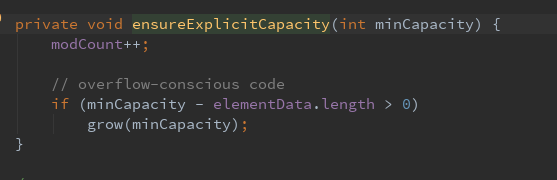
然后判断是否需要扩容
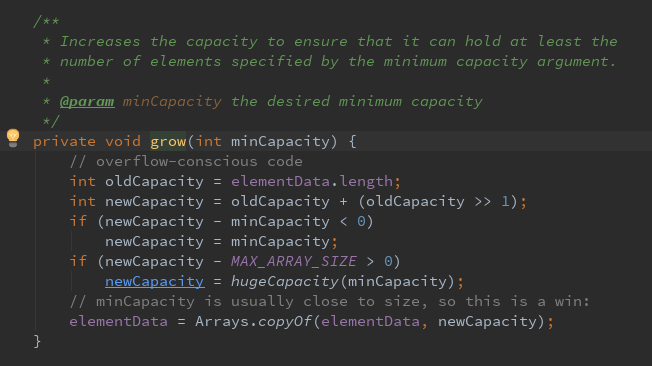
从上述代码中可以看出,数组进行扩容时,会将老数组中的元素重新拷贝一份到新的数组中,每次数组容量的增长都会进行判断,最低都会增长1.5,如果容量过大,则会赋值最大的Interage值。这种操作的代价是很高的,
因此在实际使用时,我们应该尽量避免数组容量的扩张。当我们可预知要保存的元素的多少时,要在构造ArrayList实例时,就指定其容量,以避免数组扩容的发生。或者根据实际需求,通过调用ensureCapacity方法来手动增加ArrayList实例的容量。
ArrayList还给我们提供了将底层数组的容量调整为当前列表保存的实际元素的大小的功能。它可以通过trimToSize方法来实现。代码如下:
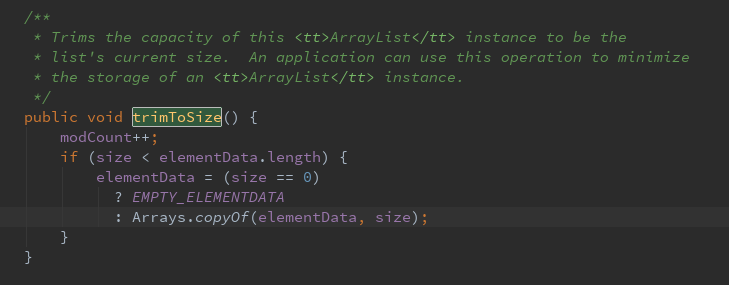
总结:在实际使用过程中,对ArrayList使用要注意以下几点:
- 初始化ArrayList的时候,尽量预先定义好数组数量
- 当操作完一个列表后,最后要确认长度,不然可能会有容量浪费
LinkedList 继承结构
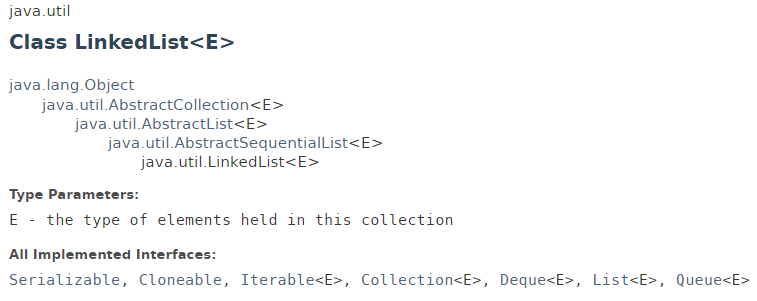
LinkedList 继承自 AbstractSequentialList 接口,同时了还实现了 Deque, Queue 接口。
LinkedList 双向链表实现
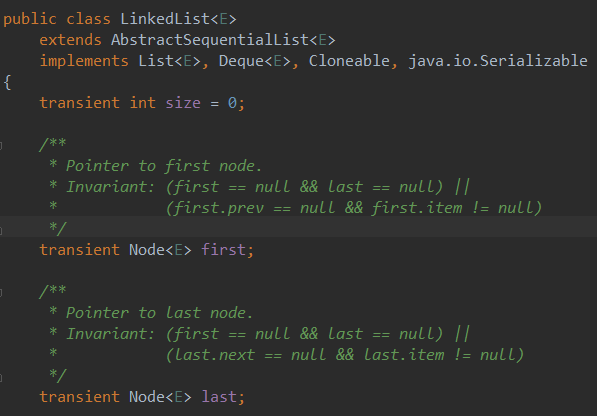
可以看到, LinkedList 的成员变量只有三个:
- 头节点 first
- 尾节点 last
- 容量 size
节点是一个双向节点:
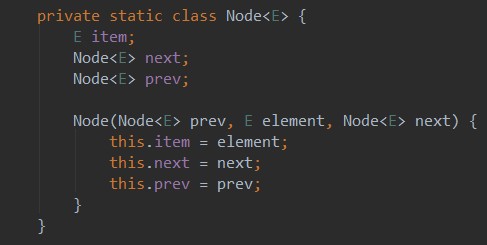
用一副图表示节点:

LinkedList 的方法
1.关键的几个内部方法(头部添加删除,尾部添加删除,获取指定节点,指定节点的添加删除)
//插入到头部
private void linkFirst(E e) {
//获取头节点
final Node<E> f = first;
//新建一个节点,尾部指向之前的 头元素 first
final Node<E> newNode = new Node<>(null, e, f);
//first 指向新建的节点
first = newNode;
//如果之前是空链表,新建的节点 也是最后一个节点
if (f == null)
last = newNode;
else
//原来的第一个节点(现在的第二个)头部指向新建的头结点
f.prev = newNode;
size++;
modCount++;
}
//插入到尾部
void linkLast(E e) {
//获取尾部节点
final Node<E> l = last;
//新建一个节点,头部指向之前的 尾节点 last
final Node<E> newNode = new Node<>(l, e, null);
//last 指向新建的节点
last = newNode;
//如果之前是空链表, 新建的节点也是第一个节点
if (l == null)
first = newNode;
else
//原来的尾节点尾部指向新建的尾节点
l.next = newNode;
size++;
modCount++;
}
//在 指定节点 前插入一个元素,这里假设 指定节点不为 null
void linkBefore(E e, Node<E> succ) {
// 获取指定节点 succ 前面的一个节点
final Node<E> pred = succ.prev;
//新建一个节点,头部指向 succ 前面的节点,尾部指向 succ 节点,数据为 e
final Node<E> newNode = new Node<>(pred, e, succ);
//让 succ 节点头部指向 新建的节点
succ.prev = newNode;
//如果 succ 前面的节点为空,说明 succ 就是第一个节点,那现在新建的节点就变成第一个节点了
if (pred == null)
first = newNode;
else
//如果前面有节点,让前面的节点
pred.next = newNode;
size++;
modCount++;
}
//删除头节点并返回该节点上的数据,假设不为 null
private E unlinkFirst(Node<E> f) {
// 获取数据,一会儿返回
final E element = f.item;
//获取头节点后面一个节点
final Node<E> next = f.next;
//使头节点上数据为空,尾部指向空
f.item = null;
f.next = null; // help GC
//现在头节点后边的节点变成第一个了
first = next;
//如果头节点后面的节点为 null,说明移除这个节点后,链表里没节点了
if (next == null)
last = null;
else
next.prev = null;
size--;
modCount++;
return element;
}
//删除尾部节点并返回,假设不为空
private E unlinkLast(Node<E> l) {
final E element = l.item;
//获取倒数第二个节点
final Node<E> prev = l.prev;
//尾节点数据、尾指针置为空
l.item = null;
l.prev = null; // help GC
//现在倒数第二变成倒数第一了
last = prev;
if (prev == null)
first = null;
else
prev.next = null;
size--;
modCount++;
return element;
}
//删除某个指定节点
E unlink(Node<E> x) {
// 假设 x 不为空
final E element = x.item;
//获取指定节点前面、后面的节点
final Node<E> next = x.next;
final Node<E> prev = x.prev;
//如果前面没有节点,说明 x 是第一个
if (prev == null) {
first = next;
} else {
//前面有节点,让前面节点跨过 x 直接指向 x 后面的节点
prev.next = next;
x.prev = null;
}
//如果后面没有节点,说 x 是最后一个节点
if (next == null) {
last = prev;
} else {
//后面有节点,让后面的节点指向 x 前面的
next.prev = prev;
x.next = null;
}
x.item = null;
size--;
modCount++;
return element;
}
//获取指定位置的节点
Node<E> node(int index) {
// 假设指定位置有元素
//二分一下,如果小于 size 的一半,从头开始遍历
if (index < (size >> 1)) {
Node<E> x = first;
for (int i = 0; i < index; i++)
x = x.next;
return x;
} else {
//大于 size 一半,从尾部倒着遍历
Node<E> x = last;
for (int i = size - 1; i > index; i--)
x = x.prev;
return x;
}
}
这些内部方法实现了对 链表节点的 基本修改操作,每次操作都只要修改前后节点的指针,时间复杂度为 O(1)。
很多公开方法都是通过调用它们实现的。
2.公开的添加方法:
//普通的在尾部添加元素
public boolean add(E e) {
linkLast(e);
return true;
}
//在指定位置添加元素
public void add(int index, E element) {
checkPositionIndex(index);
//指定位置也有可能是在尾部
if (index == size)
linkLast(element);
else
linkBefore(element, node(index));
}
//添加一个集合的元素
public boolean addAll(Collection<? extends E> c) {
return addAll(size, c);
}
public boolean addAll(int index, Collection<? extends E> c) {
checkPositionIndex(index);
//把 要添加的集合转成一个 数组
Object[] a = c.toArray();
int numNew = a.length;
if (numNew == 0)
return false;
//创建两个节点,分别指向要插入位置前面和后面的节点
Node<E> pred, succ;
//要添加到尾部
if (index == size) {
succ = null;
pred = last;
} else {
//要添加到中间, succ 指向 index 位置的节点,pred 指向它前一个
succ = node(index);
pred = succ.prev;
}
//遍历要添加内容的数组
for (Object o : a) {
@SuppressWarnings("unchecked") E e = (E) o;
//创建新节点,头指针指向 pred
Node<E> newNode = new Node<>(pred, e, null);
//如果 pred 为空,说明新建的这个是头节点
if (pred == null)
first = newNode;
else
//pred 指向新建的节点
pred.next = newNode;
//pred 后移一位
pred = newNode;
}
//添加完后需要修改尾指针 last
if (succ == null) {
//如果 succ 为空,说明要插入的位置就是尾部,现在 pred 已经到最后了
last = pred;
} else {
//否则 pred 指向后面的元素
pred.next = succ;
succ.prev = pred;
}
//元素个数增加
size += numNew;
modCount++;
return true;
}
//添加到头部,时间复杂度为 O(1)
public void addFirst(E e) {
linkFirst(e);
}
//添加到尾部,时间复杂度为 O(1)
public void addLast(E e) {
linkLast(e);
}
继承自双端队列的添加方法:
//入栈,其实就是在头部添加元素
public void push(E e) {
addFirst(e);
}
//安全的添加操作,在尾部添加
public boolean offer(E e) {
return add(e);
}
//在头部添加
public boolean offerFirst(E e) {
addFirst(e);
return true;
}
//尾部添加
public boolean offerLast(E e) {
addLast(e);
return true;
}
3.删除方法:
//删除头部节点
public E remove() {
return removeFirst();
}
//删除指定位置节点
public E remove(int index) {
checkElementIndex(index);
return unlink(node(index));
}
//删除包含指定元素的节点,这就得遍历了
public boolean remove(Object o) {
if (o == null) {
//遍历终止条件,不等于 null
for (Node<E> x = first; x != null; x = x.next) {
if (x.item == null) {
unlink(x);
return true;
}
}
} else {
for (Node<E> x = first; x != null; x = x.next) {
if (o.equals(x.item)) {
unlink(x);
return true;
}
}
}
return false;
}
//删除头部元素
public E removeFirst() {
final Node<E> f = first;
if (f == null)
throw new NoSuchElementException();
return unlinkFirst(f);
}
//删除尾部元素
public E removeLast() {
final Node<E> l = last;
if (l == null)
throw new NoSuchElementException();
return unlinkLast(l);
}
//删除首次出现的指定元素,从头遍历
public boolean removeFirstOccurrence(Object o) {
return remove(o);
}
//删除最后一次出现的指定元素,倒过来遍历
public boolean removeLastOccurrence(Object o) {
if (o == null) {
for (Node<E> x = last; x != null; x = x.prev) {
if (x.item == null) {
unlink(x);
return true;
}
}
} else {
for (Node<E> x = last; x != null; x = x.prev) {
if (o.equals(x.item)) {
unlink(x);
return true;
}
}
}
return false;
}
继承自双端队列的删除方法:
public E pop() {
return removeFirst();
}
public E pollFirst() {
final Node<E> f = first;
return (f == null) ? null : unlinkFirst(f);
}
public E pollLast() {
final Node<E> l = last;
return (l == null) ? null : unlinkLast(l);
}
清除全部元素其实只需要把首尾都置为 null, 这个链表就已经是空的,因为无法访问元素。
但是为了避免浪费空间,需要把中间节点都置为 null:
public void clear() {
for (Node<E> x = first; x != null; ) {
Node<E> next = x.next;
x.item = null;
x.next = null;
x.prev = null;
x = next;
}
first = last = null;
size = 0;
modCount++;
}
3.公开的修改方法,只有一个 set :
//set 很简单,找到这个节点,替换数据就好了
public E set(int index, E element) {
checkElementIndex(index);
Node<E> x = node(index);
E oldVal = x.item;
x.item = element;
return oldVal;
}
4.公开的查询方法:
//挨个遍历,获取第一次出现位置
public int indexOf(Object o) {
int index = 0;
if (o == null) {
for (Node<E> x = first; x != null; x = x.next) {
if (x.item == null)
return index;
index++;
}
} else {
for (Node<E> x = first; x != null; x = x.next) {
if (o.equals(x.item))
return index;
index++;
}
}
return -1;
}
//倒着遍历,查询最后一次出现的位置
public int lastIndexOf(Object o) {
int index = size;
if (o == null) {
for (Node<E> x = last; x != null; x = x.prev) {
index--;
if (x.item == null)
return index;
}
} else {
for (Node<E> x = last; x != null; x = x.prev) {
index--;
if (o.equals(x.item))
return index;
}
}
return -1;
}
//是否包含指定元素
public boolean contains(Object o) {
return indexOf(o) != -1;
}
//获取指定位置的元素,需要遍历
public E get(int index) {
checkElementIndex(index);
return node(index).item;
}
//获取第一个元素,很快
public E getFirst() {
final Node<E> f = first;
if (f == null)
throw new NoSuchElementException();
return f.item;
}
//获取第一个,同时删除它
public E poll() {
final Node<E> f = first;
return (f == null) ? null : unlinkFirst(f);
}
//也是获取第一个,和 poll 不同的是不删除
public E peek() {
final Node<E> f = first;
return (f == null) ? null : f.item;
}
//长得一样嘛
public E peekFirst() {
final Node<E> f = first;
return (f == null) ? null : f.item;
}
//最后一个元素,也很快
public E getLast() {
final Node<E> l = last;
if (l == null)
throw new NoSuchElementException();
return l.item;
}
public E peekLast() {
final Node<E> l = last;
return (l == null) ? null : l.item;
}
关键方法介绍完了,接下来是内部实现的迭代器,需要注意的是 LinkedList 实现了一个倒序迭代器 DescendingIterator;还实现了一个 ListIterator ,名叫 ListItr
迭代器
1.DescendingIterator 倒序迭代器
//很简单,就是游标直接在 迭代器尾部,然后颠倒黑白,说是向后遍历,实际是向前遍历
private class DescendingIterator implements Iterator<E> {
private final ListItr itr = new ListItr(size());
public boolean hasNext() {
return itr.hasPrevious();
}
public E next() {
return itr.previous();
}
public void remove() {
itr.remove();
}
}
2. ListItr 操作基本都是调用的内部关键方法,没什么特别的
private class ListItr implements ListIterator<E> {
private Node<E> lastReturned;
private Node<E> next;
private int nextIndex;
private int expectedModCount = modCount;
ListItr(int index) {
// 二分遍历,指定游标位置
next = (index == size) ? null : node(index);
nextIndex = index;
}
public boolean hasNext() {
return nextIndex < size;
}
public E next() {
checkForComodification();
if (!hasNext())
throw new NoSuchElementException();
//很简单,后移一位
lastReturned = next;
next = next.next;
nextIndex++;
return lastReturned.item;
}
public boolean hasPrevious() {
return nextIndex > 0;
}
public E previous() {
checkForComodification();
if (!hasPrevious())
throw new NoSuchElementException();
lastReturned = next = (next == null) ? last : next.prev;
nextIndex--;
return lastReturned.item;
}
public int nextIndex() {
return nextIndex;
}
public int previousIndex() {
return nextIndex - 1;
}
public void remove() {
checkForComodification();
if (lastReturned == null)
throw new IllegalStateException();
Node<E> lastNext = lastReturned.next;
unlink(lastReturned);
if (next == lastReturned)
next = lastNext;
else
nextIndex--;
lastReturned = null;
expectedModCount++;
}
public void set(E e) {
if (lastReturned == null)
throw new IllegalStateException();
checkForComodification();
lastReturned.item = e;
}
public void add(E e) {
checkForComodification();
lastReturned = null;
if (next == null)
linkLast(e);
else
linkBefore(e, next);
nextIndex++;
expectedModCount++;
}
public void forEachRemaining(Consumer<? super E> action) {
Objects.requireNonNull(action);
while (modCount == expectedModCount && nextIndex < size) {
action.accept(next.item);
lastReturned = next;
next = next.next;
nextIndex++;
}
checkForComodification();
}
final void checkForComodification() {
if (modCount != expectedModCount)
throw new ConcurrentModificationException();
}
}
还有个 LLSpliterator 继承自 Spliterator, JDK 8 出来的新东东,这里暂不研究
Spliterator 是 Java 8 引入的新接口,顾名思义,Spliterator 可以理解为 Iterator 的 Split 版本(但用途要丰富很多)。
使用 Iterator 的时候,我们可以顺序地遍历容器中的元素,使用 Spliterator 的时候,我们可以将元素分割成多份,分别交于不于的线程去遍历,以提高效率。
使用 Spliterator 每次可以处理某个元素集合中的一个元素 — 不是从 Spliterator 中获取元素,而是使用 tryAdvance() 或 forEachRemaining() 方法对元素应用操作。
但 Spliterator 还可以用于估计其中保存的元素数量,而且还可以像细胞分裂一样变为一分为二。这些新增加的能力让流并行处理代码可以很方便地将工作分布到多个可用线程上完成。
总结
吐个槽,估计是很多人维护的,有些方法功能代码完全一样
比如:
private boolean isElementIndex(int index) {
return index >= 0 && index < size;
}
private boolean isPositionIndex(int index) {
return index >= 0 && index <= size;
}
LinkedList 特点
- 双向链表实现
- 元素时有序的,输出顺序与输入顺序一致
- 允许元素为 null
- 所有指定位置的操作都是从头开始遍历进行的
- 和 ArrayList 一样,不是同步容器
并发访问注意事项
linkedList 和 ArrayList 一样,不是同步容器。所以需要外部做同步操作,或者直接用 Collections.synchronizedList 方法包一下,最好在创建时就报一下:
List list = Collections.synchronizedList(new LinkedList(...));
LinkedList 的迭代器都是 fail-fast 的: 如果在并发环境下,其他线程使用迭代器以外的方法修改数据,会导致 ConcurrentModificationException.
ArrayList VS LinkedList
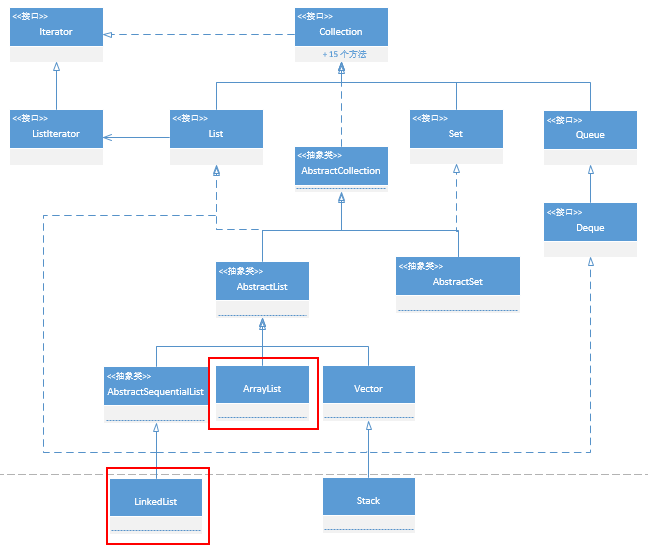
ArrayList
- 基于数组,在数组中搜索和读取数据是很快的。因此 ArrayList 获取数据的时间复杂度是O(1);
- 但是添加、删除时该元素后面的所有元素都要移动,所以添加/删除数据效率不高;
- 另外其实还是有容量的,每次达到阈值需要扩容,这个操作比较影响效率。
LinkedList
- 基于双端链表,添加/删除元素只会影响周围的两个节点,开销很低;
- 只能顺序遍历,无法按照索引获得元素,因此查询效率不高;
- 没有固定容量,不需要扩容;
- 需要更多的内存,如文章开头图片所示 LinkedList 每个节点中需要多存储前后节点的信息,占用空间更多些。
Vector 层次结构图
先来看看ArrayList的定义
public class Vector<E> extends AbstractList<E> implements List<E>,RandomAccess, Cloneable, java.io.Serializable
从中我们可以了解到
- Vector<E>:说明它支持泛型
extends AbstractList<E> implements List<E>:说明它继承了extends AbstractList<E>,并实现了implements List<E>。
implements RandomAccess:表明其支持快速(通常是固定时间)随机访问。此接口的主要目的是允许一般的算法更改其行为,从而在将其应用到随机或连续访问列表时能提供良好的性能。下面是JDK1.8中对RandomAccess的介绍:
Marker interface used by <tt>List</tt> implementations to indicate that they support fast (generally constant time) random access. The primary purpose of this interface is to allow generic algorithms to alter their behavior to provide good performance when applied to either random or sequential access lists.- 1
- implements Cloneable:表明其可以调用clone()方法来返回实例的field-for-field拷贝。
- implements java.io.Serializable:表明该类是可以序列化的。
但继承实现信息还不够完整,我建议大家以后查看一个类的继承实现关系的时候,使用类结构层次图。

如何查看类层次结构图可以参考我写过的一篇文章:
全局变量
/**
* 保存vector中元素的数组。vector的容量是数组的长度,数组的长度最小值为vector的元素个数。
*
* 任何在vector最后一个元素之后的数组元素是null。
*
* @serial
*/
protected Object[] elementData;
/**
* vector中实际的元素个数。
*
* @serial
*/
protected int elementCount;
/**
* vector需要自动扩容时增加的容量。
*
* 当vector的实际容量elementCount将要大于它的最大容量时,vector自动增加的容量。
*
* 如果capacityIncrement小于或等于0,vector的容量需要增长时将会成倍增长。
* @serial
*/
protected int capacityIncrement;
/**
* 序列版本号
*/
private static final long serialVersionUID = -2767605614048989439L;- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
构造方法
接下来,看Vector提供的构造方法。ArrayList提供了四种构造方法。
1.构造一个指定容量为capacity、自增容量为capacityIncrement的空vector。
/**
* 构造一个指定容量为initialCapacity、自增容量为capacityIncrement的空vector。
*
* @param initialCapacity 初始化容量
* @param capacityIncrement 自增容量
*
* @throws IllegalArgumentException 如果initialCapacity是负数
*/
public Vector(int initialCapacity, int capacityIncrement) {
super();
if (initialCapacity < 0)
throw new IllegalArgumentException("Illegal Capacity: "+
initialCapacity);
this.elementData = new Object[initialCapacity];
this.capacityIncrement = capacityIncrement;
}- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
2.构造一个指定容量为initialCapacity、自增容量为0的空vector。
/**
* 构造一个指定容量为initialCapacity、自增容量为0的空vector。
*
* @param initialCapacity 初始化容量
* @throws IllegalArgumentException 如果initialCapacity是负数
*/
public Vector(int initialCapacity) {
this(initialCapacity, 0);
}- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
3.构造一个指定容量为10、自增容量为0的空vector。
/**
* 构造一个指定容量为10、自增容量为0的空vector。
*/
public Vector() {
this(10);
}- 1
- 2
- 3
- 4
- 5
- 6
4.使用指定的Collection构造vector。
/**
* 构造一个包含特定Collection中所有元素的vector。
*
* @param c 用来构造vector的Collection
*
* @throws NullPointerException 用来构造vector的Collection是null
*
* @since 1.2
*/
public Vector(Collection<? extends E> c) {
elementData = c.toArray();
elementCount = elementData.length;
// c.toArray might (incorrectly) not return Object[] (see 6260652)
if (elementData.getClass() != Object[].class)
elementData = Arrays.copyOf(elementData, elementCount, Object[].class);
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
方法
copyInto
/**
* 将vector中的所有元素拷贝到指定的数组anArray中
*
* @param anArray 指定的数组anArray,用来存放vector中的所有元素
*
* @throws NullPointerException 如果指定的数组anArray为null
* @throws IndexOutOfBoundsException 如果指定的数组anArray的容量小于vector的元素个数
* @throws ArrayStoreException 如果vector不能被拷贝到anArray中
* @see #toArray(Object[])
*/
public synchronized void copyInto(Object[] anArray) {
System.arraycopy(elementData, 0, anArray, 0, elementCount);
}- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
trimToSize()
/**
* 将底层数组的容量调整为当前vector实际元素的个数,来释放空间。
*/
public synchronized void trimToSize() {
modCount++;
int oldCapacity = elementData.length;
当实际大小小于底层数组的长度
if (elementCount < oldCapacity) {
//将底层数组的长度调整为实际大小
elementData = Arrays.copyOf(elementData, elementCount);
}
}- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
ensureCapacity
该方法的实现和ArrayList中大致相同。不同的是在第一次扩容时,vector的逻辑是: newCapacity = oldCapacity + ((capacityIncrement > 0) ?
capacityIncrement : oldCapacity);
即如果capacityIncrement>0,就加capacityIncrement,如果不是就增加一倍。
而ArrayList的逻辑是: newCapacity = oldCapacity + (oldCapacity >> 1);
即增加现有的一半。
/**
* 增加vector容量
* 如果vector当前容量小于至少需要的容量,它的容量将增加。
*
* 新的容量将在旧的容量的基础上加上capacityIncrement,除非capacityIncrement小于等于0,在这种情况下,容量将会增加一倍。
*
* 增加后,如果新的容量还是小于至少需要的容量,那就将容量扩容至至少需要的容量。
*
* @param minCapacity 至少需要的容量
*/
public synchronized void ensureCapacity(int minCapacity) {
if (minCapacity > 0) {
modCount++;
ensureCapacityHelper(minCapacity);
}
}
/**
* ensureCapacity()方法的unsynchronized实现。
*
* ensureCapacity()是同步的,它可以调用本方法来扩容,而不用承受同步带来的消耗
*
* @see #ensureCapacity(int)
*/
private void ensureCapacityHelper(int minCapacity) {
// 如果至少需要的容量 > 数组缓冲区当前的长度,就进行扩容
if (minCapacity - elementData.length > 0)
grow(minCapacity);
}
/**
* 分派给arrays的最大容量
* 为什么要减去8呢?
* 因为某些VM会在数组中保留一些头字,尝试分配这个最大存储容量,可能会导致array容量大于VM的limit,最终导致OutOfMemoryError。
*/
private static final int MAX_ARRAY_SIZE = Integer.MAX_VALUE - 8;
/**
* 扩容,保证vector至少能存储minCapacity个元素。
* 首次扩容时,newCapacity = oldCapacity + ((capacityIncrement > 0) ?capacityIncrement : oldCapacity);即如果capacityIncrement>0,就加capacityIncrement,如果不是就增加一倍。
*
* 如果第一次扩容后,容量还是小于minCapacity,就直接将容量增为minCapacity。
*
* @param minCapacity 至少需要的容量
*/
private void grow(int minCapacity) {
// 获取当前数组的容量
int oldCapacity = elementData.length;
// 扩容。新的容量=当前容量+当前容量/2.即将当前容量增加一倍
int newCapacity = oldCapacity + ((capacityIncrement > 0) ?
capacityIncrement : oldCapacity);
//如果扩容后的容量还是小于想要的最小容量
if (newCapacity - minCapacity < 0)
///将扩容后的容量再次扩容为想要的最小容量
newCapacity = minCapacity;
///如果扩容后的容量大于临界值,则进行大容量分配
if (newCapacity - MAX_ARRAY_SIZE > 0)
newCapacity = hugeCapacity(minCapacity);
elementData = Arrays.copyOf(elementData, newCapacity);
}
/**
* 进行大容量分配
*/
private static int hugeCapacity(int minCapacity) {
//如果minCapacity<0,抛出异常
if (minCapacity < 0) // overflow
throw new OutOfMemoryError();
//如果想要的容量大于MAX_ARRAY_SIZE,则分配Integer.MAX_VALUE,否则分配MAX_ARRAY_SIZE
return (minCapacity > MAX_ARRAY_SIZE) ?
Integer.MAX_VALUE :
MAX_ARRAY_SIZE;
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
setSize
/**
* 设置vector的容量。
*
* 如果newSize大于现有vector的元素的个数,则将vector的大小设置为newSize。如果newSize小于现有vector的元素的个数,则将vector中索引在newSize(包括newSize)之后的元素都置为null。
*
* @param newSize 设置容量后的新大小
* @throws ArrayIndexOutOfBoundsException 如果newSize为负数
*/
public synchronized void setSize(int newSize) {
modCount++;
if (newSize > elementCount) {
ensureCapacityHelper(newSize);
} else {
for (int i = newSize ; i < elementCount ; i++) {
elementData[i] = null;
}
}
elementCount = newSize;
}- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
capacity
/**
* 返回当前vector的实际容量。
*
* @return 返回当前vector的实际容量。
*/
public synchronized int capacity() {
return elementData.length;
}- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
size
/**
* 查看vector中元素的实际个数。
*
* @return vector中元素的实际个数
*/
public synchronized int size() {
return elementCount;
}- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
isEmpty
/**
* 检测vector中是否有元素.
*
* @return 如果没有元素,返回true
*/
public synchronized boolean isEmpty() {
return elementCount == 0;
}- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
elements
/**
* 返回vector中所有元素的Enumeration。
*
* Enumeration提供用于遍历vector中所有元素的方法
*
* @return 返回vector中所有元素的Enumeration。
* @see Iterator
*/
public Enumeration<E> elements() {
return new Enumeration<E>() {
int count = 0;
public boolean hasMoreElements() {
return count < elementCount;
}
public E nextElement() {
synchronized (Vector.this) {
if (count < elementCount) {
return elementData(count++);
}
}
throw new NoSuchElementException("Vector Enumeration");
}
};
}- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
contains
/**
* 查看vector中是否包含元素o。
*
* @param o 元素o
* @return vector中是否包含元素o
*/
public boolean contains(Object o) {
return indexOf(o, 0) >= 0;
}- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
indexOf
/**
* 正向遍历vector,返回第一次出现元素o的索引。
*
* 如果vector中不包含元素o,返回-1
*
* @param o 需要查找的元素
* @return 返回第一次出现元素o的索引。如果vector中不包含元素o,返回-1
*/
public int indexOf(Object o) {
return indexOf(o, 0);
}- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
indexOf
/**
* 从索引为index的位置正向遍历vector,返回第一次出现元素o的索引。
*
* 如果vector中不包含元素o,返回-1
*
* @param o 想要查找的元素
* @param index 开始查找位置的索引
* @return 返回第一次出现元素o的索引。如果vector中不包含元素o,返回-1
* @throws IndexOutOfBoundsException 如果index为负数
* @see Object#equals(Object)
*/
public synchronized int indexOf(Object o, int index) {
if (o == null) {
for (int i = index ; i < elementCount ; i++)
if (elementData[i]==null)
return i;
} else {
for (int i = index ; i < elementCount ; i++)
if (o.equals(elementData[i]))
return i;
}
return -1;
}- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
lastIndexOf
/**
* 逆向遍历vector,返回第一次出现元素o的索引。
*
* 如果vector中不包含元素o,返回-1
*
* @param o 需要查找的元素
* @return 返回第一次出现元素o的索引。如果vector中不包含元素o,返回-1
*/
public synchronized int lastIndexOf(Object o) {
return lastIndexOf(o, elementCount-1);
}- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
lastIndexOf
/**
* 从索引为index的位置逆向遍历vector,返回第一次出现元素o的索引。
*
* 如果vector中不包含元素o,返回-1
*
* @param o 想要查找的元素
* @param index 开始查找位置的索引
* @return 返回第一次出现元素o的索引。如果vector中不包含元素o,返回-1
* @throws IndexOutOfBoundsException 如果index大于或等于vector的大小
*/
public synchronized int lastIndexOf(Object o, int index) {
if (index >= elementCount)
throw new IndexOutOfBoundsException(index + " >= "+ elementCount);
if (o == null) {
for (int i = index; i >= 0; i--)
if (elementData[i]==null)
return i;
} else {
for (int i = index; i >= 0; i--)
if (o.equals(elementData[i]))
return i;
}
return -1;
}- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
elementAt
/**
* 返回索引为index的元素。
*
* @param index 查找的元素的索引
* @return 索引为index的元素
* @throws ArrayIndexOutOfBoundsException 索引小于0或大于vector的大小
*/
public synchronized E elementAt(int index) {
if (index >= elementCount) {
throw new ArrayIndexOutOfBoundsException(index + " >= " + elementCount);
}
return elementData(index);
}- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
firstElement
/**
* 返回vector的第一个元素
*
* @return vector的第一个元素
* @throws NoSuchElementException 如果vector没有元素
*/
public synchronized E firstElement() {
if (elementCount == 0) {
throw new NoSuchElementException();
}
return elementData(0);
}- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
lastElement
/**
* 返回vector的最后一个元素
*
* @return vector的最后一个元素
* @throws NoSuchElementException 如果vector没有元素
*/
public synchronized E lastElement() {
if (elementCount == 0) {
throw new NoSuchElementException();
}
return elementData(elementCount - 1);
}- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
setElementAt
/**
* 替换索引为index的元素为指定的对象0
*
* 索引必须大于等于0而且小于vector的大小
*
* @param obj 指定的对象0
* @param index 被替换元素的索引
* @throws ArrayIndexOutOfBoundsException 索引必须小于等于0或者大于vector的大小
*/
public synchronized void setElementAt(E obj, int index) {
if (index >= elementCount) {
throw new ArrayIndexOutOfBoundsException(index + " >= " +
elementCount);
}
elementData[index] = obj;
}- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
removeElementAt
/**
* 删除在特定索引index的元素。在索引index之后的元素左移,索引减1。
*
* 索引index大小必须大于等于0且小于vector的大小
*
* @param index 需要删除的元素的索引
* @throws ArrayIndexOutOfBoundsException 索引index小于0或大于vector的大小
*/
public synchronized void removeElementAt(int index) {
modCount++;
if (index >= elementCount) {
throw new ArrayIndexOutOfBoundsException(index + " >= " +
elementCount);
}
else if (index < 0) {
throw new ArrayIndexOutOfBoundsException(index);
}
int j = elementCount - index - 1;
if (j > 0) {
System.arraycopy(elementData, index + 1, elementData, index, j);
}
elementCount--;
elementData[elementCount] = null; /* to let gc do its work */
}- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
insertElementAt
/**
* 在指定索引index处插入指定对象obj。索引大于或等于index的元素右移,索引+1。
* 索引必须大于等于0而且小于等于vector的大小。
*
* @param obj 指定对象
* @param index 指定索引
* @throws ArrayIndexOutOfBoundsException 索引小于0或者大于vector的大小
*/
public synchronized void insertElementAt(E obj, int index) {
modCount++;
if (index > elementCount) {
throw new ArrayIndexOutOfBoundsException(index
+ " > " + elementCount);
}
ensureCapacityHelper(elementCount + 1);
System.arraycopy(elementData, index, elementData, index + 1, elementCount - index);
elementData[index] = obj;
elementCount++;
}- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
addElement
/**
* 在vector的末尾添加指定元素obj,vector大小+1. 如果容量大与现有容量,要扩充容量。
*
* @param obj 要添加的对象
*/
public synchronized void addElement(E obj) {
modCount++;
ensureCapacityHelper(elementCount + 1);
elementData[elementCount++] = obj;
}- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
removeElement
/**
* 正向遍历vector,当指定元素obj第一次出现时,删除它,它之后的元素左移一位。
*
* @param obj 要删除的元素
* @return 如果指定对象obj在vector存在,返回true。否则返回false。
*/
public synchronized boolean removeElement(Object obj) {
modCount++;
int i = indexOf(obj);
if (i >= 0) {
removeElementAt(i);
return true;
}
return false;
}- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
removeAllElements
/**
* 删除vector中所有元素,并将大小置为0。
*/
public synchronized void removeAllElements() {
modCount++;
// Let gc do its work
for (int i = 0; i < elementCount; i++)
elementData[i] = null;
elementCount = 0;
}- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
clone
/**
* 返回当前vector的克隆. 该克隆会指向一个全新的vector。
*
* @return 当前vector的克隆
*/
public synchronized Object clone() {
try {
@SuppressWarnings("unchecked")
Vector<E> v = (Vector<E>) super.clone();
v.elementData = Arrays.copyOf(elementData, elementCount);
v.modCount = 0;
return v;
} catch (CloneNotSupportedException e) {
// this shouldn't happen, since we are Cloneable
throw new InternalError(e);
}
}- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
toArray
/**
* 将vector中所有元素按顺序存放到数组中
*
* @since 1.2
*/
public synchronized Object[] toArray() {
return Arrays.copyOf(elementData, elementCount);
}- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
toArray
/**
* 返回Vector的模板数组。所谓模板数组,即可以将T设为任意的数据类型。
*
* @param a 将要存放vector中所有元素的数组
* @return 存放vector中所有元素的数组
* @throws ArrayStoreException 如果vector中元素不能转换为T
* @throws NullPointerException 如果指定的数组为null
* @since 1.2
*/
@SuppressWarnings("unchecked")
public synchronized <T> T[] toArray(T[] a) {
//如果数组a的大小 < vector的元素个数
if (a.length < elementCount)
// 则新建一个T[]数组,数组大小是“Vector的元素个数”,并将“Vector”全部拷贝到新数组中
return (T[]) Arrays.copyOf(elementData, elementCount, a.getClass());
//若数组a的大小 >= vector的元素个数,则将Vector的全部元素都拷贝到数组a中。
System.arraycopy(elementData, 0, a, 0, elementCount);
if (a.length > elementCount)
a[elementCount] = null;
return a;
}- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
elementData
// 获取索引为index的元素
@SuppressWarnings("unchecked")
E elementData(int index) {
return (E) elementData[index];
}- 1
- 2
- 3
- 4
- 5
get
/**
* 返回vector中索引位置为index的元素.
*
* @param index 要返回的元素的索引
* @return 索引为index的元素
* @throws ArrayIndexOutOfBoundsException 如果索引小于0或者索引大于等于vector的大小
*
* @since 1.2
*/
public synchronized E get(int index) {
if (index >= elementCount)
throw new ArrayIndexOutOfBoundsException(index);
return elementData(index);
}- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
set
/**
* 将索引为index的元素替换为指定元素element,并返回被替换的旧元素。
*
* @param index 被替换的元素的位置
* @param element 指定元素
* @return 被替换的旧元素
* @throws ArrayIndexOutOfBoundsException 如果索引小于0或者索引大于等于vector的大小
* @since 1.2
*/
public synchronized E set(int index, E element) {
if (index >= elementCount)
throw new ArrayIndexOutOfBoundsException(index);
E oldValue = elementData(index);
elementData[index] = element;
return oldValue;
}- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
add
/**
* 添加指定元素到vector的末尾.
*
* @param e 被添加到vector的元素
* @return true
* @since 1.2
*/
public synchronized boolean add(E e) {
modCount++;
ensureCapacityHelper(elementCount + 1);
elementData[elementCount++] = e;
return true;
}- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
remove
/**
* 正向遍历vector,当指定对象o第一次出现时,删除它,它之后的元素左移一位。
*
* @param o 被删除的元素
* @return 如果对象在vector中存在,返回true
* @since 1.2
*/
public boolean remove(Object o) {
return removeElement(o);
}- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
add
/**
* 在指定索引index处插入指定对象element。索引大于或等于index的元素右移,索引+1。
* 索引必须大于等于0而且小于等于vector的大小。
*
* @param index 指定索引
* @param element 指定对象element
* @throws ArrayIndexOutOfBoundsException 索引必须小于0或者大于vector的大小
* @since 1.2
*/
public void add(int index, E element) {
insertElementAt(element, index);
}- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
remove
/**
* 删除在特定索引index的元素。在索引index之后的元素左移,索引减1。
*
* 索引index大小必须大于等于0且小于vector的大小
*
* @param index 需要删除的元素的索引
* @throws ArrayIndexOutOfBoundsException 索引index小于0或大于vector的大小
* @since 1.2
*/
public synchronized E remove(int index) {
modCount++;
if (index >= elementCount)
throw new ArrayIndexOutOfBoundsException(index);
E oldValue = elementData(index);
int numMoved = elementCount - index - 1;
if (numMoved > 0)
System.arraycopy(elementData, index+1, elementData, index,numMoved);
elementData[--elementCount] = null; // Let gc do its work
return oldValue;
}- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
clear
/**
* 清空vector
*
* @since 1.2
*/
public void clear() {
removeAllElements();
}- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
containsAll
// 大数据量操作
/**
* 返回vector是否完全包含指定的集合c
*
* @param c 指定的集合c
* @return 返回vector是否完全包含指定的集合c
* @throws NullPointerException 指定的集合c为null
*/
public synchronized boolean containsAll(Collection<?> c) {
return super.containsAll(c);
}- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
addAll
/**
* 添加指定集合c中的所有元素到vector的末尾
*
* @param c 指定集合c
* @return 如果指定集合c的长度大于0
* @throws NullPointerException 如果指定集合c为null
* @since 1.2
*/
public synchronized boolean addAll(Collection<? extends E> c) {
modCount++;
Object[] a = c.toArray();
int numNew = a.length;
ensureCapacityHelper(elementCount + numNew);
System.arraycopy(a, 0, elementData, elementCount, numNew);
elementCount += numNew;
return numNew != 0;
}- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
removeAll
/**
* 删除vector中vector和指定集合c中共有的元素。
*
* @param c 指定集合c
* @return true 如果删除成功
* @throws ClassCastException 如果vector中有元素和指定集合中的元素类型不匹配
* @throws NullPointerException 如果vector中含有null,而指定集合不支持null
* @since 1.2
*/
public synchronized boolean removeAll(Collection<?> c) {
return super.removeAll(c);
}- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
retainAll
/**
* 从vector中移除未包含在指定集合c中的所有元素
* @param c 指定集合c
* @return
* @throws ClassCastException 如果vector和指定集合中有元素类型不匹配
* @throws NullPointerException 如果vector中含有null,而指定集合不支持null
* @since 1.2
*/
public synchronized boolean retainAll(Collection<?> c) {
return super.retainAll(c);
}- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
addAll
/**
* 在vector的指定索引index处插入指定集合c。在索引index处的元素和之后的元素右移一位。
*
* @param index 指定索引
* @param c 指定集合
* @return
* @throws ArrayIndexOutOfBoundsException 索引index小于0或大于vector的大小
* @throws NullPointerException 指定的集合为null
* @since 1.2
*/
public synchronized boolean addAll(int index, Collection<? extends E> c) {
modCount++;
if (index < 0 || index > elementCount)
throw new ArrayIndexOutOfBoundsException(index);
Object[] a = c.toArray();
int numNew = a.length;
ensureCapacityHelper(elementCount + numNew);
int numMoved = elementCount - index;
if (numMoved > 0)
System.arraycopy(elementData, index, elementData, index + numNew,
numMoved);
System.arraycopy(a, 0, elementData, index, numNew);
elementCount += numNew;
return numNew != 0;
}- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
equals
/**
*
* 比较指定的对象o和vector是否相等。
*
* 当特定的集合也是个list,而且和vector大小相等、元素相同,元素的顺序也相同,那么就可以说两者是相等的。
*
* @param o 和vector相比较的对象
* @return true 如果特定的对象和vector相等
*/
public synchronized boolean equals(Object o) {
return super.equals(o);
}- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
hashCode
/**
* 返回vector的hash code值.
*/
public synchronized int hashCode() {
return super.hashCode();
}- 1
- 2
- 3
- 4
- 5
- 6
toString
/**
* 返回vector的字符串表示,包含每个元素的字符串表示
* Returns a string representation of this Vector, containing
* the String representation of each element.
*/
public synchronized String toString() {
return super.toString();
}- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
**
/**
* 返回一个list从起点索引fromIndex(包括)到终点索引toIndex(不包括)的子集。如果fromIndex等于endIndex,返回的子集为空。该子集是由list返回的,改变该子集会影响到list,反之亦然。子集支持list所有的操作。
*
* @param fromIndex 起点索引
* @param toIndex 终点索引
* @return 返回list的子集
* @throws IndexOutOfBoundsException 如果fromIndex小于0或者endIndex大于0
* @throws IllegalArgumentException 如果fromIndex大于toIndex
*/
public synchronized List<E> subList(int fromIndex, int toIndex) {
return Collections.synchronizedList(super.subList(fromIndex, toIndex),this);
}- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
removeRange
/**
* 删除list中从索引fromInde(包含)到toIndex(不包含)之间的所有元素。Removes from this list all of the elements whose index is between。索引toIndex处的元素和其之后的元素左移。
*/
protected synchronized void removeRange(int fromIndex, int toIndex) {
modCount++;
int numMoved = elementCount - toIndex;
System.arraycopy(elementData, toIndex, elementData, fromIndex,numMoved);
// Let gc do its work
int newElementCount = elementCount - (toIndex-fromIndex);
while (elementCount != newElementCount)
elementData[--elementCount] = null;
}- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
writeObject
注意Vector只有writeObject,而不像ArrayList既有writeObject,又有readObject。
/**
* 将vector写入到ObjectOutputStream中。
*
* 该方法执行同步以确定序列化数据的连贯性。
*/
private void writeObject(java.io.ObjectOutputStream s)
throws java.io.IOException {
final java.io.ObjectOutputStream.PutField fields = s.putFields();
final Object[] data;
synchronized (this) {
fields.put("capacityIncrement", capacityIncrement);
fields.put("elementCount", elementCount);
data = elementData.clone();
}
fields.put("elementData", data);
s.writeFields();
}- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
用到的设计模式
迭代器模式
详情请参考:Vector与迭代器模式
总结
从源码中,我们不难论证以前对Vector的了解
- Vector底层是数组。
/**
* 保存vector中元素的数组。vector的容量是数组的长度,数组的长度最小值为vector的元素个数。
*
* 任何在vector最后一个元素之后的数组元素是null。
*
* @serial
*/
protected Object[] elementData;- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 有序。Vector底层是数组,数组是有序的。
- 可重复。数组是可重复的。
- 随机访问效率高,增删效率低。通过索引可以很快的查找到对应元素,而增删元素许多元素的位置都要改变。
- 线程安全。很多方法都是synchronized的。















 342
342

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









