







一、前言
1.1、说明
就MySQL在执行过程、sql执行顺序,以及一些相关关键字的注意点方面的学习分享内容。
在参考文章的基础上,会增加自己的理解、看法,希望本文章能够在您的学习中提供帮助。
如有错误的地方,欢迎指出纠错,互相学习,共同进步。
1.2、参考文章
十分感谢以下文章提供的帮助
https://www.cnblogs.com/wyq178/p/11576065.html
https://juejin.cn/post/7002604517913001997
https://blog.csdn.net/qq_48157004/article/details/128590851
https://cloud.tencent.com/developer/article/1882003
https://cloud.tencent.com/developer/article/1115019
二、MySQL的执行过程
2.1、MySQL数据库架构的两个主要层次
2.1.1、Server层
- 这是 MySQL 的核心,负责管理客户端的连接、SQL 查询处理、权限管理、事务处理、数据字典等。
- Server 层负责接收来自客户端的 SQL 查询,并将它们发送到存储引擎层进行处理。
- 这一层是 MySQL 的核心逻辑,独立于任何特定的存储引擎,因此提供了对不同存储引擎的统一接口。
2.1.2、存储引擎层
- 存储引擎层负责存储和检索数据。MySQL 支持多种存储引擎,每种引擎都有其独特的特性和适用场景。
- 每个表可以根据需求选择不同的存储引擎,甚至在同一数据库中的不同表也可以使用不同的存储引擎。
- 一些常见的 MySQL 存储引擎包括 InnoDB、MyISAM、MEMORY、CSV、ARCHIVE 等。
2.2、MySQL数据库架构图
架构图(具体详情分析可见2.3部分):
在
对存储引擎描述比较详细的一张架构图(可用于参考,本文章的侧重点不在存储引擎,不同的存储引擎内部实现不同)
比较官方的一张架构图

2.3、 各执行过程详情说明
2.3.1 连接器
1、建立和维护连接
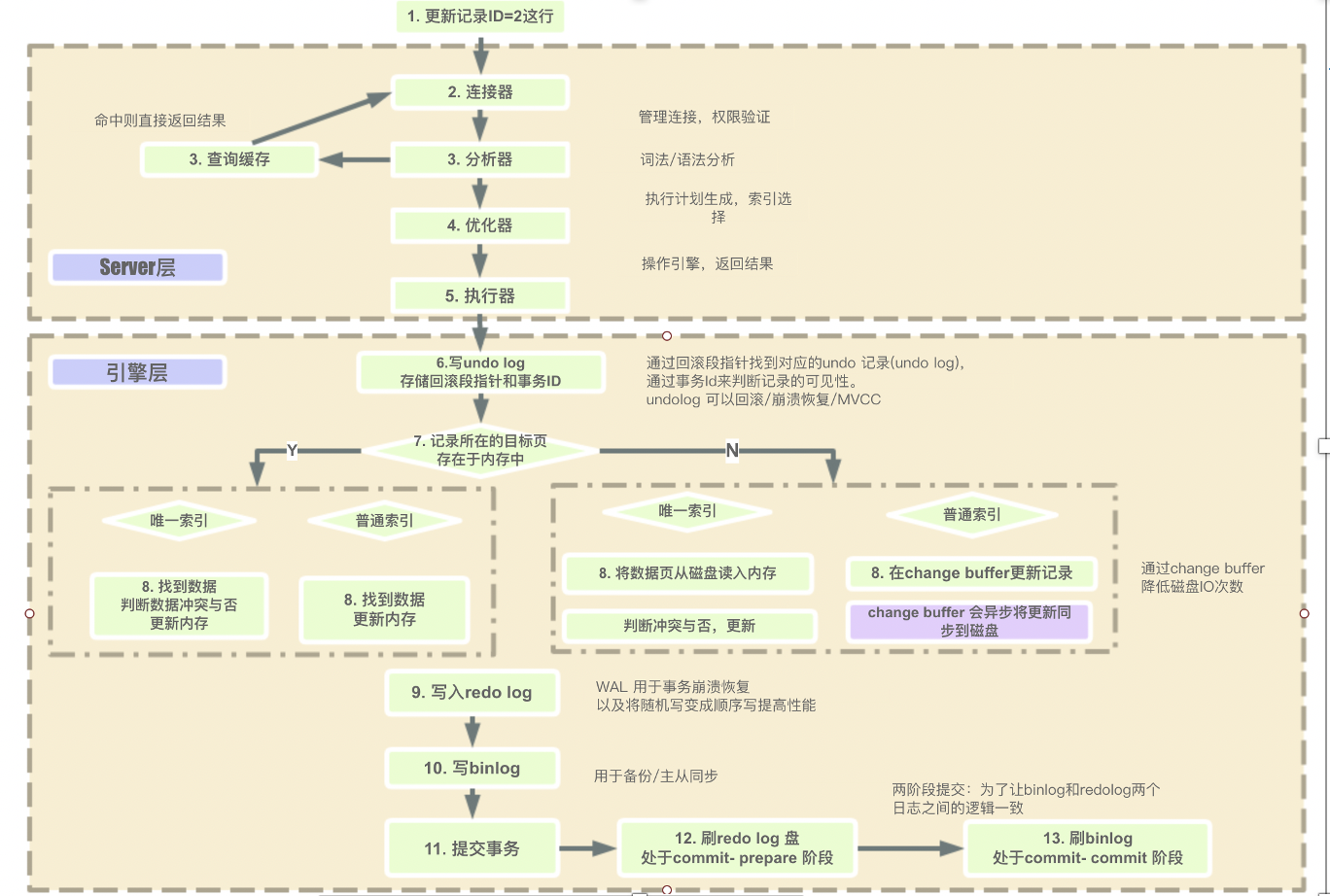
连接器负责与客户端的通信,其使用的是半双工模式(一种通信方式,其中通信双方可以交替地发送和接收数据,但不能同时进行发送和接收)。首先是与访问的客户端建立TCP连接,服务器有专门的TCP连接池,采用长连接模式复用TCP连接,经过三次握手建立连接成功后,之后会对TCP传输过来的账号密码做身份认证、权限获取。在服务器内部,每个client连接都有自己的线程,即TCP连接都会分配给一个线程去执行后续的流程。这些线程轮流运行在某一个CPU内核(多核CPU)或者CPU中,缓存了线程,因此不需要为每个client连接单独创建和销毁线程 。
2、认证和权限获取
完成与访问客户端的TCP连接后,会对TCP传递过来的账号密码进行身份认证,如果账户和密码错误,会报错Access denied for user 'root'@'localhost' (using password: YES)。
如果用户的账户和密码验证通过,会在MySQL自带的权限表中查询当前用户的权限(管理员可以通过GRANT和REVOKE语句来修改用户的权限),MySQL中存在4个控制权限的表,分别为user表,db表,tables_priv表,columns_priv表:
- user表:存放用户账户信息以及全局级别(所有数据库)权限,决定了来自哪些主机的哪些用户可以访问数据库实例
- db表:存放数据库级别的权限,决定了来自哪些主机的哪些用户可以访问此数据库
- tables_priv表:存放表级别的权限,决定了来自哪些主机的哪些用户可以访问数据库的这个表
- columns_priv表:存放列级别的权限,决定了来自哪些主机的哪些用户可以访问数据库表的这个字段
验证授权过程(MySQL会在用户进行操作时,动态地检查其权限信息,以决定是否允许该操作)如下所示:
- 先从user表中的Host,User,Password这3个字段中判断连接的IP、用户名、密码是否存在,存在则通过验证。
- 通过身份认证后,进行权限分配,按照user,db,tables_priv,columns_priv的顺序进行验证。即先检查全局权限表user,如果user中对应的权限为Y,则此用户对所有数据库的权限都为Y,将不再检查db,tables_priv,columns_priv;如果为N,则到db表中检查此用户对应的具体数据库,并得到db中为Y的权限;如果db中为N,则检查tables_priv中此数据库对应的具体表,取得表中的权限Y,以此类推。
- 如果在任何一个过程中权限验证不通过,都会返回相应的错误。
并且MySQL支持多种身份认证方式,包括基于密码的认证、SSL/TLS证书认证等,其中,最常用的是基于密码的认证方式。
2.3.2 缓存
缓存主要是针对MySQL的查询语句进行的,如果是查询语句,MySQL服务器会将查询字符串作为key,查询结果作为value缓存到内存中。经过连接器,此时MySQL服务器已经获得到了SQL字符串,如果是查询语句,服务器会使用该查询字符串作为key,去缓存中获取,如果命中缓存,直接返回结果(返回前需要做权限的验证),未命中则执行后面的逻辑。并且,在匹配的缓存的过程中,查询字符串需要完全与key匹配才算命中(即空格、注释、大小写、某些系统函数)。当所取的数据的基表发生任何数据变化后,MySQL服务器会自动使对应的缓存失效。在读写比例非常高的应用系统中, 缓存对性能的提高是非常显著的。当然它对内存的消耗也是非常大的。从MySQL 5.6的版本中已经默认关闭,5.7.20开始,不推荐使用查询缓存,并在MySQL 8.0中删除。
2.3.3 分析器
因为客户端发送过来的只是一段文本字符串,因此MySQL服务器还需要对该文本字符串进行解析,这个解析过程就是在分析器中完成的。分析器对客户端发过来的SQL语句进行分析,包括预处理与解析过程,在这个阶段会解析SQL语句的语义,并进行关键词和非关键词进行提取、解析,并创建一个内部数据结果(解析树)。具体的关键词包括不限定于以下:select/update/delete/or/in/where/group by/having/count/limit等。如果分析到语法错误,会直接给客户端抛出异常:ERROR:You have an error in your SQL syntax.。除了提取关键词外,还会对其中的表进行校验,如果不存在该表,同样也会报错:unknown column in field list.。通过了分析器,那么就说明客户端发送过来的文本字符串是符合SQL标准语义规则,之后MySQL服务器就要开始执行SQL语句了。
2.3.4 优化器
优化器不仅会生成SQL执行的计划,还会帮助优化SQL语句。如外连接转换为内连接、表达式简化、子查询转为连接、连接顺序、索引选择等一堆东西,优化的结果就是执行计划。MySQL会计算各个执行方法的最佳时间,最终确定一条执行的SQL交给最后的执行器。
2.3.5 执行器
开始执行SQL的时候,要先判断一下对这个表有没有相应的权限,如果没有,就会返回权限错误。如果权限校验通过后,会调用存储引擎的API,API会调用存储引擎(存储引擎API只是抽象接口,下面还有个存储引擎层,具体实现还是要看表选择的存储引擎),主要有以下存储的引擎(常用的还是myisam和innodb):
| 存储引擎 | myisam | innodb | memory | archive |
|---|---|---|---|---|
| 存储限制 | 256TB | 64TB | 有 | 无 |
| 事务 | / | 支持 | / | / |
| 索引 | 支持 | 支持 | 支持 | / |
| 锁的粒度 | 表锁 | 行锁 | 表锁 | 行锁 |
| 数据压缩 | 支持 | / | / | 支持 |
| 外键 | / | 支持 | / | / |
存储引擎,之前又叫表处理器,负责对具体的数据文件进行操作,对SQL的语义比如select或者update进行分析,执行具体的操作。在执行完以后会将具体的操作记录到binlog中,需要注意的一点是:select不会记录到binlog中,只有update/delete/insert才会记录到binlog中。而update会采用两阶段提交的方式,记录都redolog中。
关于binlog和redolog两个日志的说明:
binlog:
- 作用:Binlog记录了对MySQL数据库进行的所有更改操作,例如INSERT、UPDATE、DELETE等,以二进制格式记录在磁盘上。
- 功能:主要用于数据恢复、数据复制和数据迁移。通过分析Binlog,可以重放数据库中的更改操作,从而实现数据的恢复或者将更改操作应用到其他MySQL实例上。
- 使用场景:常用于数据库备份、故障恢复、数据同步等场景。
redolog:
- 作用:Redo Log记录了数据库引擎执行的每个事务的修改操作,以便在数据库发生崩溃时,可以通过重放Redo Log来恢复事务的更改。
- 功能:主要用于保证数据库的持久性和事务的原子性,即使在发生故障时也能确保事务的完整性。
- 使用场景:主要用于崩溃恢复和事务回滚。
三、SQL执行顺序说明
SQL并不是按照我们的书写顺序来从前往后、左往右依次执行的,它是按照固定的顺序解析的,主要的作用就是从上一个阶段的执行返回结果来提供给下一阶段使用,SQL在执行的过程中会有不同的临时中间表,一般是按照如下顺序:
- from
- on
- join
- where
- goup by
- having + 聚合函数
- select
- order by
- limit
在MySQL中,查询语句中子查询的执行顺序可以根据具体情况而有所不同,但一般来说,以下是一个常见的执行顺序:
- 内部子查询:MySQL通常会首先执行子查询,生成临时结果集,然后将其用于外部查询。内部子查询是指嵌套在主查询中的子查询,通常作为主查询的一部分。
- 关联子查询:如果子查询是一个关联子查询(即与外部查询相关联),MySQL可能会根据优化器的策略选择在何处执行子查询。有时候,MySQL可能会将关联子查询转换为连接查询来提高性能。
- 外部查询:一旦子查询的结果可用,MySQL会将其与外部查询组合起来执行,产生最终的结果集。















 67
67











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









