






目录
-
数据结构概述
众所周知,python中的数据类型共有8类,列表、字典、集合、数值类型(分为int类型和float类型)、布尔类型、字符串、元组。按照地址不变时可否改变原始数据,又将前三种划分可变类型,后五种划分为不可变类型。
而今天所谈的数据结构,指的是数据的存储组成方式,即数据元素之间存在着一种或多种特定关系。挑选合适的数据结构能给实际开发工作带来更高的运行和存储效率。
如上所述,我们根据元素间关系的特点,进一步将数据结构分成两类:
①线程结构

②非线性结构
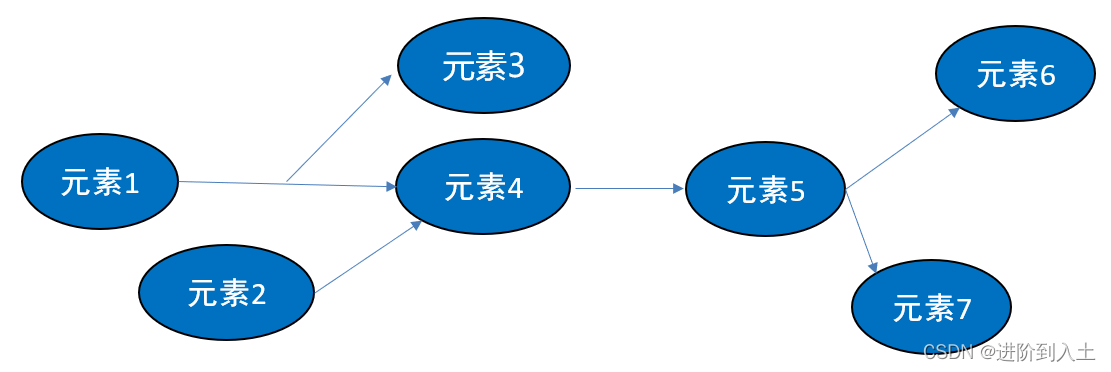
上图中,可以看出:线性结构的元素间是一对一的线性关系,每个元素至多存在一个前驱和一个后继;而非线性结构中的元素间是多对多的关系,每个元素存在多个前驱或多个后继。在python中,线性结构的有:队列、栈,非线性结构的有:树、图
-
链表的分类及python中的实现方式
链表属于线性结构的一种,其特点在于存储的不连续性。相较于使用连续存储方式的顺序表,在内存空间相对不足的情况下,更为适用。链表中每个元素(以下称节点),由两部分构成:元素域、地址域,元素域用来存放数据,地址域用来存放下一个节点的地址(即指向下一个节点)。
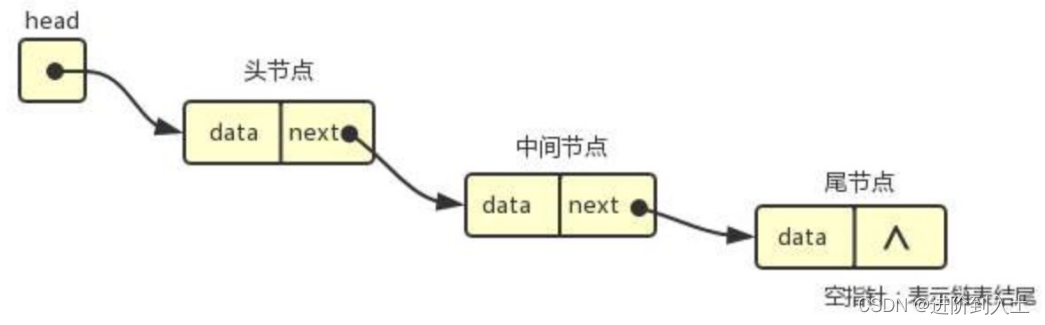
按照地址域的数量,我们将链表分成:单向链表(上图)、双向链表(节点中有前地址域和后地址域)。再按照首尾节点是否相连,又将其分为:循环链表与非循环链表。那么,我们如何在python中实现链表结构呢?
答案:基于面向对象的思维来构建。我们可将整个链表结构分为两个类:节点类、链表类,在节点类中定义属性:元素域data,地址域next,在链表类中定义属性:链表的头结点head。以一一个单向链表为例,编程如下:
# 定义节点类 SingleNode
class SingleNode:
# 初始化节点的两个属性值:元素域、地址域
def __init__(self,data):
self.data = data
self.next = None
# 定义链表类 SingleLinkedList:
class SingleLinkedList:
# 初始化链表的属性:头结点
def __init__(self,node):
self.head = node
# 测试链表
if __name__ == '__main__':
# 创建两个节点对象
node1 = SingleNode([1,2,3])
node2 = SingleNode([4,5,6])
# 将两个节点连接
node1.next = node2
# 创建链表对象
linked_list = SingleLinkedList(node1)
# 遍历输出,cur代表当前指针变量
cur = linked_list.head
while cur is not None:
print(cur.data)
# 指针迭代
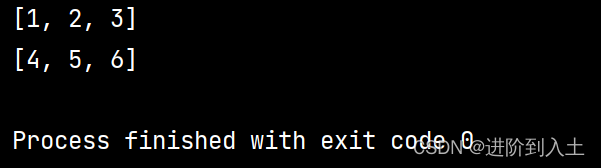
cur = cur.next输出结果,见下图:
根据需求,我们可以对链表中的各节点进行增删改查等操作,相应的方法可以直接写在链表类中,便于我们直接调用操作。由于篇幅有限,接下来只演示删除节点的编码:
# 定义链表类 SingleLinkedList:
class SingleLinkedList:
# 初始化链表的属性:头结点
def __init__(self,node):
self.head = node
# 功能:remove(self, data)删除节点
def remove(self,data):
# 将头节点赋值给变量cur
cur = self.head
# 设置辅助游标
pre = None
# 非空则遍历,获取每个节点
while cur is not None:
# 判断是否为要删除的值
if cur.data == data:
# 判断是否为头节点
if cur == self.head:
self.head = cur.next
else:
pre.next = cur.next
break
else:
pre = cur
cur = cur.next














 888
888











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









