







我们会在postgresql数据库的数据目录下pg_xlog(新版本已经变为pg_wal)目录下看到下面这些文件:
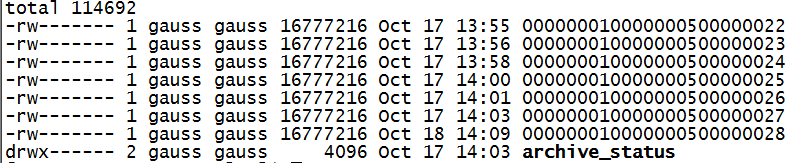
如果第一次看到这些文件名可能觉得命名很奇怪,这么一串数字有什么含义呢,为什么要这样命名,这就要从lsn说起。
我们知道postgresql通过lsn标识redo(xlog)位置,通过lsn可以定位到xlog文件以及文件的偏移量,下面先看看lsn,通过pg_current_xlog_location()函数可以查到当前的lsn位置(高版本是pg_current_wal_lsn),如下所示
postgres=# select pg_current_xlog_location();
pg_current_xlog_location
--------------------------
5/285C6080
(1 row)首先说下lsn的位数,因为lsn标识着xlog的位置,这个位置在数据库启动后就是在不断增加的,所以32位的lsn肯定是不够用的。因为32bit最大的日志只能支撑4GB的日志,这肯定是不够用的,所以要考虑设计64位lsn,这就是现在的lsn格式,lsn由斜杠左边和右边各8位16进制数组成(斜杠左边0省略了),也就是左边32位,右边32位,加起来64位,能够支持4GB*4GB的日志,这样的lsn显然是用不完的。
再来说说xlog文件名,总共24位数,都是16进制,可以分为三部分,例如:00000001 00000005 00000028来说,第一部分代表时间线,时间线是备份恢复里的概念,每当执行一次pg_rewind会造成时间线偏离分叉,时间线加1;第二部分代表logid,第三部分代表logseg,这两部分其实就和lsn关联起来了。(这里lsn是 5/285C6080 换算后的64位)
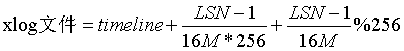
我们可能发现,logseg的八位数只有后面两位有值,这是为什么呢?从上面这个公式上我们可以看出端倪,我们知道每个xlog是16M,lsn的低32位最大支持4GB的日志,4GB/16M=256,这也是logseg的最大值,变为16进制的话就是0x00-0xFF也就是xlog文件名的最后两位16进制数正好满足。所以xlog从00-FF共256个16M文件写满后,第二部分的logid字段加一,然后第三部分继续从00-FF写256个16M文件:00000001 00000000->00000001 000000FF->00000002 00000000->00000002 000000FF这样的模式写下去。
那么我们再来看看上面这个公式的巧妙之处,xlog的第二段logid是LSN减一除以16M*256,首先lsn-1是因为lsn不是从0开始的,他会跳过0从1开始。然后除以16M是除以logid,每个文件16M,再除256就是除以最后两位的256,所以除下来的商其实就是xlog的第几个文件,而第三部分除以256的余数就是具体这个xlog文件中的偏移量。
那么再来看看lsn的低32位,lsn的低32位除以16M的大小,16M等于2的24次方,285C6080除以2的24次方相当于向左移动6位,商就是logid,余数就是xlog的偏移量,也就是28是logseg,也就是第一个图中最后一个文件,当然老版本是xlog用时分配,新版本好像规则改成了xlog提前申请,会提前生成还未使用的xlog文件;而5C6080转换为10进制就是xlog中的位置,这个设计多么巧妙啊,直接将xlog文件名用成了哈希表,直接定位lsn在哪个xlog以及在xlog中的偏移位。
其实postgresql也为我们提供了函数能够直接计算lsn在xlog中的位置:
postgres=# select pg_xlogfile_name_offset('5/285C6080');
pg_xlogfile_name_offset
------------------------------------
(000000010000000500000028,6054016)
(1 row)上面的计算结果也证实了这一点,logid=5,logseg=28,偏移量6054016(5C6080转换为10进制的值)。
原文链接:https://blog.csdn.net/xiaohai928ww/article/details/102948920















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









