






今年9月,OpenAI 在“o1”的技术报告中提出了train-time compute和test-time compute,大语言模型(LLM)的多步推理能力逐渐成为热门议题之一。
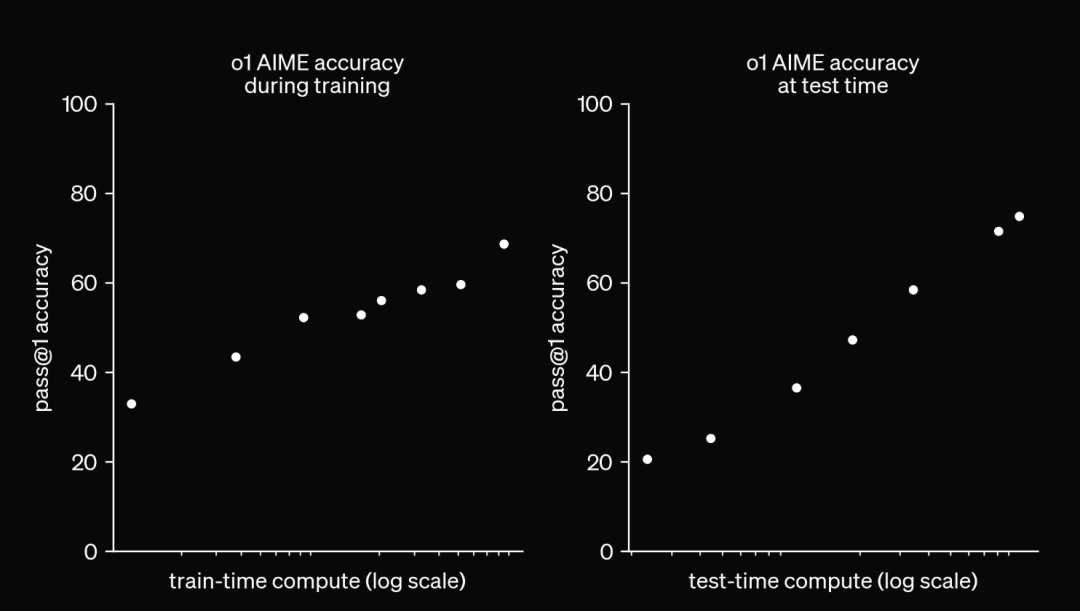
复杂的多步推理任务是大语言模型应用的一个重要挑战。多步推理即从初始条件出发,通过多步逻辑推导逐步得出结论的过程,对于解决现实中复杂的任务至关重要,数学题解、法律推理、科学论证等应用场景都需要模型具备这一能力。
在行业应用层面,医疗、法律等领域的专家期望 AI 系统能完成从信息提取到推理分析等多个层次的任务。这些任务同样要求模型具备多步推理的能力,以便给出准确、科学的判断或诊断。
除“o1”外,大部分模型在处理复杂多步推理任务中表现欠佳
LLMs 在处理日常对话和基础推理问题时,普遍依赖“链式思维”(Chain of Thought, CoT)等提示技巧,以提升模型的推理能力。OpenAI 新发布的“o1”模型在推理阶段使用了长 CoT,其 CoT 过程中表现出了反思逻辑正确性,拆解复杂任务,以及尝试采用不同思路进行推理等复杂的“行为”,这些“行为”在过往模型中比较少见。但遗憾的是,除“o1”之外,大部分模型在处理复杂的多步推理任务上表现不佳。
行业正在尝试从各种角度提升模型的推理能力。例如,为大模型提供更丰富的逻辑训练数据,以便让其更好地理解和执行逻辑推理任务;或通过不同的方式优化模型的训练过程,来帮助其提升推理能力;亦或者结合 MCTS 等搜索方法在推理阶段进行提升等。
RLHF 在多步推理任务上的研究相对较少
基于人类反馈的强化学习(Reinforcement Learning from Human Feedback, RLHF)也被广泛应用于 LLMs 的训练,并在交互任务上取得了较好的成果。RLHF 通过人类反馈优化模型的响应质量,使得模型不仅能生成符合语言学逻辑的回答,还能较好地理解并生成符合用户需求的内容。
然而,相比于SFT(Supervised Fine-Tuning)阶段的优化,RLHF 在多步推理任务上的研究相对较少,其原因在于基于强化方法的逻辑推理数据生成和训练过程具有较高的复杂性,特别是对于需要逐步推理、层层递进的任务,如何获取高质量的训练数据,如何确保训练数据提供连续合理的奖励信号,都是有待解决的难题。
过程、结果两种奖励模型均有不足之处
强化学习算法需要获得奖励信号来帮助模型提升效果,对于复杂推理任务,奖励的设计是相对困难的。常见的奖励模型有两种:结果奖励模型(Outcome-supervised Reward Model, ORM)和过程奖励模型(Process-supervised Reward Model, PRM)。前者大多通过判断模型最终回答是否正确进行打分,而后者倾向于给过程中的每一步打分。ORM 的数据较容易获得,但是其奖励较为稀疏,会让强化算法学习变得比较难;PRM 能给出较为稠密的奖励信号,但是其数据较难获取。
百川智能解决方案——MuseD
为了解决上述难题,提升大模型的多步推理能力。百川智能技术团队提出了一种新的数据生成和训练方法——MuseD(Multi-step Deduction)。
MuseD ,即多步推理生成方法,利用 RLHF 中的反馈信号,通过自动化生成不同难度的多步推理数据,为模型提供层层递进的推理任务。MuseD 能够围绕整个回答过程进行打分,包括回答的正确步骤数、错误步骤数,以及最终正确性等,进而可以获得轨迹奖励模型(Trajectory-supervised Reward Model, TRM)。
TRM 可以提供比 ORM 更容易学习的奖励信号,同时,它可以直接在轨迹维度学习,在数据生成和训练方面均比 PRM 更容易实现。MuseD 的设计目标是在模型训练和评估中,以系统化的数据生成流程,让模型在“预设条件-逻辑推导-得出结论”这一完整的链条中进行推理练习,使其逻辑能力得到显著提升。
MuseD:多步推理数据生成
MuseD 通过自动生成适用于多步推理的数据,使得模型可以在训练时学习处理不同难度的逻辑任务。
MuseD 的数据生成过程包括以下几个关键步骤:提示生成、回答生成、回答评分,以及偏好对比数据生成。前3个步骤的流程如下图所示:
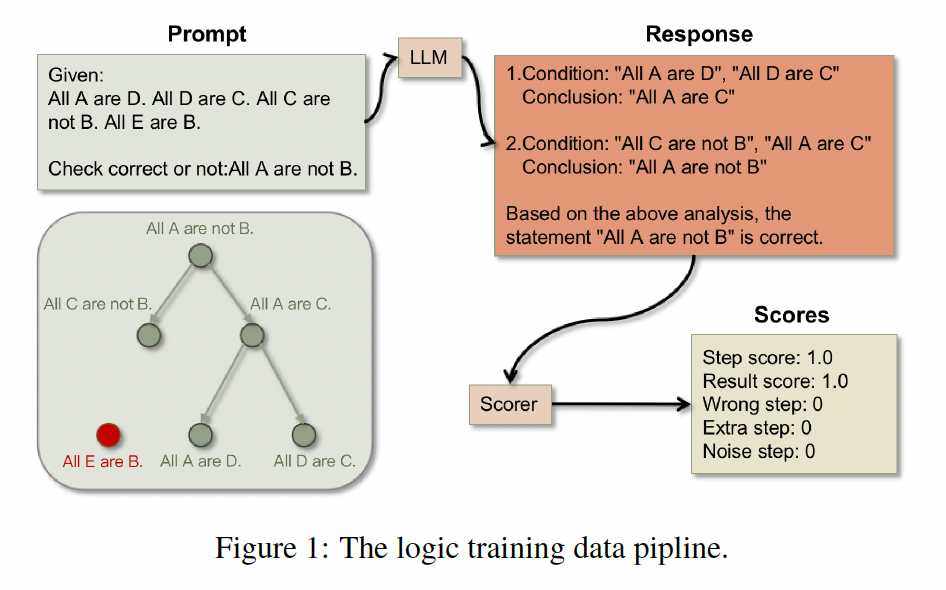
以下,是四个步骤的具体介绍。
1、提示生成(Prompt Generation)
在提示生成过程中,通过一种逆向生成(Backward Generation)的方法,从最终的目标结论出发,逐步生成前提条件。具体过程如下:
-
逻辑树构建:逻辑推理树的根节点为最终结论,叶节点为条件,通过这种结构,控制辑推理的复杂度。在树生成的过程中,随机从结论中抽取一个命题作为根节点,然后逐步向下生成叶节点,即推理条件。生成的条件节点与结论之间通过有效的逻辑关系相互连接。
-
条件填充:构建完成逻辑树后,紧接着为条件和结论中的各个实体进行填充。技术团队使用虚拟名词(例如,希腊字母名称或虚构的词汇)来替代具体的实体,确保模型进行纯粹的逻辑推理,而不是依赖常识得出结论,使推理过程更具一般性。
-
构建完整提示:在构建出逻辑树和填充条件后,需要将条件和结论组合为完整的提示。提示分为两种问题形式:证明型、判断型。对于证明型问题,要求模型直接证明结论的正确性;对于判断型问题,则将结论取反,要求模型判断该结论是否正确。这种提示生成方法确保了模型在面对复杂推理任务时能够进行逐步推理,而不仅仅是简单地直接给出答案。
2、回答生成(Response Generation)
为了评估生成的提示是否有效,技术团队设计了两种不同的回答生成方式:
-
自然回答生成(Na):模型根据生成的提示,以自然语言进行回答。这种方式较为贴近用户的自然语言交互方式,但在评分时较难处理。
-
格式化回答生成(Fo):模型按照指定的 JSON 格式返回回答,使得生成的回答更加结构化,便于后续的自动评分。这种格式的回答在训练和评估时更加便捷,但可能会影响模型的自然语言生成能力。
通过两种回答生成方式,可以灵活地获取模型在不同提示下的推理回答,既保证自然交互的真实性,又便于精确地自动化评分。
3、回答评分(Response Evaluation)
为了准确评估模型的多步推理表现,技术团队构建了多维度的评分体系,具体评分项包括:
-
步骤得分(Step Score):计算模型回答中正确的推理步骤数量(通过计算推理过程中的中间项消除情况来得出正确步骤数);
-
结果得分(Result Score):评价模型是否得出正确结论(若回答正确,计1分,否则计0分);
-
意图得分(Intent Score):检查生成的格式化回答是否为有效的 JSON 字符串;
-
错误步骤数(Wrong Step Count):记录推理过程中错误的步骤数(得分越低越好);
-
噪声步骤数(Noise Step Count):记录推理过程中与最终结论无关的步骤数(得分越低越好);
-
额外步骤数(Extra Step Count):记录重复的步骤数(得分越低越好)。
通过上述评分指标,能够全面了解模型在多步推理中的表现,既包括最终结果的正确性,也涵盖推理过程的合理性。从而帮助技术团队在最终进行奖励模型训练时,能够对整条轨迹进行全面的打分,进而得到轨迹奖励模型。
4、偏好对比数据生成(Preference-pair Composition)
在 RLHF 的训练过程中,模型通过偏好对比学习生成的奖励信号。这项研究在多步推理数据中,构建了多种偏好对比数据生成方法,包括:
-
仅使用正向信号的偏好对比(P):在每对比对中,选择具有更高步骤得分和结果得分的回答,这种方法训练可以得到正向奖励引导的 TRM;
-
混合正负信号的偏好对比(PN):同时考虑正负信号,使选择的回答在步骤和结果得分上均优于对比回答,这种方法可以得到包括正负信号的 TRM;
-
仅使用结果信号的偏好对比(R):仅使用结果得分作为对比标准,选择结果正确的回答,这种方法可以获得只使用最终结果进行训练的 ORM。
通过不同的偏好对比方法,可以观察到正向步骤信号对于提升推理准确性的重要性。
实验结果
在实验阶段,百川智能技术团队通过 MuseD 生成的数据对多种 LLM 进行了训练与评估。
为了全面测试模型的推理能力,技术团队构建了 MuseD 测试集,包含 2000 条多步推理任务的提示,任务步骤数从 1 到 10 不等。除了自建 MuseD 测试集,技术团队还使用了多种外部公开数据集(PrOntoQA、ProofWriter、LogicalDeduction、FOLIO等),以测试模型在不同数据分布和任务格式下的表现。
通过 MuseD 生成的多步推理数据以及偏好对比数据,技术团队对模型进行基于人类反馈的强化学习训练。在实验中,使用了多个不同的偏好数据对模型进行训练,例如仅使用正向信号的偏好数据(P)、混合正负信号的偏好数据(PN)和仅使用结果信号的偏好数据(R),以研究不同偏好数据对模型性能的影响。
通过强化学习的策略优化算法(Proximal Policy Optimization, PPO),技术团队在 MuseD 和多个外部数据集上评估模型性能,考察步骤得分、结果得分、噪声步骤数和额外步骤数等多维度指标的变化。结果显示,强化训练后的模型在自建数据集和相关公开的逻辑评测集上都得到了大幅提升。
另外,技术团队还进行了多种消融,比较了不同数据构造的方式下对模型能力提升的影响,包括 TRM 和 ORM 的差异,自然格式回答(Na)和格式化回答(Fo)两种数据格式对模型训练的影响,是否增加通用数据集(这里选用 UltraFeedback 数据集,缩写为 UF)的影响,以及 PPO 训练过程 prompt 选择的影响等。
以下,是分别在MuseD数据集和开源评测集上的实验效果。
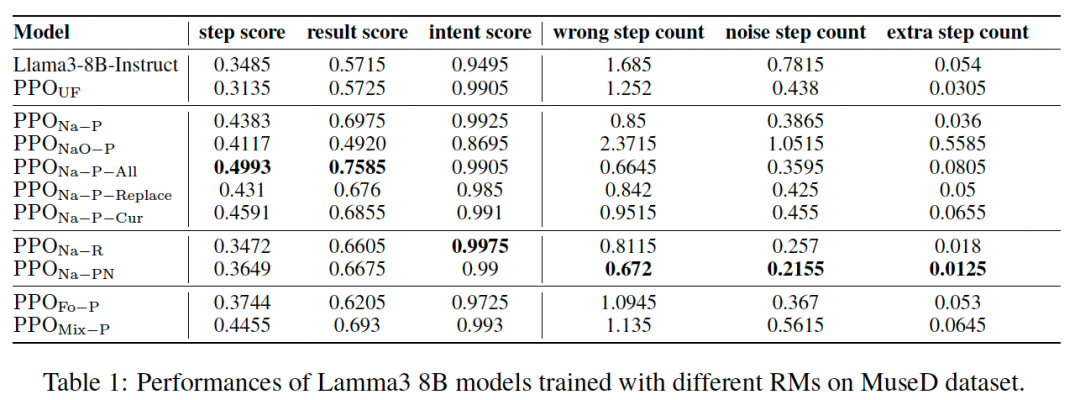
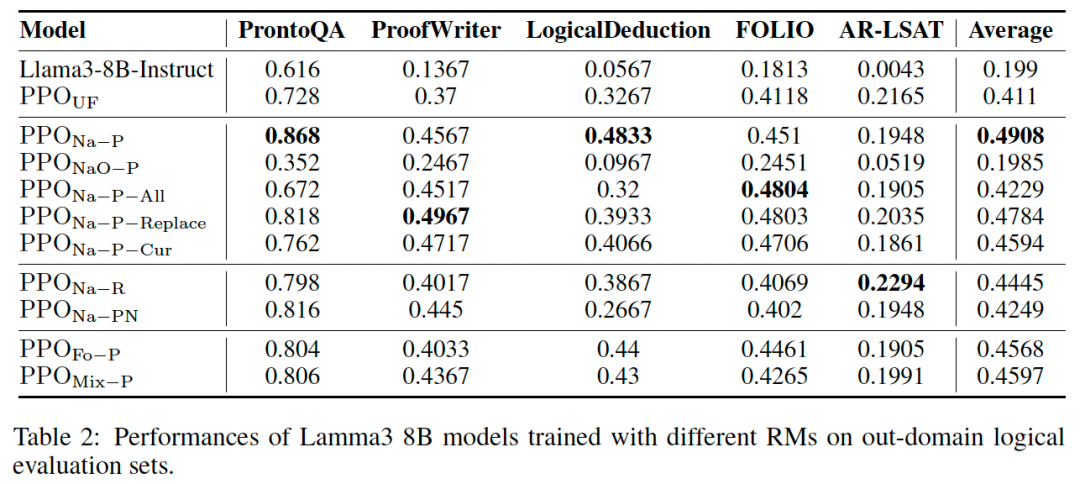
基于上述实验,可得以下结论:
-
MuseD 数据集上的性能提升:在多步推理数据集 MuseD 上,采用自然格式回答(Na),P 偏好数据结合UF数据集训练的 PPO 模型(PPO Na-P)在步骤得分和结果得分上显著优于基础模型和其他偏好数据训练的模型。相比仅使用 UF 数据的 PPO 模型,PPO Na-P 的正确步骤数提升了12个百分点,并且错误步骤数显著减少,显示出 MuseD 数据生成方法在提高多步推理任务表现方面的有效性。
-
跨领域任务的泛化性能:MuseD 数据集训练的模型在外部数据集上同样表现优异,平均效果提升了8个百分点,PrOntoQA 和 LogicalDeduction 上提升了14-16个百分点。这表明 MuseD 数据不仅提升了模型的特定任务能力,还增强了其跨任务的泛化推理能力。
-
偏好对比数据的影响:实验表明,包含正向步骤信号(P)的 TRM 效果优于仅使用结果信号(R)的 ORM,而加入负向信号(PN)则会使模型性能下降。结果说明,多步推理中每一步的正向反馈信号对于模型的推理过程提升至关重要。
-
数据格式的影响:实验发现,自然格式回答的数据(Na)相比结构化格式回答的数据(Fo)更有利于模型的逻辑推理能力提升。自然格式的回答更贴近用户交互的实际情况,有助于模型在多步推理任务中更自然地进行推理步骤的连接。
-
增加通用数据集(UF)的影响:对比 PPO NaO-P 和 PPO Na-P,前者仅使用了逻辑数据而后者结合了UF数据,可以明显看到通用数据的缺失使模型能力大幅下降。
-
PPO 训练过程 prompt 选择的影响:我们还对比了 PPO 训练过程中,使用同分布的其他逻辑 prompt 进行训练,或者是进行从易到难的课程学习的方式训练,结果表明还是使用 RM 中的 prompt 混合训练整体效果更好。
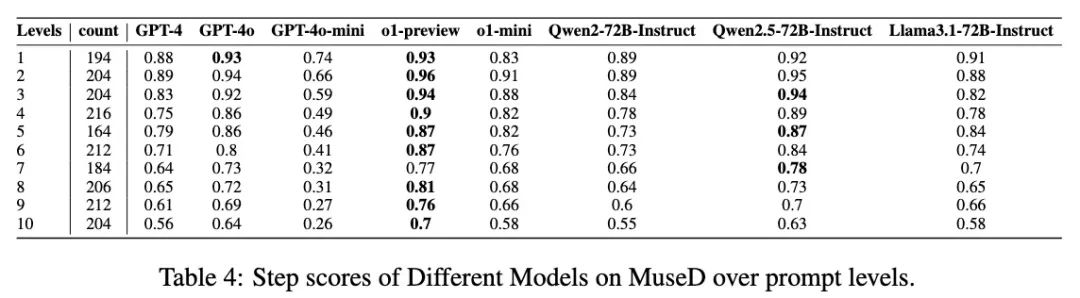
其他LLMs在MuseD数据集上的表现:
将 MuseD 生成的数据用于测试多种大型语言模型的推理能力,包括 GPT-4、Qwen2.5-72B 等。
实验结果表明,o1-preview 在多步推理任务上的表现最佳,而 Qwen2.5-72B 也表现出较高的步骤和结果得分。这进一步验证了 MuseD 生成的数据在不同 LLMs 上的广泛适用性和有效性。
在多步推理难度较高的任务上(例如推理步骤数10),o1-preview 能够保持 0.7 的步骤得分,显现出 MuseD 数据在提高多步推理任务难度适应性方面的显著效果。

整体结论
百川智能创新设计的 MuseD 方法,通过一种逆向生成推理条件的方式,有效地控制了推理任务的复杂度,为多步逻辑推理任务提供了高效的训练数据生成和评价框架。通过 RLHF 训练,MuseD 显著提升了模型在逻辑推理任务中的表现,尤其在 MuseD 数据集上获得了显著的提升。此外,MuseD 生成的评估数据集也为测试不同 LLMs 在多步推理任务中的表现提供了可靠的标准。
论文作者:李佳莲,张艺品,沈蔚,谢剑,阎栋
【参考文献】
[1] Long Ouyang, Jeffrey Wu, Xu Jiang, Diogo Almeida, Carroll Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, et al. Training language models to follow instructions with human feedback. Advances in neural information processing systems, 35:27730–27744, 2022.
[2] Yuntao Bai, Andy Jones, Kamal Ndousse, Amanda Askell, Anna Chen, Nova Dassarma, Dawn Drain, Stanislav Fort, Deep Ganguli, and Tom Henighan. Training a helpful and harmless assistant with reinforcement learning from human feedback. 2022.
[3] Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Fei Xia, Ed Chi, Quoc V Le, Denny Zhou, et al. Chain-of-thought prompting elicits reasoning in large.
[4] https://openai.com/index/learning-to-reason-with-llms/.
[5] Oyvind Tafjord, Bhavana Dalvi, and Peter Clark. Proofwriter: Generating implications, proofs, and abductive statements over natural language. In Findings of the Association for Computational Linguistics: ACL-IJCNLP 2021, pp. 3621–3634, 2021.
[6] Jian Liu, Leyang Cui, Hanmeng Liu, Dandan Huang, Yile Wang, and Yue Zhang. Logiqa: a challenge dataset for machine reading comprehension with logical reasoning. In Proceedings of the Twenty-Ninth International Conference on International Joint Conferences on Artificial Intelligence,pp. 3622–3628, 2021.
[7] Simeng Han, Hailey Schoelkopf, Yilun Zhao, Zhenting Qi, Martin Riddell, Wenfei Zhou, James Coady, David Peng, Yujie Qiao, Luke Benson, Lucy Sun, Alex Wardle-Solano, Hannah Szabo, Ekaterina Zubova, Matthew Burtell, Jonathan Fan, Yixin Liu, Brian Wong, Malcolm Sailor, Ansong Ni, Linyong Nan, Jungo Kasai, Tao Yu, Rui Zhang, Alexander R. Fabbri,Wojciech Kryscinski, Semih Yavuz, Ye Liu, Xi Victoria Lin, Shafiq Joty, Yingbo Zhou, Caiming Xiong, Rex Ying, Arman Cohan, and Dragomir Radev. Folio: Natural language reasoning with first-order logic, 2024. URL https://arxiv.org/abs/2209.00840.
[8] Alexander Havrilla, Yuqing Du, Sharath Chandra Raparthy, Christoforos Nalmpantis, Jane Dwivedi-Yu, Eric Hambro, Sainbayar Sukhbaatar, and Roberta Raileanu. Teaching large language models to reason with reinforcement learning. In AI for Math Workshop@ ICML 2024.
[9] Richard Yuanzhe Pang, Weizhe Yuan, Kyunghyun Cho, He He, Sainbayar Sukhbaatar, and Jason Weston. Iterative reasoning preference optimization. arXiv preprint arXiv:2404.19733, 2024.
[10] Yuxi Xie, Anirudh Goyal, Wenyue Zheng, Min-Yen Kan, Timothy P Lillicrap, Kenji Kawaguchi, and Michael Shieh. Monte carlo tree search boosts reasoning via iterative preference learning. arXiv preprint arXiv:2405.00451, 2024.
[11] Hunter Lightman, Vineet Kosaraju, Yuri Burda, Harrison Edwards, Bowen Baker, Teddy Lee, Jan Leike, John Schulman, Ilya Sutskever, and Karl Cobbe. Let’s verify step by step. In The Twelfth International Conference on Learning Representations.
欢迎关注【百川智能商业服务】官方公众号,获取更多行业资讯



















 1187
1187

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









