







打开手机,刷个视频,算法总能猜中你想看啥;让AI写个祝福,它愣是甜得齁人。这背后是谁在搞怪?对,就是大模型!从ChatGPT爆火出圈到“群模乱舞”,从豆包DAU登顶第一到春节期间DeepSeek黑马杀出,这帮“AI学霸”近两年火得不行,聊天、画画、写代码,啥都会点。可大模型到底是个啥玩意儿?为啥突然就成了科技圈的经久不衰的顶流?别急,东山这就带你一探究竟,3分钟让你跟大模型“拜把子”!
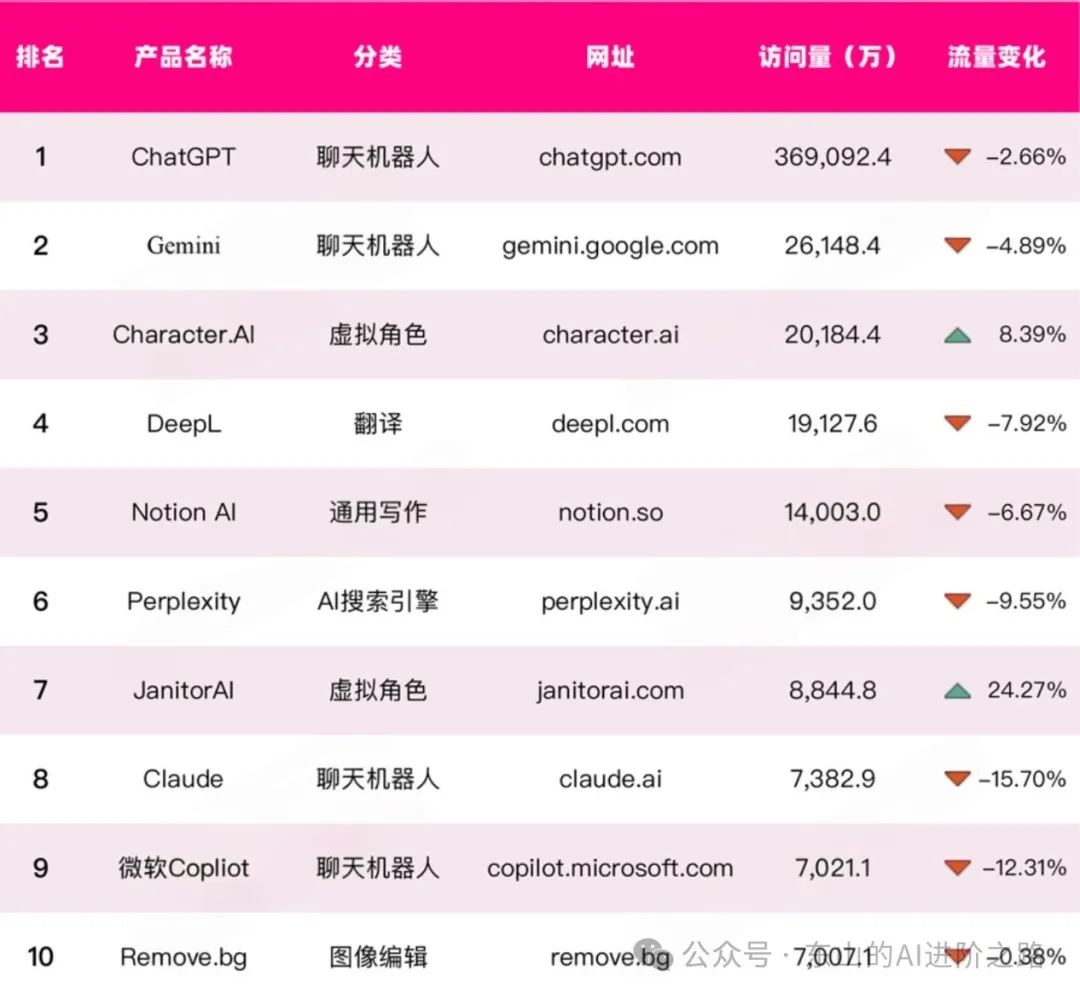
2024年12月全球大模型DAU排行榜前十:
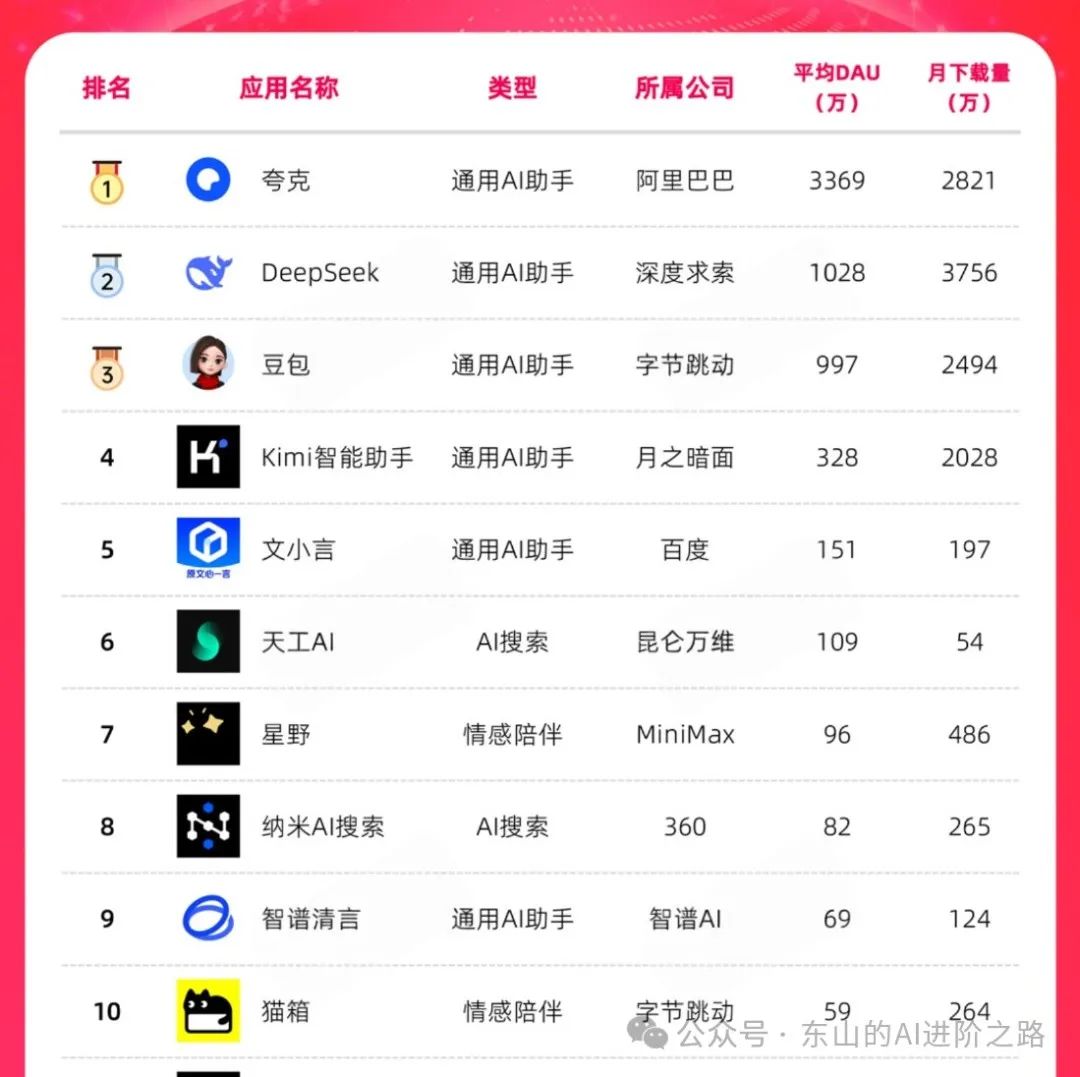
2025年一月国内大模型DAU排行榜前十:
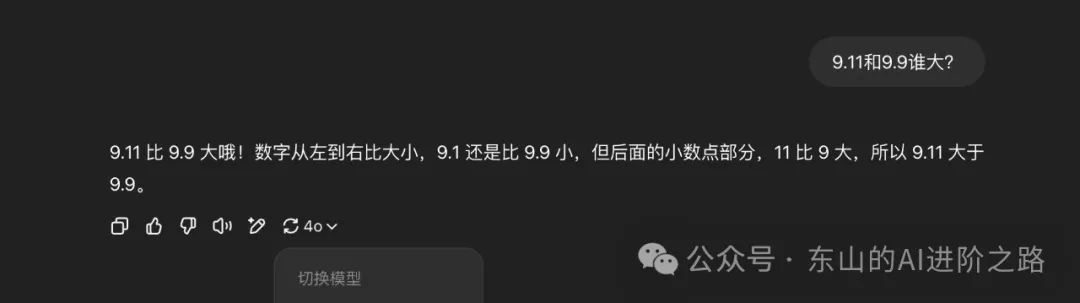
大模型是啥?别被名字唬住!简单来说就是AI的“超级学霸大脑”,它读过全网的书——从微博段子到学术论文,啥都往脑子里塞。问它问题,它就像个万能客服,秒回你答案,还能聊得像老朋友。咋做到的?参数多到吓人——几千亿个“脑细胞”在疯狂转,靠海量数据当“课本”,加上超级电脑当“私教”,没日没夜地训练,“答错了罚抄一百遍”,硬生生练成了“啥都会”的本事。像ChatGPT、豆包这些大模型,写诗、画画、帮你改代码,全不在话下。不过,别看它牛,犯起迷糊同样能够一本正经胡扯,比如问它“9.11和9.9谁大?”,它可能想都不想地回答“9.11”。想知道它咋翻车的?那就必须聊一聊它的核心原理。
2025年4月13日,ChatGPT4o版本回答“9.11和9.9谁大”的结果:
神经网络
神经网络是大模型的基础,它是一种模仿人脑神经元工作方式的计算模型,你可以把它想象成一个超级聪明的“问题解决机器”,它通过大量简单的小单元(称为神经元)协作,处理输入数据(比如文字、图片),然后输出结果(比如翻译、分类、生成内容)。通过学习数据中的模式,找到输入和输出之间的关系,比如你给它一张猫的图片,它能告诉你“这是猫”,因为它在大量图片中“学会了”猫的特征(毛、耳朵、胡须等)。
神经网络的基本结构涉及三个核心部分:神经元、连接与权重、层。
神经元是神经网络的“最小工人”,每个神经元主要做三件事:接收输入,从外界或前一层神经元获取数据(比如图片像素值、单词的编码)。加工处理,对输入进行加权求和(每个输入有个“重要程度”权重),再加上一个偏置(bias),然后通过一个激活函数进行处理,决定是否“激活”。输出结果,把处理后的结果传给下一层。将一个神经元理解为一个厨师,输入是各种食材(数据),权重是每种食材的用量,激活函数是烹饪手法(炒、蒸、烤),最后成功端出一盘菜(输出)。
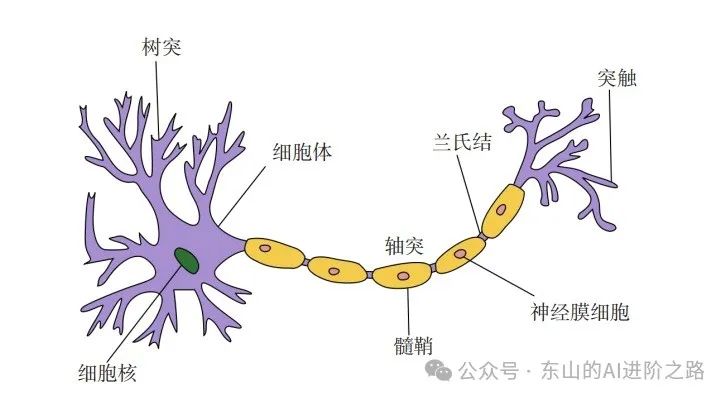
生物神经元结构(树突-轴突-轴突末梢):
神经元模型(输入-激活函数-输出):
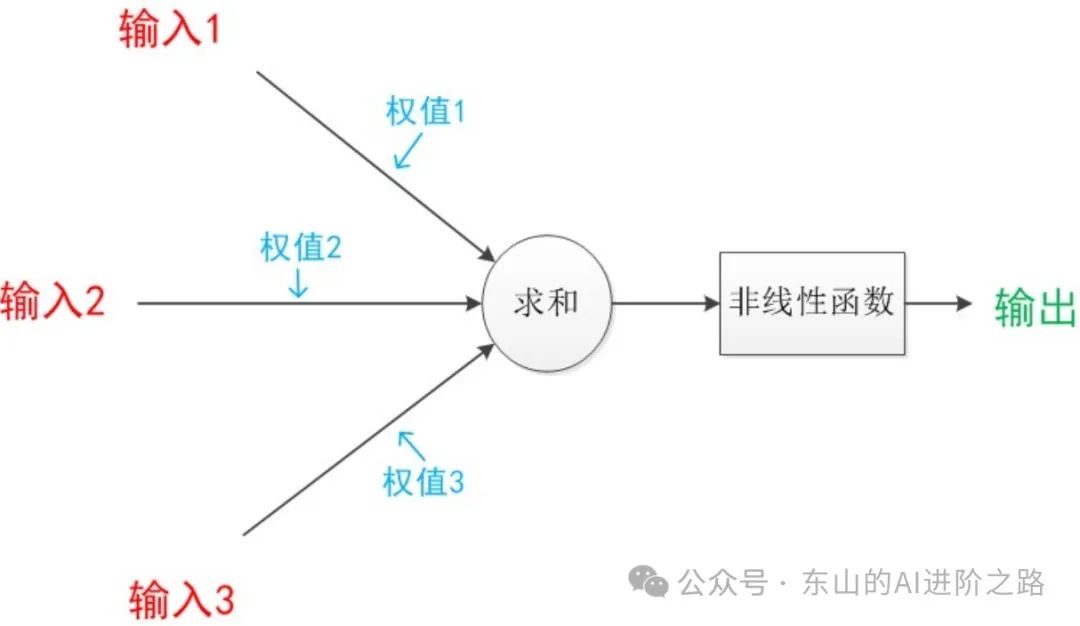
连接与权重,每层神经元之间通过“连接”传递信息,每个连接有一个权重,表示这个输入的重要性,神经网络的“学习”就是不断调整这些权重,让输出更接近正确答案。在这其中,输入可以类比为神经元的树突,而输出可以类比为神经元的轴突,计算则可以类比为细胞核,中间的箭头线则被称为“连接”,每个线有一个对应的“权值”。
如果我们将神经元图中的所有变量用符号表示,并且写出输出的计算公式的话,就是下图:
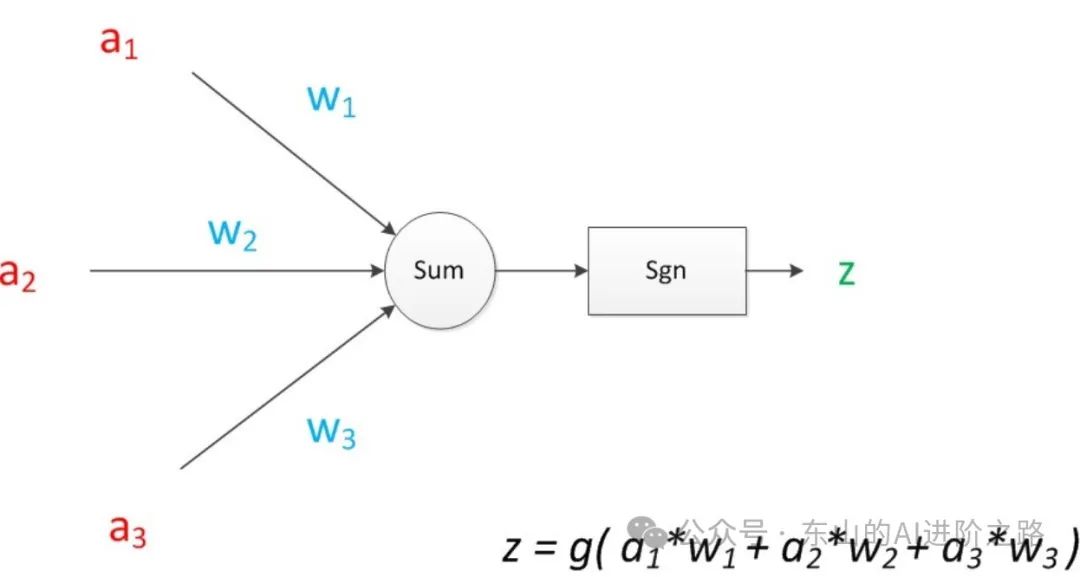
神经元可以看作一个计算与存储单元,计算是神经元对其的输入进行计算功能。存储是神经元会暂存计算结果,并传递到下一层:
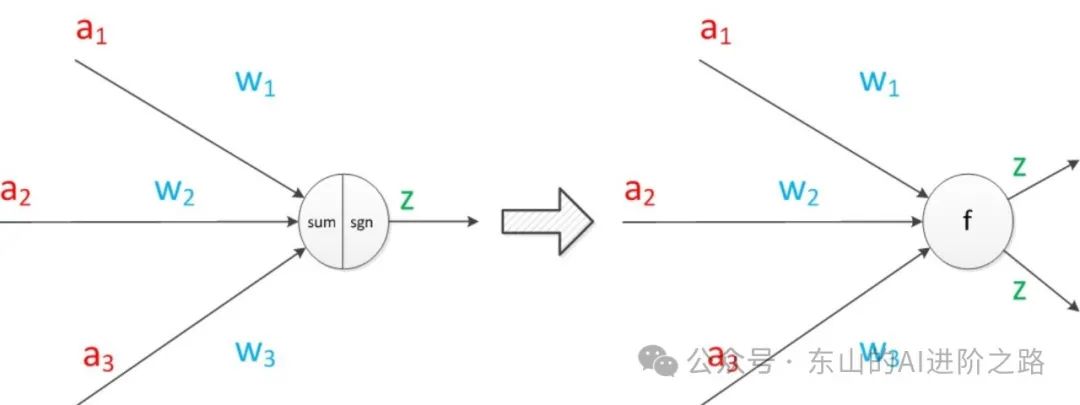
神经元模型的使用可以这样理解:我们有一个数据,称之为样本,样本有四个属性,其中三个属性已知,一个属性未知。我们需要做的就是通过三个已知属性预测未知属性。具体办法就是使用神经元的公式进行计算。三个已知属性的值是a1,a2,a3,未知属性的值是z,z可以通过公式计算出来。这里,已知的属性称之为特征,未知的属性称之为目标。假设特征与目标之间确实是线性关系,并且我们已经得到表示这个关系的权值w1,w2,w3,那么,我们就可以通过神经元模型预测新样本的目标。
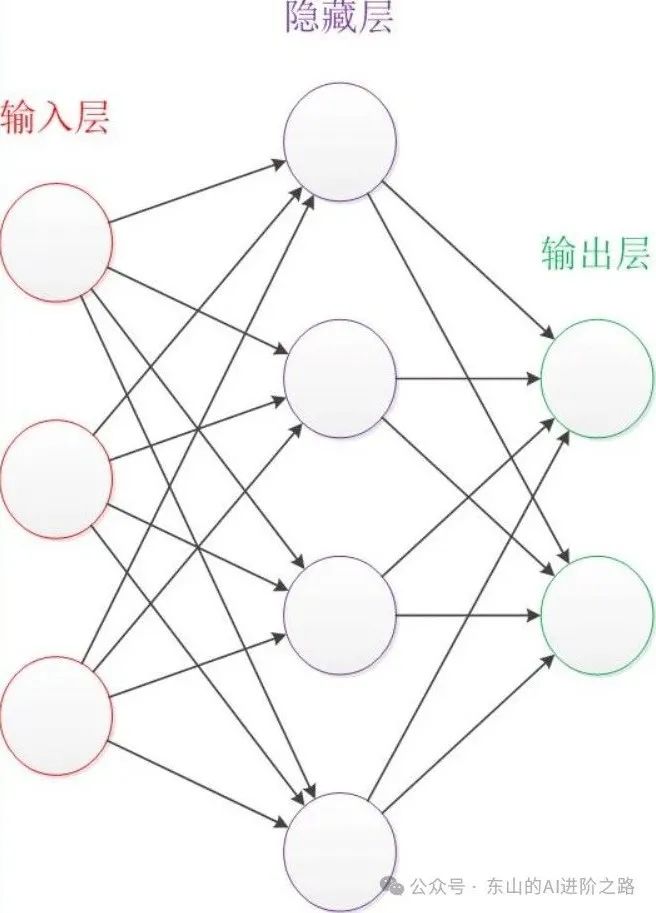
多层神经元共同构成了神经网络,常见的三种层包括输入层、隐藏层、输出层。输入层负责接收原始数据,比如一张图片的像素值或一句话的单词编码,隐藏层则是中间的“加工厂”,负责提取特征、转换数据,隐藏层越多,模型越“深”(同时这也是“深度学习”的由来)。输出层负责给出最终结果,比如“是猫还是狗”的概率。将整个神经网络视作一个流水线工厂,输入层是原料仓库,隐藏层是加工车间,输出层则是成品包装区。
神经网络层级图:
那么,神经网络是如何进行学习的呢?答案是通过一个叫训练的过程进行学习,训练的核心是“试错+改进”,有点像我们学骑自行车:摔倒几次后,慢慢找到平衡。
首先是前向传播,在前向传播中,数据从输入层经过隐藏层,逐层计算,直到输出层,得到一个预测结果。比如输入一张猫的图片,模型可能输出“80%是猫,20%是狗”。
在这个时候,模型会比较预测结果和真实答案的差距,这个差距叫损失,比如真实答案是“100%是猫”,但模型预测“80%是猫”,损失就是预测的偏差,损失函数的作用就是用来量化“模型有多离谱”。
最后则是反向传播,模型根据损失,逆向调整每条连接的权重,让下次预测更准确,就像考试没考好,老师帮你分析错题,告诉你哪部分知识点要加强。这需要用到数学中的梯度下降,沿着损失函数的“下坡”方向,逐步调整权重,找到损失最小的点。
重复“前向传播→计算损失→反向传播”很多次,不断进行迭代优化,直到模型的预测越来越准。
Transformer模型
大模型(如ChatGPT、Grok、LLaMA)主要基于一种特殊的神经网络结构——Transformer,它在大规模语言处理和多模态任务中表现出色。
标准的 Transformer 模型主要由两个模块构成:Encoder(编码器)和 Decoder(解码器)。其中,Encoder 负责理解输入文本,为每个输入构造对应的语义表示(语义特征),而Decoder负责生成输出,使用 Encoder 输出的语义表示结合其他输入来生成目标序列。
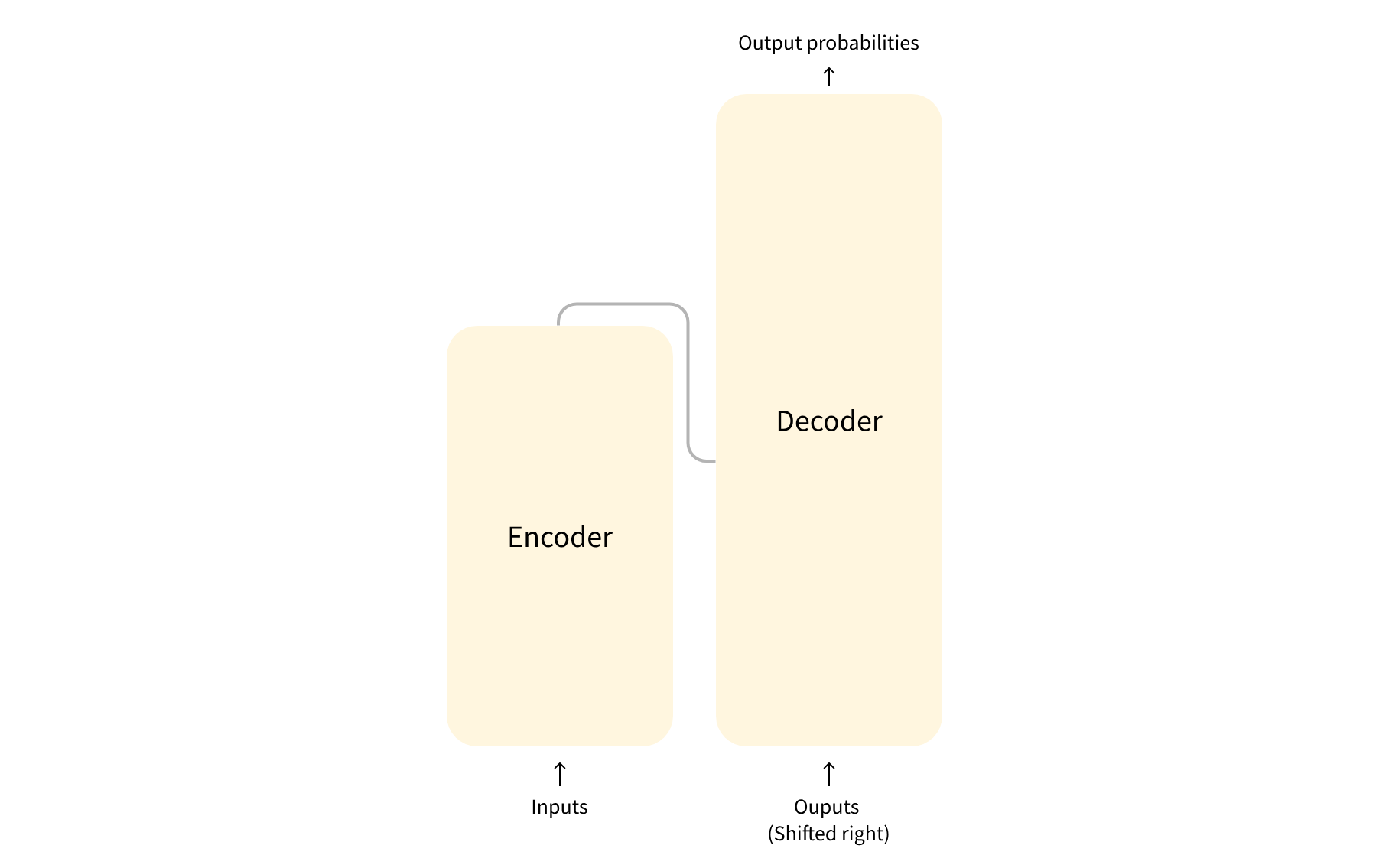
Transformer 模型的标志就是采用了注意力层的结构,或者说引进了注意力机制,这也是Transformer 模型的核心标志。顾名思义,注意力层的作用就是让模型在处理文本时,将注意力只放在某些词语上。 例如要将英文“You like this course”翻译为法语,由于法语中“like”的变位方式因主语而异,因此需要同时关注相邻的词语“You”。同样地,在翻译“this”时还需要注意“course”,因为“this”的法语翻译会根据相关名词的极性而变化。对于复杂的句子,要正确翻译某个词语,甚至需要关注离这个词很远的词。
不像之前的RNN(循环神经网络)需要按顺序处理数据,Transformer可以同时处理整个句子,训练更快。并且具备长距离依赖,能捕捉句子中远距离的关联,比如段落开头和结尾的联系。同时具有相当程度的扩展性,能够堆叠更多层、加更多参数,性能还能提升(这也是大模型动辄百亿参数的原因)。
Encoder 负责将输入的词语序列转换为词向量序列,Decoder 则基于 Encoder 的隐状态来迭代地生成词语序列作为输出,每次生成一个词语:
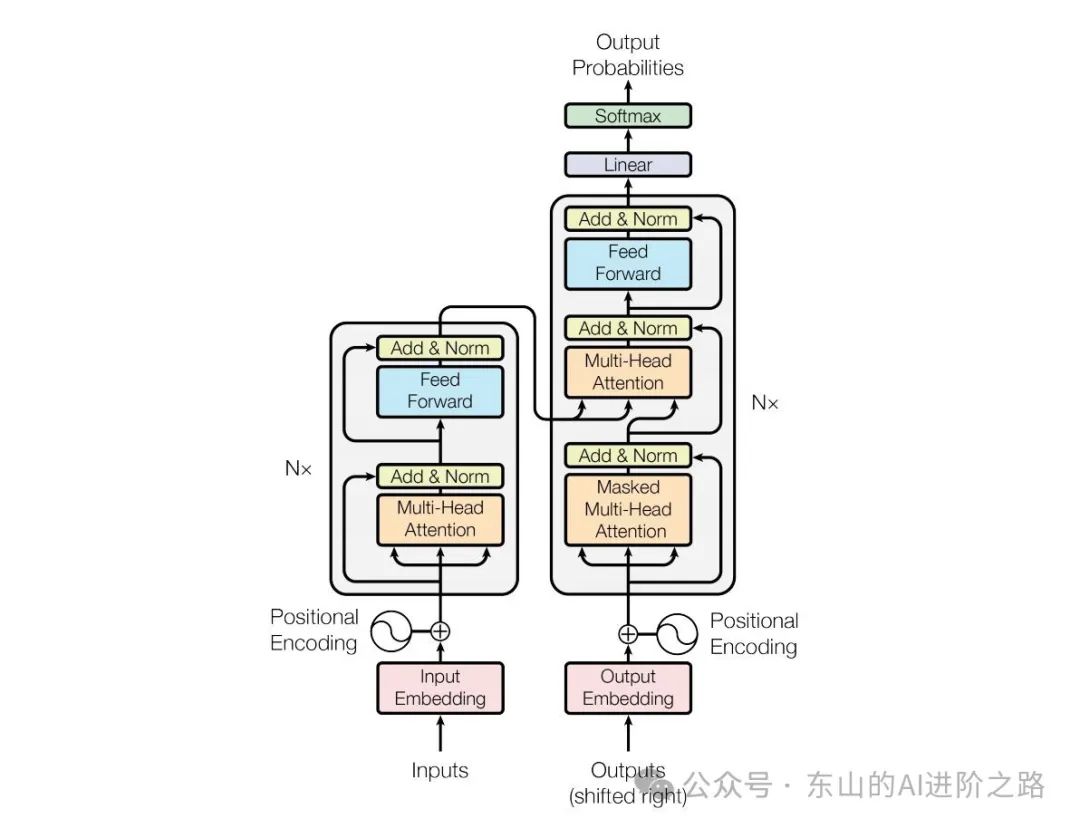
下图为一个翻译任务的例子:
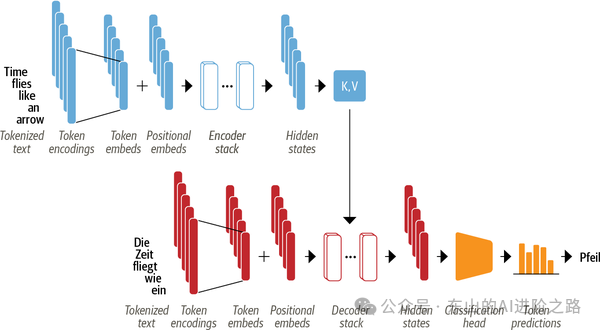
在英语“Time flies like an arrow”翻译为德语“Die Zeit fliegt wie ein Pfeil”的过程中,Encoder:Encoder将源语言句子(英文“Time flies like an arrow”)编码成语义表示,为翻译提供基础。
从图片左侧开始,Encoder作为Transformer的“输入处理工厂”,负责将源语言句子(比如英文“Time flies like an arrow”)编码成语义丰富的表示。在图中,句子先被分词为“Time”“flies”“like”“an”“arrow”,转为词向量并加上位置编码,以补充词序信息;然后通过多层Encoder Layer(包含多头自注意力捕捉词间关系、前馈神经网络增强语义、残差连接和层归一化稳定训练),生成一组语义向量(K、V),记录句子上下文,比如“Time”是主语,“flies”是动作,为翻译提供“语义蓝图”。
而Decoder则作为Transformer的“输出生成工厂”,根据Encoder的语义表示,逐步生成目标语言句子(比如德语“Die Zeit fliegt wie ein Pfeil”)。图中,已生成的词序列(比如“Die Zeit fliegt”)转为词向量并加位置编码,经过多层Decoder Layer(包括掩码自注意力只关注已生成词、交叉注意力查询Encoder的K、V对齐语义、前馈神经网络增强表示、残差连接和层归一化稳定训练),通过分类头预测下一个词(比如“wie”),重复此过程直到生成“Pfeil”和<EOS>,完成翻译。
二者协作,通过交叉注意力协作完成翻译任务:Encoder将源句“Time flies like an arrow”编码为语义向量(K、V),Decoder利用这些向量,逐步生成目标句“Die Zeit fliegt wie ein Pfeil”,每次生成一个词(比如“Pfeil”时关注“arrow”的语义),确保翻译准确对齐;Decoder自回归生成,依赖已生成词和Encoder的语义,直到完成整个句子,输出符合语义的翻译结果。
而Transformer 模型又衍生出不少分支,这里暂不进行更多的赘述,贴图如下:

训练三板斧
预训练:狂啃“知识自助餐”
大模型咋变“学霸”?先得预训练,用大量的通用数据集先训练模型,让它掌握基础知识和技能,这就好比中小学阶段疯狂刷题一样,它把全网的“知识自助餐”——抖音段子、知乎回答、学术论文,啥都往脑子里塞。像Llama 4,啃了40万亿个字,200种语言全打包!超级电脑当私教,没日没夜逼它考试,错一题罚抄一百遍,硬练出ChatGPT、豆包的“啥都懂”脑子。这活儿费钱到爆!电脑跑几万天,电费能买跑车,数据堆成山。可想想你小时候熬夜背书、挨骂的苦,这成本瞬间亲切了!练好了,它才敢上场,不然连“9.11>9.9”都分不清。
后训练:学点“人情世故”
预训练练出“学霸脑”,但还得后训练教它出错,指在预训练完成后的进一步训练阶段,目的在于让模型更好地适应实际的特定任务或应用场景。这像考上大学,奔着专业深造,该阶段数据规模小,通常是特定领域的数据。它用小份“专业课”数据,引进正负反馈,比如DeepSeek V3搞强化学习,电脑当班主任,喊:“答得好,给你糖!答错像‘9.11>9.9’,重写!”可AI太拼奖励,容易走极端。DeepSeek R1就用了GRPO这招,在传统强化学习的奖励机制之上,加入一个额外的约束(正则项),确保和最初的“比较好的模型”不会差距太大,好比加上了一个“冷静剂”,让AI进步的稳当点。训练时间短,成本低,豆包DAU牛气冲天,靠的也是这波“规矩课”。可AI心态也有崩的时候,练太狠,脑子偶尔打盹。想知道咋更靠谱?接着看!
微调:定制“实战绝活”
后训练出了“深造AI”,出徒后的大模型虽然基础知识丰富、专业能力一流,可是实战技巧却是空白,到了行业场景没法直接上岗,所以还得进行微调!就像职场工作一样,数据少但超精准。豆包微调后,点外卖比你闺蜜还懂你!不像模型商的“高大上”后训练,微调是用户的活儿,像烧烤摊大叔教你秘方。ChatGPT微调能写诗,甜得齁人像情书,不调?照样“9.11>9.9”翻车!微调让AI接地气,行业场景随便秀。
未来发展
学霸咋进化?深扒大模型未来!
大模型这学霸未来咋进化?多模态先炸场!ChatGPT不光能聊,还能画赛博财神猫(Sora出品),豆包写rap顺便P个红包表情包,抖音神片分分钟剪,DAU蹭蹭涨!混合模型超火,DeepSeek的MoE像学霸脑子拆成N个小分队,效率飞到天,电费省到钱包唱歌!定制化更牛,Dify、扣子变AI裁缝,医院出“医疗豆包”,学校有“作业侠”,专治“9.11>9.9”式翻车。以后AI得省力环保,小模型干大活,电脑不冒烟,房租都能省!可再牛也得讲伦理,泄隐私、造谣可不行,网友diss到火星!想知道怎么玩转AI,欢迎关注公众号东山的AI进阶之路,继续带你抄近道!


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









