







 本文介绍了Python爬虫中异步下载图片的概念和实现,包括事件循环、协程、任务对象和未来对象的使用。通过aiohttp模块解决了requests不支持异步的问题,展示了多任务异步协程的实现思路和流程,提供了一个下载图片的函数案例。
本文介绍了Python爬虫中异步下载图片的概念和实现,包括事件循环、协程、任务对象和未来对象的使用。通过aiohttp模块解决了requests不支持异步的问题,展示了多任务异步协程的实现思路和流程,提供了一个下载图片的函数案例。
概念
- event_loop:事件循环,也就是通过不断的循环获取任务的状态(完成/未完成)来分配任务。
- coroutine:协程对象,python中万物皆对象,不多说,懂的都懂。
- task:任务对象,对协程对象进行包装,加上了状态,完成和未完成。
- future:和task一样,只不过可以提前包装。
- async:定义一个协程,定义!
- await:挂起阻塞的操作,还记得之前说的IO等待吗,在那前面就要用到这个。
第一个案例
第一步,导入我们的asyncio模块,async+io!!!

第二步,用async定义一个协程,定义!

记住用await挂起阻塞的操作,也就是asyncio.sleep(2),这里是为了模拟下载所需要花费的时间!
awa
第三步,创建一个协程对象,对象,懂的都懂!

第四步,用event_loop创建一个事件循环,也就是游戏里的任务公布栏之类的~

第五步,是不是觉得该把任务对象方法事件循环中了??还真是的!

然后执行,就会成功执行我们的async函数:

第二个案例
那么这个时候就要有人问了,刚开始说的1,2,5,6都用上了,那3,4呢,3,4呢,3,4呢……
这就给大家用上!
task

这里我们就把duixiang这个协程对象放置到task任务对象,然后再把task任务对象放到任务列表中:

那么到这里就有人问了,用task和不用task又没有区别,为什么要用task呢?
我们来打印一下任务完成前后的task!
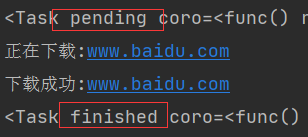
看到没有!!task给每个任务都贴上了标签,让循环器更好的去筛选哪些是完成了的,哪些是没完成的!
future也是一样的,这里就不多说了,我们主要用task。
实现异步下载图片
昨天呢,我们本来是要用异步实现下载图片的,但是遇到了一个小问题,那就是requests模块它不支持异步,那我们也没有办法强人锁男的啦,人各有志,让我们工地见面。
好啦,教大家一个支持异步的同时也支持requests功能的新模块!
aiohttp aiohttp aiohttp aiohttp aiohttp ……
aiohttp
首先,环境安装!
pip install aiohttp
当然你也可以在pycharm里直接搜索安装模块!
安装完了这个模块之后呢&
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 8426
8426











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









